Parameters input_size – The number of expected features in the input x
hidden_size – The number of features in the hidden state h
num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together to form a stacked RNN, with the second RNN taking in outputs of the first RNN and computing the final results. Default: 1 堆叠层数
nonlinearity – The non-linearity to use. Can be either 'tanh' or 'relu'. Default: 'tanh'
bias – If False, then the layer does not use bias weights b_ih and b_hh. Default: True
batch_first – If True, then the input and output tensors are provided as (batch, seq, feature). Default: False
dropout – If non-zero, introduces a Dropout layer on the outputs of each RNN layer except the last layer, with dropout probability equal to dropout. Default: 0
bidirectional – If True, becomes a bidirectional RNN. Default: False 是否使用双向rnn。
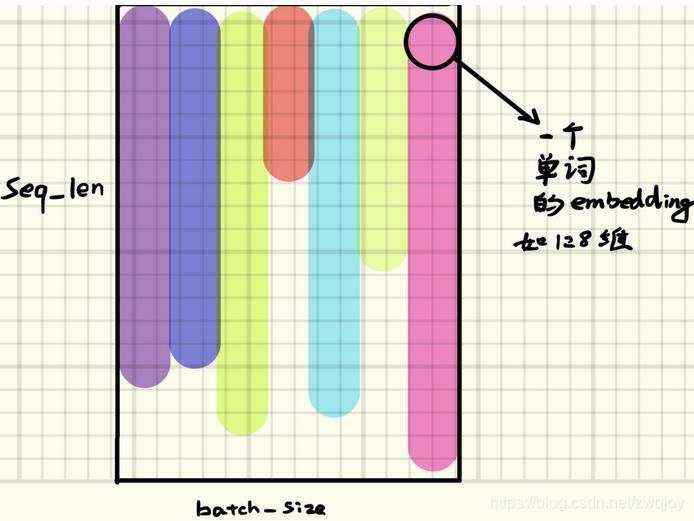
Inputs: input, h_0 input维度 input of shape (seq_len, batch, input_size): tensor containing the features of the input sequence. The input can also be a packed variable length sequence. See torch.nn.utils.rnn.pack_padded_sequence() or torch.nn.utils.rnn.pack_sequence() for details.
h0维度 h_0 of shape (num_layers * num_directions, batch, hidden_size): tensor containing the initial hidden state for each element in the batch. Defaults to zero if not provided. If the RNN is bidirectional, num_directions should be 2, else it should be 1.h0是提供给每层RNN的初始输入,所有num_layers要和RNN的num_layers对得上。
Outputs: output, h_n output of shape (seq_len, batch, num_directions * hidden_size): tensor containing the output features (h_t) from the last layer of the RNN, for each t. If a torch.nn.utils.rnn.PackedSequence has been given as the input, the output will also be a packed sequence.For the unpacked case, the directions can be separated using output.view(seq_len, batch, num_directions, hidden_size), with forward and backward being direction 0 and 1 respectively. Similarly, the directions can be separated in the packed case.RNN的上侧输出。
h_n of shape (num_layers * num_directions, batch, hidden_size): tensor containing the hidden state for t = seq_len.Like output, the layers can be separated using h_n.view(num_layers, num_directions, batch, hidden_size).RNN的右侧输出,如果是双向的话,就还有一个左侧输出。




 京公网安备 11010802041100号
京公网安备 11010802041100号