

前言
随着科技的不断发展,人工智能得到了极大的进步,用户可以在旧计算机系统中运行人工智能程序,而无需更改底层硬件基础架构。同时,机器学习的优点是无限的,NLP(自然语言处理)是AI的分支之一,它使机器能够阅读,理解和传递含义。NLP在医疗保健,媒体,金融和人力资源等方面已经取得了巨大的成功。
非结构化数据的最常见形式是文本和语音,它们包含有丰富的内容但很难从中提取有用的信息,经常需要很长时间来挖掘信息。书面文字和语音包含丰富的信息,这是因为我们作为聪明的生物,将写作和口语作为交流的主要形式。NLP可以为我们分析这些数据,并执行情感分析,认知助手,跨度过滤,识别假新闻和实时语言翻译等任务。
本文将介绍NLP如何理解文本或词性,主要是分析单词和序列分析。理解过程包括文本分类,矢量语义和单词嵌入,概率语言模型,顺序标记和语音重组。我们将研究五万名IMDB电影评论员的情绪分析,为的是确定用户在IMDB网站上发布的评论是正面的还是负面的。
NLP已全面融入当今社会
NLP已广泛用于汽车,智能手机,扬声器,计算机,网站等领域。例如著名的Google Translator使用的机器翻译器也是NLP系统。GoogleTranslator会写和说自然语言,以期望用户希望翻译的语言。NLP帮助Google翻译人员理解上下文中的单词,消除多余的噪音,并构建CNN来理解本地语音。
NLP在聊天机器人中也很流行。我们在日常生活中遇到的聊天机器人非常有用,因为它减少了询问客户需求的人工工作。NLPchatbot可以询问一系列问题,例如用户问题是什么以及在哪里找到解决方案。Apple和AMAZON在其系统中都有一个强大的聊天机器人。当用户提出一些问题时,聊天机器人会将其转换为内部系统中可理解的短语。
NLP用于信息检索(IR)。IR是一个软件程序,用于处理大型存储,评估来自存储库的大型文本文档中的信息。它将仅检索相关信息。例如,它在Google语音检测中用于修剪不必要的单词。
NLP的应用
机器翻译,即Google翻译
信息检索
问题回答即ChatBot
总结
情绪分析
社交媒体分析
挖掘大数据
单词和序列
NLP系统需要正确理解文本,符号和语义。许多方法可以帮助NLP系统理解文本和符号。它们是文本分类、向量语义、单词嵌入、概率语言模型、序列标签和语音重组。
1. 文字分类
文本澄清是将文本分类为一组单词的过程。通过使用NLP,文本分类可以自动分析文本,然后根据其上下文分配一组预定义标签或类别。NLP用于情感分析,主题检测和语言检测。主要有三种文本分类方法-
o 基于规则的系统
o 机器系统
o 混合动力系统。
在基于规则的方法中,使用一组语言规则将文本分为一个有组织的组。这些语言规则包含用户定义一组词的列表。例如,唐纳德·特朗普(DonaldTrump)和鲍里斯·约翰逊(BorisJohnson)等词将被归类为政治。像勒布朗·詹姆斯和罗纳尔多这样的人将被归类为体育运动。
基于机器的分类器学习基于对数据集的过去观察进行分类。用户数据已预先标记为tarin和测试数据。它从先前的输入中收集分类策略并不断学习。基于机器的分类器用法是一词包,用于功能扩展。
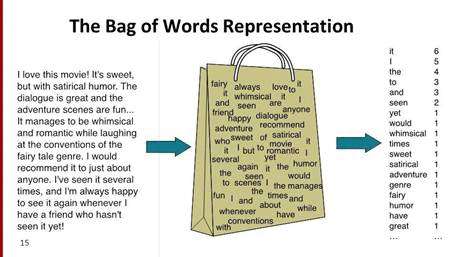
在单词袋中,向量表示单词列表的预定义词典中单词的频率。我们可以使用以下机器学习算法来执行NLP:朴素的拜耳,SVM和深度学习。
文本分类的第三种方法是混合方法。混合方法的用法结合了基于规则和基于机器的方法。基于混合的方法使用基于规则的系统来创建标签,并使用机器学习来训练系统并创建规则。然后,将基于计算机的规则列表与基于规则的规则列表进行比较。如果标签上的某些内容不匹配,则会人工改进列表。这是实现文本分类的最佳方法。
2. 向量语义
向量语义是单词和序列分析的另一种方法。向量语义定义了语义并解释了词的含义,以解释诸如相似词和相反词之类的特征。向量语义背后的主要思想是两个词在相似的上下文中使用时是相似的。向量语义将单词划分在多维向量空间中。向量语义在情感分析中很有用。
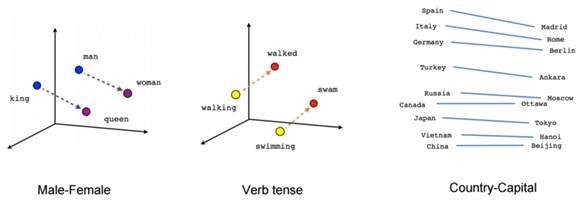
3. 词嵌入
词嵌入是词和序列分析的另一种方法。嵌入将备用向量转换为保留语义关系的低维空间。词嵌入是一种词表示形式,它允许具有相似含义的词具有类似的表示形式。词嵌入有两种类型:
o Word2vec
o Doc2Vec。
Word2Vec是一种统计方法,可以有效地学习从文本语料库中嵌入的独立单词。
Doc2Vec与Doc2Vec相似,但是它分析一组文本,如页面。
4. 概率语言模型
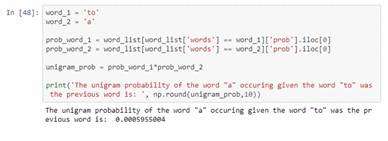
单词和序列分析的另一种方法是概率语言模型。概率语言模型的目标是计算单词序列中句子的概率。例如,单词“a”出现在给定单词“ to”中的概率为0.00013131%。
5. 序列标记
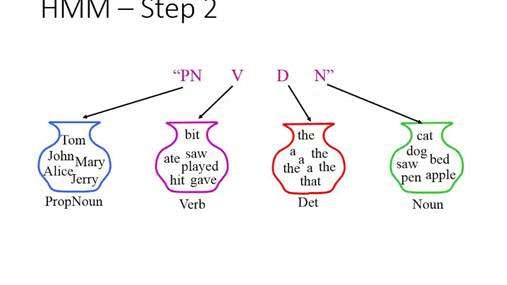
序列标签是典型的NLP任务,它为给定输入序列中的每个标记分配一个类或标签。如果有人说“通过汤姆·汉克斯播放电影”。按顺序,标签将为[播放,电影,汤姆·汉克斯]。游戏决定了一个动作。电影是行动的一个实例。汤姆·汉克斯(Tom Hanks)寻找一个搜索实体。它将输入分为多个标记,并使用LSTM对其进行分析。序列标记有两种形式。它们是标记标记和跨度标记。
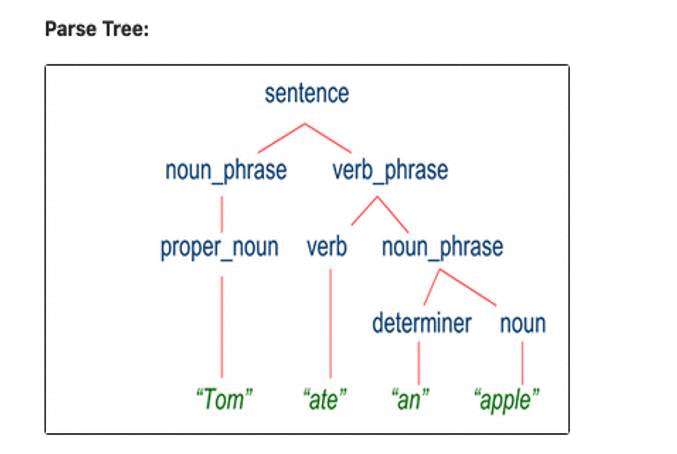
解析是NLP的一个阶段,其中解析器通过根据基础语法分析文本的组成词来确定文本的句法结构。例如,“tom ate a apple”将被分为专有名词àtom,动词ate,确定者à和名词àapple。最好的例子是亚马逊Alexa。
我们讨论了如何对文本进行分类以及如何对单词和序列进行划分,以便算法可以理解和分类文本。在这个项目中,我们将发现对五万名IMDB电影评论员的情感分析。我们的目标是确定用户在IMDB网站上发布的评论是正面的还是负面的。
该项目涉及文本挖掘技术,例如文本嵌入,单词袋,单词上下文和其他内容。我们还将介绍双向LSTM情感分类器的介绍。我们还将研究如何从TensorFlow自动导入标记的数据集。该项目还涵盖数据清理,文本处理,通过采样进行数据平衡以及训练和测试深度学习模型以对文本进行分类等步骤。
解析器
解析器通过基于基础语法分析文本的组成词来确定文本的句法结构。它将组词划分为多个组成部分,并将各个词分开。
语义
文字是我们沟通方式的核心。理解书面或口头谈话的内容是真正困难的事情吗?了解冗长的文章和书籍更加困难。语义是通过构建说话人用来传达含义的原理模型来寻求理解语言含义的过程。它已用于客户反馈分析,文章分析,假新闻检测,语义分析等。
应用范例
导入必要的库
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
#Importing require Libraries
import os
import matplotlib.pyplot as plt
import nltk
from tkinter import *
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
import scipy
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
from tensorflow.python import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
Downloading necessary file
# this cells takes time, please run once
# Split the training set into 60% and 40%, so we'll end up with 15,000 examples
# for training, 10,000 examples for validation and 25,000 examples for testing.
original_train_data, original_validation_data, original_test_data = tfds.load(
name="imdb_reviews",
split=('train[:60%]', 'train[60%:]', 'test'),
as_supervised=True)
(左右滑动看完整代码~)
下载必要文件
# this cells takes time, please run once
# Split the training set into 60% and 40%, so we'll end up with 15,000 examples
# for training, 10,000 examples for validation and 25,000 examples for testing.
original_train_data, original_validation_data, original_test_data = tfds.load(
name="imdb_reviews",
split=('train[:60%]', 'train[60%:]', 'test'),
as_supervised=True)
从Keras数据集中获取单词索引
#tokanizing by tensorflow
word_index = tf.keras.datasets.imdb.get_word_index(
path='imdb_word_index.json'
)
在[8]中:
{k:v for (k,v) in word_index.items() if v < 20}
出[8]:
{'with': 16, 'i': 10, 'as': 14, 'it': 9, 'is': 6, 'in': 8, 'but': 18, 'of': 4, 'this': 11, 'a': 3, 'for': 15, 'br': 7, 'the': 1, 'was': 13, 'and': 2, 'to': 5, 'film': 19, 'movie': 17, 'that': 12}
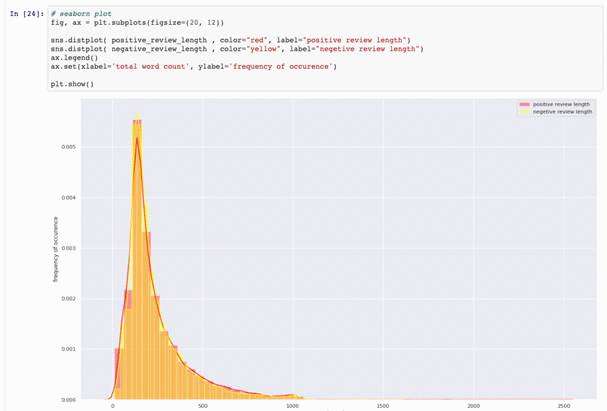
正面和负面评论比较
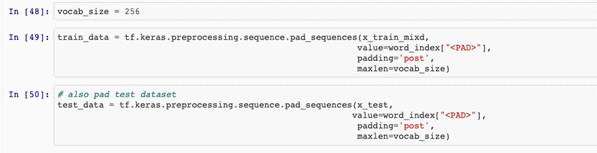
创建训练,测试数据
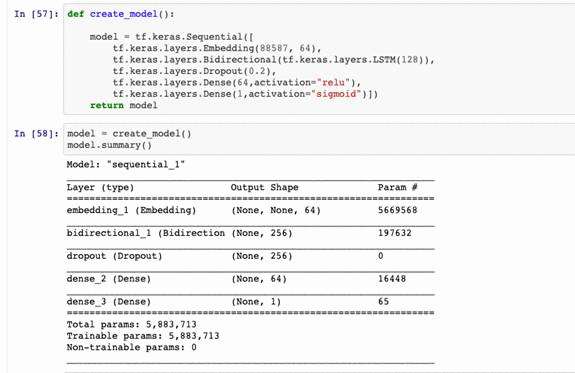
模型和模型摘要
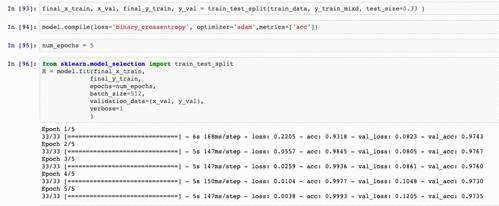
分割数据并拟合模型
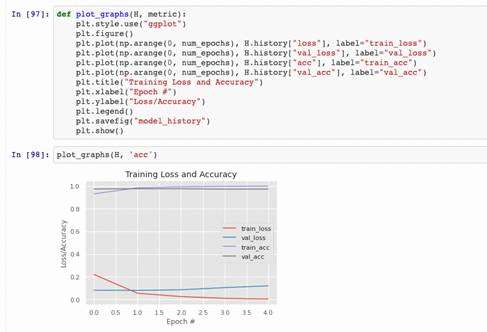
模型效果概述
混淆矩阵和相关报告
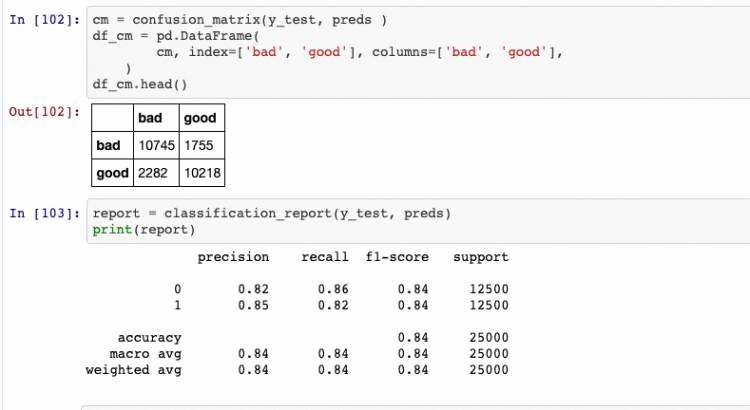
总之,自然语言处理是一个充满机遇的领域。NLP对如何分析文本和语音具有巨大影响。NLP相关技术在逐渐做得越来越好,例如五年前就不可能从大数据集中提取知识,但现在NLP技术的兴起使其成为可能且容易。
欢迎留言和我们讨论NLP的问题~

本文作者



指导老师

长按二维码关注我们~

长按二维码关注沈浩老师~











 京公网安备 11010802041100号
京公网安备 11010802041100号