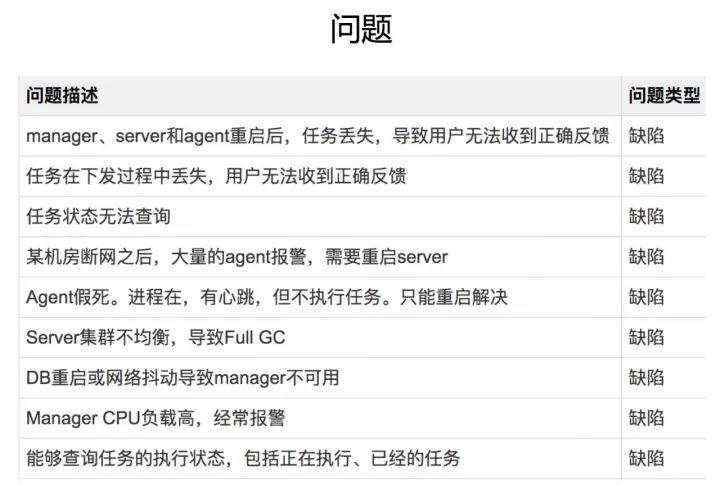
如上图:是我们前年在做系统重构时遇到的问题:
前三个问题有点类似,主要是任务由状态导致,1.0的manager可以理解为2.0中的proxy,server等同于channel,每时每刻线上都有大量系统在下发命令,在1.0中如果把manager/server/agent任何一个角色重启,那么在这条链路上的任务都会失败,比如server重启后与它相连的agent都会断开,因为链路断了,当时经过这台server下发的命令就拿不到结果了。重启server又会引发第六个负载不均的问题,假设一个IDC中有一万台机器,两台server各连了5000台,重启后这一万台就全连到了一台server上。
用户如果调用API下发命令失败就会找过来让我们查原因,有的时候确实是系统的问题,但也有很多是本身的环境问题,比如机器宕机、SSH不通、负载高、磁盘满等等,百万级规模的服务器,每天百分之一的机器也有一万台,由此带来的答疑量可想而知。当时我们非常痛苦,团队每天一半的人员在做答疑,半夜有断网演练还需要爬起来去重启服务来恢复。

面对这些问题如何解决呢?我们将问题分为系统问题和环境问题两大类。
系统问题
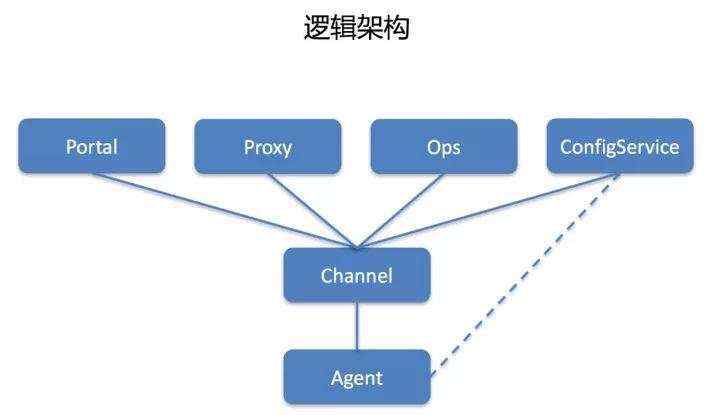
我们把系统做了一次彻底的重构,采用分布式消息架构,还是以下发命令为例,每次下发是一次任务,在2.0中对每个任务增加了状态,proxy在收到下发命令请求后,会先记录并把状态置为收到任务,然后再向agent下发,agent收到任务后会立即响应,proxy收到agent的响应后会把状态置为执行中,agent执行完成后主动上报结果,proxy收到结果后再把状态置为执行完成。
整个过程中proxy与agent之间的消息都有确认机制,没有得到确认就会进行重试,这样任务执行过程中涉及角色如果重启,对任务本身就没有太大影响了。
2.0中channel集群内的机器之间会互相通信,定期报告自己连的agent数量等信息,结合收到的信息与自己的信息,如果自己连的agent过多,会自动断开近期无任务执行的机器,通过这样的方式解决负载均衡的问题。中心节点与所有channel都有长连接,同时保存有每台channel连接的agent数量,当发现某个机房有channel异常或者容量过高时,会自动触发扩容或者从其它机房临时借调channel,在容量恢复后又会自动剔除扩容的channel。
环境问题
在2.0中proxy/channel/agent每一层都有详细的错误码,通过错误码可以直观判断是什么原因导致的任务出错。
针对机器本身的问题,与监控系统中的数据打通,任务失败后会触发环境检查,包括宕机、磁盘空间、负载等,如果有相应问题API会直接返回机器有问题,并且把机器的负责人也一并返回,这样用户一看结果就知道什么原因该找谁处理。同时还会把这些诊断能力用钉钉机器人的方式开放出来,这样大家平时可以直接在群里@机器人来做检查确认。
稳定
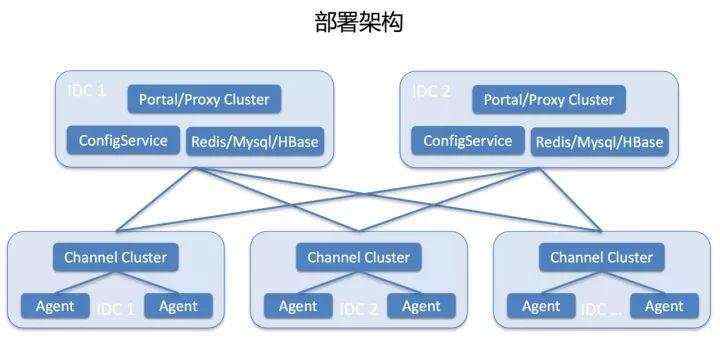
通过前面的介绍可以看到我们其实是运维的基础设施,就像生活中的水电煤一样,大家所有对服务器的操作强依赖我们。当我们出现故障的时候,如果线上业务也出现了严重故障,这时候业务故障只能干等着,因为操作不了服务器,做不了发布和变更,所以对系统稳定性的要求非常高,做到了同城双机房、异地多中心容灾部署,依赖的存储有mysql/redis/hbase,这些存储本身就有高可用保障,在这个之上我们又做了存储间的冗余,确保任何一个单一存储故障不会影响到业务,相信整个业内很少有系统会做到这个程度。
安全
1分钟可以操作50万台服务器,输入命令敲回车就这么一瞬间,就可以操作数万台机器,如果是个恶意的破坏性操作,影响可想而知。所以做了高危命令阻断的功能,对于一些高危操作自动识别与拦截。整个调用链路也是经过加密与签名,确保第三方无法破解或篡改。针对API账号可能存在的泄露问题,还开发了命令映射的功能,把操作系统中的命令用映射的方式改掉,比如执行reboot命令,可能要传入a1b2才行,每个API账号的映射关系都是不一样的。
环境
机器宕机这类环境问题,通过与监控数据打通解决,前面已经讲过,网络隔离的问题也不再过多陈述。这里重点说明下CMDB中录入的数据与Agent采集的数据不一致的问题,主要是SN、IP这些基础信息,因为大家在使用的时候都是先从CMDB取出机器信息,再来调用我们的系统,如果不一致就会导致调用直接失败,为什么会出现SN/IP不一致的问题?
CMDB中的数据一般由人工或者其它系统触发录入,而Agent是从机器上真实采集的,有的机器主板没烧录SN、有的机器有很多块网卡等,环境比较复杂各种情况都有。
这种情况就是通过建立规范来解决,分别制定SN、IP采集规范,允许机器上自定义机器的SN/IP,配合规范还提供有采集工具,不仅是我们的Agent,所有其它采集机器信息的场景都可以使用这个采集工具,当规范发生更新时我们会同步更新小工具,以此实现对上层业务的透明化。









 京公网安备 11010802041100号
京公网安备 11010802041100号