| Examples | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB |
| 典型应用场景 | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 |
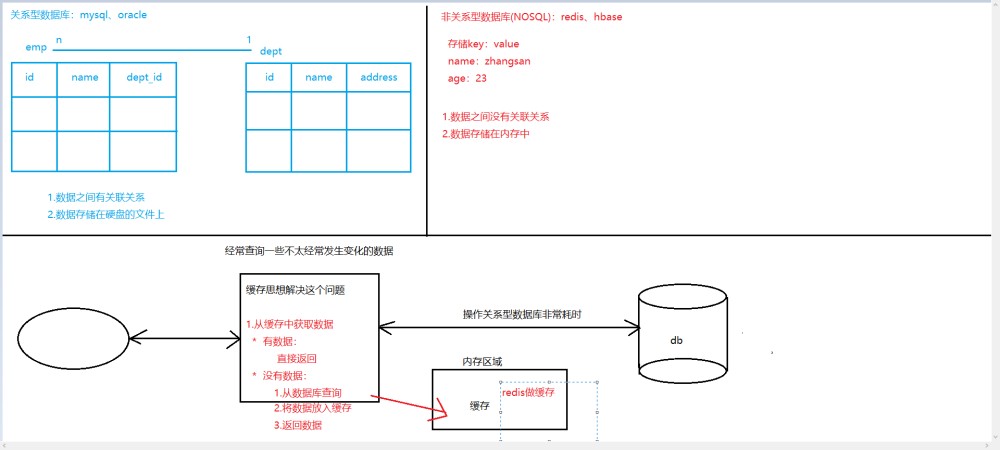
| 数据模型 | Key 指向 Value 的键值对,通常用hash table来实现 |
| 强项 | 查找速度快 |
| 弱项 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| Examples | Cassandra, HBase, Riak |
| 典型应用场景 | 分布式的文件系统 |
| 数据模型 | 以列簇式存储,将同一列数据存在一起 |
| 强项 | 查找速度快,可扩展性强,更容易进行分布式扩展 |
| 弱项 | 功能相对局限 |
| Examples | CouchDB, MongoDb |
| 典型应用场景 | Web应用(与Key-Value类似,Value是结构化的,但数据库能够了解Value的内容) |
| 数据模型 | Key-Value对应的键值对,Value为结构化数据 |
| 强项 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 |
| 弱项 | 查询性能不高,而且缺乏统一的查询语法。 |
| Examples | Neo4J, InfoGrid, Infinite Graph |
| 典型应用场景 | 社交网络,推荐系统等。专注于构建关系图谱 |
| 数据模型 | 图结构 |
| 强项 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 |
| 弱项 | 很多时候需要对整个图做计算才能得出需要的信息,不利于分布式的集群方案。 |
| NoSQL | Storage should be able to deal with very high load You do many write operations on the storage You want storage that is horizontally scalable Simplicity is good, as in a very simple query language (without joins) |
| RDBMS | Storage is expected to be high-load, too, but it mainly consists of read operations You want to performance over a more sophisticated data structure You need powerful SQL query language |
原文链接:The top five most powerful Hadoop projects
1.Cascading:Cascading是基于Hadoop集群之上的数据处理API。它通过实现了丰富的功能化API,使你不需要接触MapReduce任务就能使用分布式计算能力,其核心概念是基于管道和流的数据处理。
2.Mahout:Mahout是一个基于Hadoop实现各种机器学习与数据挖掘算法库。被用来提供推荐服务。
3.Hive:Hive由Facebook出品,它为Hadoop提供了一种类似于SQL的操作接口。
4.Avro:Avro是一个基于二进制数据传输高性能的中间件。Avro通过将数据进入序列化,以使得大批量数据交互过程更方便。
5.Storm:Storm由BackType Technology出口,其口号是“实时的Hadoop系统”。
原文链接:Picking the Right NoSQL Database Tool
翻译来源:http://lipengyu.com/database/choice-nosql/




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有