参考文献: A Global Linear Method for Camera Pose Registration Global Structure-from-Motion by Similarity Averaging Linear Global Translation Estimation from Feature Tracks Shapefit and Shapekick for Robust, Scalable Structure from Motion Optimizing the Viewing Graph for Structure-from-Motion Robust Camera Location Estimation by Convex Programming Robust Global Translations with 1DSfM Very Large-Scale Global SfM by Distributed Motion Averagin
参考文献: Adaptive Structure from Motion with a contrario model estimation Batched Incremental Structure-from-Motion Modeling the World from Internet Photo Collections Photo Tourism- Exploring Photo Collections in 3D Progressive Large-Scale Structure-from-Motion with Orthogonal MSTs Structure-from-Motion Revisited Towards linear-time incremental structure from motion
分层式SFM
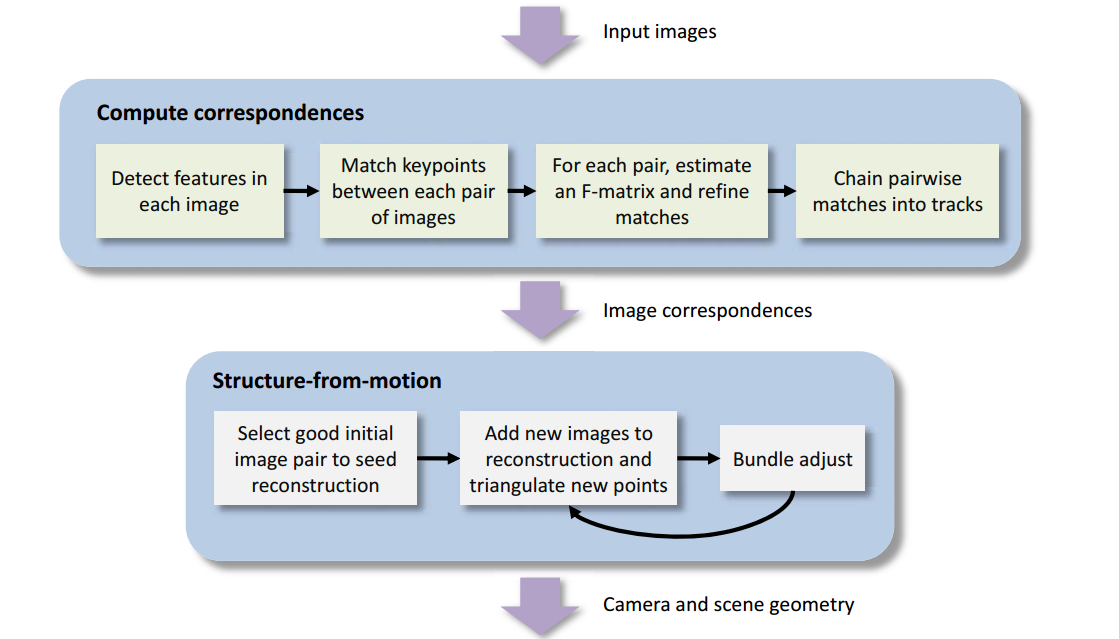
随着三维处理数据量呈指数式的爆发,对于动辄几万、几十万张的数据量,传统的全局式SFM已经很难满足人们对于数据处理要求,我们迫切的需要寻求一种可以快速进行大批量数据处理的稀疏重建方法,因而分层式SFM应运而生。 该方法的主要思想很简单,就是对传统增量式SFM的改进,针对传统增量式SFM处理速度同数据量呈线性相关的特点,提出了针对大规模数据集分而治之的处理思想,即首先对原数据集进行划分,获得N个相互关联的子图,然后对个子图进行并行的增量式SFM处理(Local SFM),处理完毕后,对各子图进行合并,获取当前数据的最终处理结果。 该方法的优点是显而易见的,即提升了大规模数据的处理效率,但,另一方面,该方法也存在很多缺点,首当其冲的便是不够稳健,目前大多数的算法都是在子图重建成功的假设上进行后续处理的,没有考虑,一旦处理失败,应该如何处理,同时,必须仔细的考虑图割算法的选择,因为此方法,直接关系着后续局部SFM的重建成功与否;最后子图合并过程中,锚节点的选择也是十分重要的,如果选择错误,很容易出现漂移危险。 参考文献: Efficient large-scale structure from motion using graph partitioning Improving the efficiency of hierarchical structure-and-motion. Structure-and-motion pipeline on a hierarchical cluster tree. Hierarchical structure-and-motion recovery from uncalibrated images.
混合式SFM
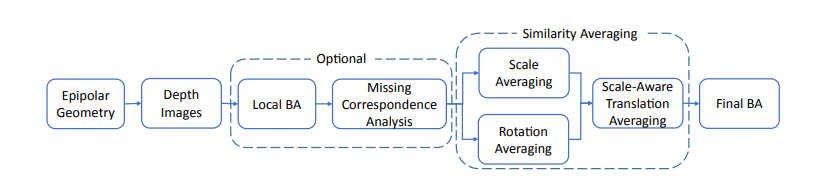
混合式SFM,顾名思义,该处理方式结合了上述处理方式的优点所提出的,该方法处理流程大致如下: 实现进行子图分割,获得N组相互关联的子图,之后对各子图分别采用增量式或者全局式sfm处理,获取其全局旋转信息,然后不进行BA,直接进行后续步骤,使用全局式或者增量式SFM对上一步所获得信息进行处理,获取影像的全局平移信息。 坦率地讲,本人对该方法的研究很浅,因而,对其优缺点的表述也不是十分深刻,因而略过。 参考文献: HSfM Hybrid Structure-from-Motion. Parallel Structure from Motion from Local Increment to Global Averaging Multistage SFM: A Coarse-to-Fine Approach for 3D Reconstructio
Explore how Matterverse is redefining the metaverse experience, creating immersive and meaningful virtual environments that foster genuine connections and economic opportunities. ...
[详细]










 京公网安备 11010802041100号
京公网安备 11010802041100号