java基础教程栏目今天详细介绍有关RocketMQ知识。
图片来自gitee.com/mirrors/roc…
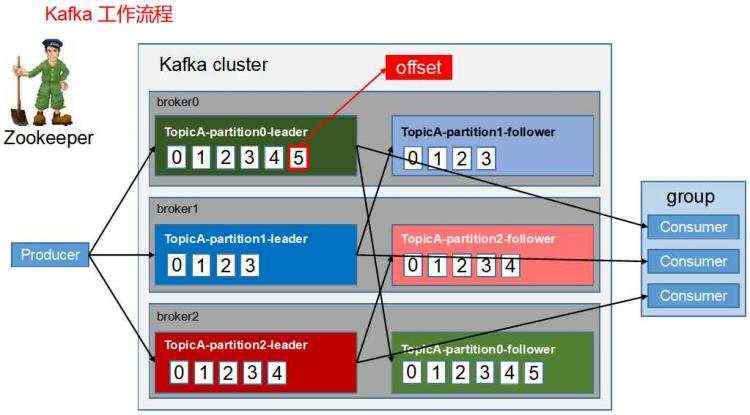
可以看到RocketMQ主要有四个组件:
生产者,每隔一定时间向NameServer发起Topic的路由信息查询。
消费者,每隔一定时间向NameServer发起Topic的路由信息查询。
其实,在低版本的RocketMQ中,确实是选用Zookeeper作为注册中心的,但是后面改成了现在的NameServer,猜想主要原因是:
分为ProducerGroup,ConsumerGroup,我们更多的是关注ConsumerGroup,ConsumerGroup包含多个Consumer。
在集群消费模式下,一个ConsumerGroup下的Consumer共同消费一个Topic,且每个Consumer会被分配到N个队列,但是一个队列只会被一个Consumer消费,不同的ConsumerGroup可以消费同一个Topic,一条消息会被订阅此Topic的所有ConsumerGroup消费。
消费模式有两种:Clustering(集群消费)和Broadcasting(广播消费)。
和其他MQ不同,其他MQ是在发送消息的时候,指定是集群消费还是广播消费,RocketMQ是在消费者端设置是集群消费还是广播消费。
默认情况下是集群消费模式,该模式下,ConsumerGroup所有的Consumer共同消费一个Topic的消息,每个Consumer负责消费N个队列的消息(N也可能为1,甚至是0,没有分配到队列),但是一个队列只会被一个Consumer消费。如果某个Consumer挂掉,ConsumerGroup下的其他Consumer会接替挂掉的Consumer继续消费。
集群消费模式下,消费进度维护在Borker端,存储路径为${ROCKET_HOME}/store/config/ consumerOffset.json,如下图所示:使用topicName@consumerGroupName为Key,消费进度为Value,Value的形式是queueId:offset ,说明如果有多个ConsumerGroup,每个ConsumerGroup的消费进度是不同的,需要分开来存储。
广播消费消息会发给ConsumerGroup中所有的Consumer。
广播消费模式下,消费进度维护在Consumer端。
我们知道了在集群消费模式下,ConsumerGroup下所有的Consumer共同消费一个Topic的消息,每个Consumer负责消费N个队列的消息,那么具体是如何分配的呢?这就涉及到消费队列负载算法了。
RocketMQ提供了众多的消费队列负载算法,其中最常用的是两种算法,即AllocateMessageQueueAveragely、AllocateMessageQueueAveragelyByCircle。下面我们来看下这两个算法的区别。
假设,现在一个Topic有16个队列,用q0~q15表示,有3个Consumer,用c0-c2表示。
用AllocateMessageQueueAveragely消费队列负载算法的结果如下:
用AllocateMessageQueueAveragelyByCircle消费队列负载算法的结果如下:
ConsumerGroup下所有的Consumer共同消费一个Topic的消息,每个Consumer负责消费N个队列的消息,但是一个队列不能同时被N个Consumer消费,这意味着什么?
聪明的你一定可以想到,如果一个Topic只有4个队列,而有5个Consumer,那么有一个Consumer将不能分配到任何队列,所以在RocketMQ中,Topic下队列的个数直接决定了Consumer的最大个数,也就说明,不能光靠增加Consumer来提高消费速度。
虽然建议在创建Topic的时候,就应该充分考虑队列的个数,但是实际情况往往是不尽人意的,哪怕队列数没有发生改变,Consumer的数量也一定会发生改变,比如Consumer的上下线,比如某个Consumer挂了,比如新增了Consumer。队列的扩容、缩容,Consumer的扩容、缩容都会导致重平衡,也就是为Consumer重新分配消费的队列。
在RocketMQ中,Consumer会定时查询Topic的队列的个数,Consumer的个数,如果发生了改变,就会触发重平衡。
重平衡是RocketMQ内部实现的,程序员无需关心。
一般来说,MQ有两种方法获取消息:
不管是Pull,还是Push,Consumer总会与Broker产生交互,交互的方式一般有短连接、长连接、轮询三种方式。
看起来,RocketMQ支持既支持Pull,也支持Push,但是实际上Push也是用Pull实现的,那么Consumer是怎么与Broker产生交互的呢?
这就是RocketMQ设计的巧妙的地方了,既不是短连接,也不是长连接,也不是轮询,而是采用的长轮询。
Consumer发起拉取消息的请求,分为两种情况:
RocketMQ支持事务消息,Producer把事务消息发送给Broker后,Broker会把消息存储在系统Topic:RMQ_SYS_TRANS_HALF_TOPIC,这样Consumer就无法消费到这条消息了。
Broker会有一个定时任务,消费RMQ_SYS_TRANS_HALF_TOPIC的消息,向Producer发起回查,回查的状态有三种:提交、回滚、未知。
延迟消息是指息发到Broker后,不能立刻被Consumer消费,需要等待一定的时间才可以被消费到,RocketMQ只支持特定的延迟时间:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h。
RocketMQ支持两种消费形式:并发消费、顺序消费。 如果是顺序消费,需要保证排序的消息在同一个队列。如何选择队列发送呢,RocketMQ发送消息的方法有好几个重载,其中有一个重载方法支持队列的选择。
Producer把消息发送到Borker中,Borker是需要把消息持久化的,RocketMQ支持两种持久化策略:
为了MQ的可靠性、可用性,在生产环境,一般会部署Follower节点,Follower节点会复制Master的数据,RocketMQ支持两种持复制策略:
"写入"是写入PageCache,还是写入硬盘,要看Follower Broker的配置。
RocketMQ提供了三种发送消息的方法:
在实际开发中,一般选用同步方法,如果要提高RocketMQ的性能,一般都是修改Borker端的参数,特别是刷盘策略和复制策略。
消息发送时,如果使用了MessageQueueSelector,那消息发送的重试机制将会失效。
发送消息响应可能为以下四种:
public enum SendStatus {
SEND_OK,
FLUSH_DISK_TIMEOUT,
FLUSH_SLAVE_TIMEOUT,
SLAVE_NOT_AVAILABLE,
}除了第一种,其他情况都是有问题的,为了保证消息不丢失,需要设置Producer参数:RetryAnotherBrokerWhenNotStoreOK为true。
如果消息发送失败了,重试的时候,还是发送给这个Borker,那么大概率发送还是失败的,RockteMQ设计精巧之处在于,重试的时候,会自动避开这个Borker,而选择其他Borker,但是目前为止,异步发送没有那么智能,只会在一个Borker上重试,所以强烈建议选择同步发送方式。
RocketMQ提供了两种故障规避机制。用参数SendLatencyFaultEnable来控制。
延迟退避机制看起来很好用,但是一般来说Borker端繁忙,导致Borker不可用或者网络不可用只是一瞬间的事情,马上就可以恢复,如果开启了延迟退避机制,本来可用的Borker在一段时间内却被规避了,其他Borker更加繁忙,那可能情况更糟糕。
Consumer有两个参数,可以消费的并行度,即ConsumeThreadMin、ConsumeThreadMax,看起来给人的感觉是,如果Consumer端堆积消息比较少,消费线程数为ConsumeThreadMin;如果Consumer端堆积消息比较多,就自动开启新的线程来消费,直到消费线程数为ConsumeThreadMax。但是并不是这样,Consumer内部持有一个线程池,选用的是无界队列,也就是ConsumeThreadMax参数是无效的,所以在实际开发中,ConsumeThreadMin、ConsumeThreadMax往往设置成一样。
如果查询不到消费进度的时候,Consumer从哪里开始消费,RocketMQ支持从最新消息、最早消息、指定时间戳这三种方式进行消费。
RocketMQ会为每个ConsumerGroup都设置一个Topic名称为%RETRY%+consumerGroup的重试队列,用来保存需要给ConsumerGroup重试的消息,但是重试需要一定的延时时间,RocketMQ对于重试消息的处理是先保存至Topic名称为SCHEDULE_TOPIC_XXXX的延迟队列中,后台定时任务按照对应的时间进行Delay后重新保存至%RETRY%+consumerGroup的重试队列中。
本来以为写扫盲文,应该会写的很顺,但是还是想多了,因为是扫盲文,面向的是没有怎么接触过RocketMQ的小伙伴,但是RocketMQ有没有那么简单,不可能用一篇博客,就让没有怎么接触过RocketMQ的小伙伴顺利入门,所以在写博客的时候,一直在想,这个东西重要吗,需要仔细描述吗;这个东西可以忽视,可以不介绍吗 等等,大家可以看到本文基本都是在介绍各种概念,几乎没有涉及到API的层面,因为一旦涉及到API,那么估计写两个星期也写不完。
相关免费学习推荐:java基础教程
以上就是终于来了...RocketMQ扫盲篇的详细内容,更多请关注其它相关文章!




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有