感谢阿里云 Blink 团队Danny Chan的投稿及完善Flink与Hudi集成工作。
1. 背景
Apache Hudi 是目前最流行的数据湖解决方案之一,Data Lake Analytics 集成了 Hudi 服务高效的数据 MERGE(UPDATE/DELETE)场景;AWS 在 EMR 服务中 预安装 了 Apache Hudi,为用户提供高效的 record-level updates/deletes 和高效的数据查询管理;Uber 已经稳定运行 Apache Hudi 服务 4 年多,提供了 低延迟的数据库同步和高效率的查询。自 2016 年 8 月上线以来,数据湖存储规模已经超过 100PB。
Apache Flink 作为目前最流行的流计算框架,在流式计算场景有天然的优势,当前,Flink 社区也在积极拥抱 Hudi 社区,发挥自身 streaming 写/读的优势,同时也对 batch 的读写做了支持。
Hudi 和 Fink 在 0.8.0 版本做了大量的集成工作。核心的功能包括:
- 实现了新的 Flink streaming writer
- 支持 batch 和 streaming 模式 reader
- 支持 Flink SQL API
Flink streaming writer 通过 state 实现了高效的 index 方案,同时 Hudi 在 UPDATE/DELETE 上的优秀设计使得 Flink Hudi 成为当前最有潜力的 CDC 数据入湖方案,因为篇幅关系,将在后续的文章中介绍。
本文用 Flink SQL Client 来简单的演示通过 Flink SQL API 的方式实现 Hudi 表的操作,包括 batch 模式的读写和 streaming 模式的读。
2. 环境准备
本文使用 Flink Sql Client 作为演示工具,SQL CLI 可以比较方便地执行 SQL 的交互操作。
2.1 下载 Flink jar
Hudi 集成了 Flink 的 1.11 版本。您可以参考 这里 来设置 Flink 环境。hudi-flink-bundle jar 是一个集成了 Flink 相关的 jar 的 uber jar, 目前推荐使用 scala 2.11 来编译。
2.2 设置 Flink 集群
启动一个 standalone 的 Flink 集群。 启动之前,建议将 Flink 的集群配置设置如下:
- 在 $FLINK_HOME/conf/flink-conf.yaml 中添加配置项 taskmanager.numberOfTaskSlots: 4
- 在 $FLINK_HOME/conf/workers 中将条目 localhost 设置成 4 行,这里的行数代表了本地启动的 worker 数
启动集群:
# HADOOP_HOME is your hadoop root directory after unpack the binary package.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
# Start the flink standalone cluster
./bin/start-cluster.sh
2.3 启动 Flink SQL Client
Hudi 的 bundle jar 应该在 Sql Client 启动的时候加载到 CLASSPATH 中。您可以在路径 hudi-source-dir/packaging/hudi-flink-bundle 下手动编译 jar 包或者从 Apache Official Repository 下载。
启动 SQL CLI:
# HADOOP_HOME is your hadoop root directory after unpack the binary package.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
./bin/sql-client.sh embedded -j .../hudi-flink-bundle_2.1?-*.*.*.jar shell
备注:
- 推荐使用 hadoop 2.9.x+ 版本,因为一些对象存储(aliyun-oss)从这个版本开始支持
-
flink-parquet和flink-avro已经被打进 hudi-flink-bundle jar - 您也可以直接将 hudi-flink-bundle jar 拷贝到
$FLINK_HOME/lib目录下 - 本文的存储选取了对象存储 aliyun-oss,为了方便,您也可以使用本地路径
演示的工作目录结构如下:
/Users/chenyuzhao/workspace/hudi-demo
/- flink-1.11.3
/- hadoop-2.9.2
3. Batch 模式的读写
3.1 插入数据
使用如下 DDL 语句创建 Hudi 表:
Flink SQL> create table t2(
> uuid varchar(20),
> name varchar(10),
> age int,
> ts timestamp(3),
> `partition` varchar(20)
> )
> PARTITIONED BY (`partition`)
> with (
> 'connector' = 'hudi',
> 'path' = 'oss://vvr-daily/hudi/t2'
> );
[INFO] Table has been created.
DDL 里申明了表的 path,record key 为默认值 uuid,pre-combine key 为默认值 ts 。
然后通过 VALUES 语句往表中插入数据:
Flink SQL> insert into t2 values
> ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
> ('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
> ('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
> ('id4','F***',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
> ('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
> ('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
> ('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
> ('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 59f2e528d14061f23c552a7ebf9a76bd
这里看到 Flink 的作业已经成功提交到集群,可以本地打开 web UI 观察作业的执行情况:
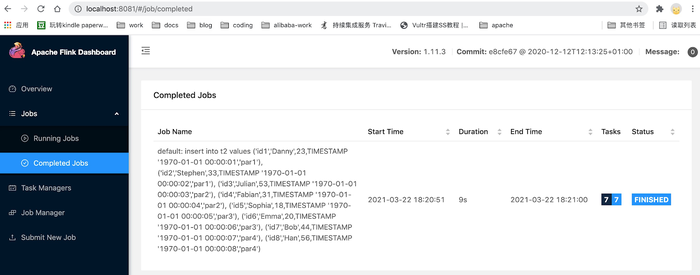
3.2 查询数据
作业执行完成后,通过 SELECT 语句查询表结果:
Flink SQL> set execution.result-mode=tableau;
[INFO] Session property has been set.
Flink SQL> select * from t2;
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| +/- | uuid | name | age | ts | partition |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| + | id3 | Julian | 53 | 1970-01-01T00:00:03 | par2 |
| + | id4 | F*** | 31 | 1970-01-01T00:00:04 | par2 |
| + | id7 | Bob | 44 | 1970-01-01T00:00:07 | par4 |
| + | id8 | Han | 56 | 1970-01-01T00:00:08 | par4 |
| + | id1 | Danny | 23 | 1970-01-01T00:00:01 | par1 |
| + | id2 | Stephen | 33 | 1970-01-01T00:00:02 | par1 |
| + | id5 | Sophia | 18 | 1970-01-01T00:00:05 | par3 |
| + | id6 | Emma | 20 | 1970-01-01T00:00:06 | par3 |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
Received a total of 8 rows
这里执行语句 set execution.result-mode=tableau; 可以让查询结果直接输出到终端。
通过在 WHERE 子句中添加 partition 路径来裁剪 partition:
Flink SQL> select * from t2 where `partition` = 'par1';
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| +/- | uuid | name | age | ts | partition |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| + | id1 | Danny | 23 | 1970-01-01T00:00:01 | par1 |
| + | id2 | Stephen | 33 | 1970-01-01T00:00:02 | par1 |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
Received a total of 2 rows
3.3 更新数据
相同的 record key 的数据会自动覆盖,通过 INSERT 相同 key 的数据可以实现数据更新:
Flink SQL> insert into t2 values
> ('id1','Danny',24,TIMESTAMP '1970-01-01 00:00:01','par1'),
> ('id2','Stephen',34,TIMESTAMP '1970-01-01 00:00:02','par1');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 944de5a1ecbb7eeb4d1e9e748174fe4c
Flink SQL> select * from t2;
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| +/- | uuid | name | age | ts | partition |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| + | id1 | Danny | 24 | 1970-01-01T00:00:01 | par1 |
| + | id2 | Stephen | 34 | 1970-01-01T00:00:02 | par1 |
| + | id3 | Julian | 53 | 1970-01-01T00:00:03 | par2 |
| + | id4 | F*** | 31 | 1970-01-01T00:00:04 | par2 |
| + | id5 | Sophia | 18 | 1970-01-01T00:00:05 | par3 |
| + | id6 | Emma | 20 | 1970-01-01T00:00:06 | par3 |
| + | id7 | Bob | 44 | 1970-01-01T00:00:07 | par4 |
| + | id8 | Han | 56 | 1970-01-01T00:00:08 | par4 |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
Received a total of 8 rows
可以看到 uuid 为 id1 和 id2 的数据 age 字段值发生了更新。
再次 insert 新数据观察结果:
Flink SQL> insert into t2 values
> ('id4','F***',32,TIMESTAMP '1970-01-01 00:00:04','par2'),
> ('id5','Sophia',19,TIMESTAMP '1970-01-01 00:00:05','par3');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: fdeb7fd9f08808e66d77220f43075720
Flink SQL> select * from t2;
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| +/- | uuid | name | age | ts | partition |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| + | id5 | Sophia | 19 | 1970-01-01T00:00:05 | par3 |
| + | id6 | Emma | 20 | 1970-01-01T00:00:06 | par3 |
| + | id3 | Julian | 53 | 1970-01-01T00:00:03 | par2 |
| + | id4 | F*** | 32 | 1970-01-01T00:00:04 | par2 |
| + | id1 | Danny | 24 | 1970-01-01T00:00:01 | par1 |
| + | id2 | Stephen | 34 | 1970-01-01T00:00:02 | par1 |
| + | id7 | Bob | 44 | 1970-01-01T00:00:07 | par4 |
| + | id8 | Han | 56 | 1970-01-01T00:00:08 | par4 |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
Received a total of 8 rows
4. Streaming 读
通过如下语句创建一张新的表并注入数据:
Flink SQL> create table t1(
> uuid varchar(20),
> name varchar(10),
> age int,
> ts timestamp(3),
> `partition` varchar(20)
> )
> PARTITIONED BY (`partition`)
> with (
> 'connector' = 'hudi',
> 'path' = 'oss://vvr-daily/hudi/t1',
> 'table.type' = 'MERGE_ON_READ',
> 'read.streaming.enabled' = 'true',
> 'read.streaming.check-interval' = '4'
> );
[INFO] Table has been created.
Flink SQL> insert into t1 values
> ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
> ('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
> ('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
> ('id4','F***',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
> ('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
> ('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
> ('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
> ('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 9e1dcd37fd0f8ca77534c30c7d87be2c
这里将 table option read.streaming.enabled 设置为 true,表明通过 streaming 的方式读取表数据;opiton read.streaming.check-interval 指定了 source 监控新的 commits 的间隔为 4s;option table.type 设置表类型为 MERGE_ON_READ,目前只有 MERGE_ON_READ 表支持 streaming 读。
以上操作发生在一个 terminal 中,我们称之为 terminal_1。
从新的 terminal(我们称之为 terminal_2)再次启动 Sql Client,重新创建 t1 表并查询:
Flink SQL> set execution.result-mode=tableau;
[INFO] Session property has been set.
Flink SQL> create table t1(
> uuid varchar(20),
> name varchar(10),
> age int,
> ts timestamp(3),
> `partition` varchar(20)
> )
> PARTITIONED BY (`partition`)
> with (
> 'connector' = 'hudi',
> 'path' = 'oss://vvr-daily/hudi/t1',
> 'table.type' = 'MERGE_ON_READ',
> 'read.streaming.enabled' = 'true',
> 'read.streaming.check-interval' = '4'
> );
[INFO] Table has been created.
Flink SQL> select * from t1;
2021-03-22 18:36:37,042 INFO org.apache.hadoop.conf.Configuration.deprecation [] - mapred.job.map.memory.mb is deprecated. Instead, use mapreduce.map.memory.mb
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| +/- | uuid | name | age | ts | partition |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| + | id2 | Stephen | 33 | 1970-01-01T00:00:02 | par1 |
| + | id1 | Danny | 23 | 1970-01-01T00:00:01 | par1 |
| + | id6 | Emma | 20 | 1970-01-01T00:00:06 | par3 |
| + | id5 | Sophia | 18 | 1970-01-01T00:00:05 | par3 |
| + | id8 | Han | 56 | 1970-01-01T00:00:08 | par4 |
| + | id7 | Bob | 44 | 1970-01-01T00:00:07 | par4 |
| + | id4 | F*** | 31 | 1970-01-01T00:00:04 | par2 |
| + | id3 | Julian | 53 | 1970-01-01T00:00:03 | par2 |
回到 terminal_1,继续执行 batch mode 的 INSERT 操作:
Flink SQL> insert into t1 values
> ('id1','Danny',27,TIMESTAMP '1970-01-01 00:00:01','par1');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 2dad24e067b38bc48c3a8f84e793e08b
几秒之后,观察 terminal_2 的输出多了一行:
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| +/- | uuid | name | age | ts | partition |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| + | id2 | Stephen | 33 | 1970-01-01T00:00:02 | par1 |
| + | id1 | Danny | 23 | 1970-01-01T00:00:01 | par1 |
| + | id6 | Emma | 20 | 1970-01-01T00:00:06 | par3 |
| + | id5 | Sophia | 18 | 1970-01-01T00:00:05 | par3 |
| + | id8 | Han | 56 | 1970-01-01T00:00:08 | par4 |
| + | id7 | Bob | 44 | 1970-01-01T00:00:07 | par4 |
| + | id4 | F*** | 31 | 1970-01-01T00:00:04 | par2 |
| + | id3 | Julian | 53 | 1970-01-01T00:00:03 | par2 |
| + | id1 | Danny | 27 | 1970-01-01T00:00:01 | par1 |
再次在 terminal_1 中执行 INSERT 操作:
Flink SQL> insert into t1 values
> ('id4','F***',32,TIMESTAMP '1970-01-01 00:00:04','par2'),
> ('id5','Sophia',19,TIMESTAMP '1970-01-01 00:00:05','par3');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: ecafffda3d294a13b0a945feb9acc8a5
观察 terminal_2 的输出变化:
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| +/- | uuid | name | age | ts | partition |
+-----+----------------------+----------------------+-------------+-------------------------+----------------------+
| + | id2 | Stephen | 33 | 1970-01-01T00:00:02 | par1 |
| + | id1 | Danny | 23 | 1970-01-01T00:00:01 | par1 |
| + | id6 | Emma | 20 | 1970-01-01T00:00:06 | par3 |
| + | id5 | Sophia | 18 | 1970-01-01T00:00:05 | par3 |
| + | id8 | Han | 56 | 1970-01-01T00:00:08 | par4 |
| + | id7 | Bob | 44 | 1970-01-01T00:00:07 | par4 |
| + | id4 | F*** | 31 | 1970-01-01T00:00:04 | par2 |
| + | id3 | Julian | 53 | 1970-01-01T00:00:03 | par2 |
| + | id1 | Danny | 27 | 1970-01-01T00:00:01 | par1 |
| + | id5 | Sophia | 19 | 1970-01-01T00:00:05 | par3 |
| + | id4 | F*** | 32 | 1970-01-01T00:00:04 | par2 |
5. 总结
通过一些简单的演示,我们发现 HUDI Flink 的集成已经相对完善,读写路径均已覆盖,关于详细的配置,可以参考 Flink SQL Config Options。
Hudi 社区正在积极的推动和 Flink 的深度集成,包括但不限于:
- Flink streaming reader 支持 watermark,实现数据湖/仓的中间计算层 pipeline
- Flink 基于 Hudi 的物化视图,实现分钟级的增量视图,服务于线上的近实时查询






 京公网安备 11010802041100号
京公网安备 11010802041100号