作者: | 来源:互联网 | 2023-06-20 12:34
本文由编程笔记#小编为大家整理,主要介绍了视频质量评测标准——VMAF相关的知识,希望对你有一定的参考价值。阿里云视频云直播转码每天都会处理大量的不同场景、不同编码格式的直播流
本文由编程笔记#小编为大家整理,主要介绍了视频质量评测标准——VMAF相关的知识,希望对你有一定的参考价值。
阿里云视频云直播转码每天都会处理大量的不同场景、不同编码格式的直播流。为了保证高画质,团队借助VMAF标准来对每路转码的效果做质量评估,然后进行反馈、调优、迭代。这么做的原因在于,像动作片、纪录片、动画片、体育赛事这些场景,影响画质的因素各不相同,基于VMAF的视频质量反馈机制,可以在保证画质的前提下,对不同的场景做针对性优化,达到画质最优、成本最低的效果。本文由阿里云视频云高级开发工程师杨洋撰写,旨在分享VMAF的核心模块与技术实践。
背景
图像质量的衡量是个老问题,对此人们提出过很多简单可行的解决方案。例如均方误差(Mean-squared-error,MSE)、峰值信噪比(Peak-signal-to-noise-ratio,PSNR)以及结构相似性指数(Structural Similarity Index,SSIM),这些指标最初都是被用于衡量图像质量的,随后被扩展到视频领域。这些指标通常会用在编码器(“循环”)内部,可用于对编码决策进行优化并估算最终编码后视频的质量。但是由于这些算法衡量标准单一,缺乏对画面前后序列的总体评估,导致计算的结果很多情况下与主观感受并不相符。
VMAF 介绍
VMAF(Video Multimethod Assessment Fusion)由Netflix开发并开源在Github上,基本想法在于,面对不同特征的源内容、失真类型,以及扭曲程度,每个基本指标各有优劣。通过使用机器学习算法(SVM)将基本指标“融合”为一个最终指标,可以为每个基本指标分配一定的权重,这样最终得到的指标就可以保留每个基本指标的所有优势,借此可得出更精确的最终分数。Netfix使用主观实验中获得的意见分数对这个机器学习模型进行训练和测试。VMAF主要使用了3种指标:visual quality fidelity(VIF)、detail loss measure(DLM)、temporal information(TI)。其中VIF和DLM是空间域的也即一帧画面之内的特征,TI是时间域的也即多帧画面之间相关性的特征。这些特性之间融合计算总分的过程使用了训练好的SVM来预测。工作流程如图:
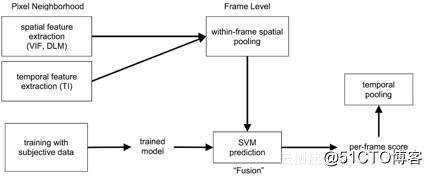
VMAF 核心模块
VMAF基于SVM的nuSvr算法,在运行的过程中,根据事先训练好的model,赋予每种视频特征以不同的权重。对每一帧画面都生成一个评分,最终以均值算法进行归总(也可以使用其他的归总算法),算出该视频的最终评分。其中主要的几个核心模块如下:
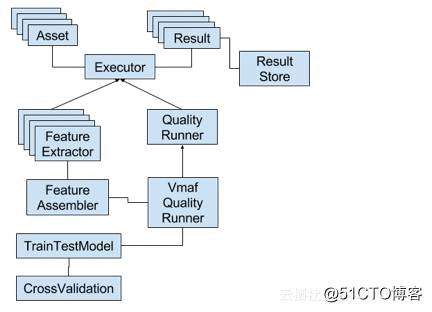
VMAF分别用python和C++实现了两套接口,同时提供了C版本的lib库,最新版本的ffmpeg已经将vmaf作为一个filter集成进去。下面我们分析下各个模块的作用:
? Asset
一个Asset单元,包含了一个正在执行的任务信息。比如目标视频与原始视频的帧范围,低分辨率视频帧上采样信息等(VMAF会在特征提取前通过上采样的方式保证两个视频分辨率相同)。
? Executor
Executor会取走并计算Asset链表中每一个Asset单元,将执行结果返回到一个Results链表中。Executor类是FeatureExtractor与QualityRunner的基类。它提供了一些基函数,包括Results的操作函数、FIFO管道函数、clean函数等。
? Result
Result是以key-value形式,将Executor执行的结果存储起来。key存储的是“FrameNum”或者质量分数的类型(VMAF_feature_vif_scale0_score或VMAF_feature_vif_scale1_score等),value存储的是一系列分值组成的链表。
Result类也提供了一个汇总工具,将每个单元的质量分数汇总成一个值。默认的汇总算法是“均值算法”,但是Result.set_score_aggregate_method()方法允许定制其他的算法。
? ResultStore
ResultStore类提供了Result数据集的存储、加载的能力。
? FeatureExtractor
FeatureExtractor是Extractor子类,专门用于从Asset集合中提取特征,作为基本的特征提取类。任何具体的特征提取接口,都继承自FeatureExtractor,例如VmafFeatureExtractor/PsnrFeatureExtractor/SsimFeatureExtractor等。
? FeatureAssembler
FeatureAssembler是一个聚合类,通过在构造函数传入feature_dict参数,指定具体的特征提取标准,将该标准提取出的特征结果聚合,输出到一个BasicResult对象中。FeatureAssembler被QualityRunner调用,用来将提取后的特征数组传给TrainTestModel使用。
? TrainTestModel
TrainTestModel是任何具体的回归因子接口的基类,回归因子必须提供一个train()方法去训练数据集,predict()方法去预测数据集,以及to_file(),frome_file()方法去保存、加载训练好的模型。
回归方程的超参数必须通过TrainTestModel的构造函数传入。TrainTestModel类提供了一些基础方法,例如归一化、反归一化、评估预测性能。
? CrossValidation
CrossValidation提供了一组静态方法来促进TrainTestModel训练结果的验证。因此,它还提供了搜索TrainTestModel最优超参的方法。
? QualityRunner
QualityRunner是Executor子类,用来评估Asset任务集合的画质分数。任何用于生成最终质量评分的接口都应该继承QualityRunner。例如跑vmaf标准的VmafQualityRunner,跑psnr标准的PsnrQualityRunner都是QualityRunner的子类。
自定义VMAF
最新版本的vmaf提供了1080p、4k、mobilephone三种场景下的model文件。Netflix号称使用了海量的、多分辨率、多码率视频素材(高噪声视频、CG动漫、电视剧)作为数据集,得到的这三组model。在日常使用中,这三组model基本满足需求了。不过,VMAF提供了model训练工具,可以用于训练私有model。
创建新的数据集
首先,按照dataset格式,定义数据集文件,比如定义一个
example_dataset.py:
dataset_name = ‘example_dataset‘
yuv_fmt = ‘yuv420p‘
width = 1920
height = 1080
ref_videos = [
{‘content_id‘: 0,
‘content_name‘: ‘BigBuckBunny‘,
‘path‘: ref_dir + ‘/BigBuckBunny_25fps.yuv‘}
...
]
dis_videos = [{‘asset_id‘: 0,
‘content_id‘: 0,
‘dmos‘: 100.0,
‘path‘: ref_dir + ‘/BigBuckBunny_25fps.yuv‘,
}
...
]
ref_video是比对视频集,dis_video是训练集。每个训练集样本视频都有一个主观评分DMOS,进行主观训练。SVM会根据DMOS做有监督学习,所以DMOS直接关系到训练后model的准确性。
PS: 将所有观察者针对每个样本视频的分数汇总在一起计算出微分平均意见分数(Differential Mean Opinion Score)即DMOS,并换算成0-100的标准分,分数越高表示主观感受越好。
验证数据集
./run_testing quality_type test_dataset_file [--vmaf-model optional_VMAF_model_path] [--cache-result] [--parallelize]
数据集创建后,用现有的VMAF或其他指标(PSNR,SSIM)验证数据集是否正确,验证无误后才能训练。
训练新的模型
验证完数据集没问题后,便可以基于数据集,训练一个新的质量评估模型。
./run_vmaf_training train_dataset_filepath feature_param_file model_param_file output_model_file [--cache-result] [--parallelize]
例如,
./run_vmaf_training example_dataset.py resource/feature_param/vmaf_feature_v2.py resource/model_param/libsvmnusvr_v2.py workspace/model/test_model.pkl --cache-result --parallelize
feature_param_file 定义了使用那些VMAF特征属性。例如,
feature_dict = {‘VMAF_feature‘:‘all‘, } 或 feature_dict = {‘VMAF_feature‘:[‘vif‘, ‘adm‘], }
model_param_file 定义了回归量的类型和使用的参数集。当前版本的VMAF支持nuSVR和随机森林两种机器算法,默认使用的nuSVR。
output_model_file 是新生成的model文件。
交叉验证
vmaf提供了run_vmaf_cross_validation.py工具用于对新生成的model文件做交叉验证。
自定义特征和回归因子
vmaf具有很好的可扩展性,不仅可以训练私有的model,也可以定制化或插入第三方的特征属性、SVM回归因子。
通过feature_param_file类型文件,支持自定义或插入第三方特征,需要注意的是所有的新特征必须要是FeatureExtractor子类。类似的,也可以通过param_model_file类型文件,自定义或插入一个第三方的回归因子。同样需要注意的是,所有创建的新因子,必须是TrainTestModel子类。
由于Netflix没有开放用于训练的数据集,个人觉得,受制于数据集DMOS准确性、数据集样本的量级等因素,通过自建数据集训练出普适的model还是挺不容易滴~

![R语言中向量(Vector)数据类型的元素索引与访问:利用中括号[]和赋值操作符在向量末尾追加数据以扩展其长度](https://img5.php1.cn/3cdc5/92e2/2be/c2a171af6e5eeb5a.png)



 京公网安备 11010802041100号
京公网安备 11010802041100号