作者:mobiledu2502901927 | 来源:互联网 | 2023-05-19 05:09
本文主要分享【原理是怎样的】,技术文章【优化姿态估计模型【个人实验记录】】为【Ctrl_Cver】投稿,如果你遇到深度学习相关问题,本文相关知识或能到你。原理是怎样的前言(连载中)本文是个人优
本文主要分享【原理是怎样的】,技术文章【优化姿态估计模型【个人实验记录】】为【Ctrl_Cver】投稿,如果你遇到深度学习相关问题,本文相关知识或能到你。
原理是怎样的
前言(连载中)
本文是个人优化实验的记录,若读者对实验有兴趣,请点赞并评论,后续我会把代码开源。本文优化了一个regression-based 轻量级姿态估计模型,最终速度未知,最终精度未知。实验大部分参考了镜子大佬知乎的优化过程。
配置 框架mmpose。数据集为mpii,16个关键点,评价指标为pckh。训练使用四块3090显卡。 配置文件组成
不同实验的配置文件如下,训练完成会在workdir下根据配置文件名生成不同的文件夹。

实验 第一部分,dsnt 首先确认
(1) baseline(regression-based),与镜子大佬一样,本文使用的baseline为shufflev2+deeppose的方案,直接回归出关节坐标点。然后以heatmap-based的方法
(2) shufflev2+heatmap为target,本文将实现一个精度和速度均超过target的regression-based 轻量级姿态估计模型; 实验结果如下:
推理耗时计算方法,转成onnx计算单张图片推理耗时一千次,取50:950的均值,耗时计算偶尔会有1ms的波动,仅供参考。

可以看到,regression-based方法比heatmap-based方法精度低许多,但是regression-based方法可以直接得到坐标点,不需要后处理。backbone输出特征图维度(b,1024,8,8),使用一个卷积得到(b,16,8,8) 论文dsnt对输出的特征图求期望得到(b,16,2)个关键点,并使用js散度进行正则化。dsnt可以隐式的利用了heatmap学到的特征,比直接回归坐标有更高的精度。实验结果如下,js散度有个超参数sigma,根据经验
高斯核的一般取 sigma = n/64*2,n为特征图大小,所以这里sigma取
0.25最好。dsnt的损失由两部分组成,一是js散度,二是pred和gt的mse。

正则化js散度有个权重,具体实验如下。js散度对最终的精度影响不大,所以后续实验
默认取1。

实验11 把adam优化器换成了adamw,实验12 在11的基础上把四张卡训练换成了一张卡,实验13 在11的基础上把epoch增加到了310。一,实验4和实验11对比,可知adamw有用。二,实验11和12对比,单卡训练比多卡训练精度高,原因具体参考链接。另外增大epoch没有效果,说明已经收敛了。

在实验11的基础上,加上实验2训练得到的backbone,使用它初始化我们模型的bacbone。最终的结果如下:

第一部分完结,最终的模型为:
input: 256*256, backbone: shufflev2 1.0x,
output 64*1024*8*8,
no neck,
decode: one conv 64*16*8*8,
with dsnt, sigma 0.25, mse_w 1, js_w 1, adamw, hm预训练权重
总结:dsnt sigma 0.25 + mse_w=1 + js_w=1 + adamw + hm预训练权重 = 提升精度
第二部分,rle
iccv2021 rle,flow模型概念。简单来说,回归模型回归出坐标点和伸缩尺度,flow模型估计差值分布。最终坐标 = 伸缩尺度*差值分布+回归出的坐标。inference时假设预测得到的 回归坐标=最终坐标,所以丢弃了flow模型。为了添加rle,backbone出来分为两个分支,一个用作dsnt回归坐标;另外一个用于rle预测分布。
实验一加上rle,得到实验15。实验16加上了预训练权重。实验17在15上加上了dsnt。实验18在15的基础上加上了dsnt和预训练权重。到这一步,损失由dsnt的损失和rle的损失构成。实验19-21为无用实验,对一些权重进行了调整。实验22把backbone的宽度为2.0,得到了扩大bacbone后heatmap-based方法的精度。实验23在18的基础上扩大了bacbone,并使用了22的权重。实验24,在18的基础上对bacbone输出的特征图反卷积两次扩大输出特征图。
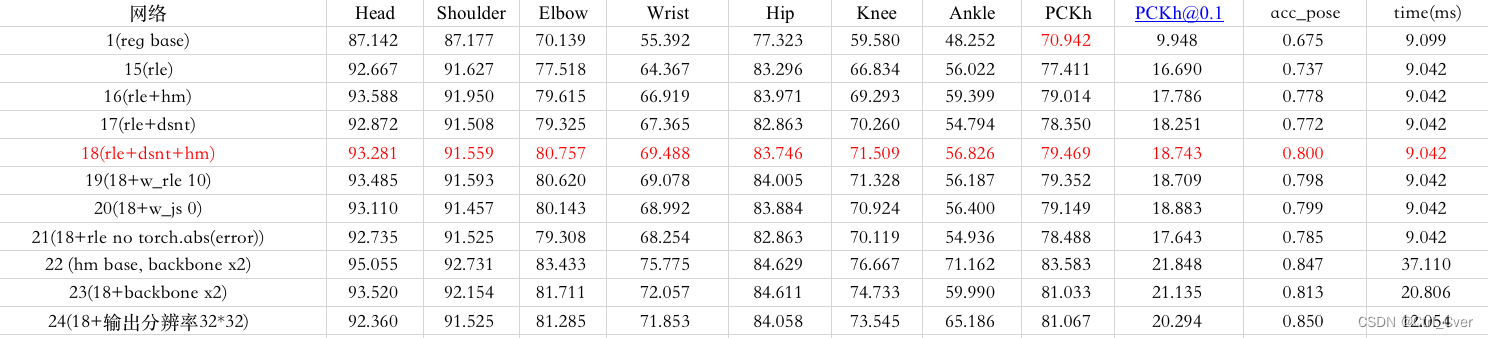
总结:rle+hm权重+dsnt+扩大输出分辨率 = 提高精度。另外,加大backbone的深度也可以提高精度,这里忽略,后续继续使用 shufflev2 x1的backbone。 第三部分,simcc
待续~
本文《优化姿态估计模型【个人实验记录】》版权归Ctrl_Cver所有,引用优化姿态估计模型【个人实验记录】需遵循CC 4.0 BY-SA版权协议。










 京公网安备 11010802041100号
京公网安备 11010802041100号