作者:唯忻小十__ | 来源:互联网 | 2023-09-23 23:55
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Python 的正则表达式彩蛋相关的知识,希望对你有一定的参考价值。
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
虽然我觉得在 Python 的标准库里的确有不少很恶心的库,但是 re 库肯定不属于这种。尽管它真的有年头没有更新了,但是在我看来,仍不失为动态语言中最好的库之一。
我觉得 Python 作为一种动态语言,竟然没有对正则表达式进行原生支持,真是少见。尽管没有提供(原生的)语法和解释器的支持,但(这个模块)从纯 API 的角度给出了一个设计更加完善的核心系统作为补充的解决方案。然而这个方案也挺诡异的,比方说,它的解析器是用纯 Python 写的,如果你导入库的同时去追踪 Python 就会产生一些很诡异的结果。最后你会发现自己90%的时间都花在了 re 的支持库上。
久经考验
经过时间的沉淀,正则库早已成为历代 Python 标准库中不可或缺的部分。 Python3 就另当别论了,我觉得除了增加了对 unicode 的支持以外,它从始至今没什么本质的提升。到现在,成员枚举都是乱七八糟的(不信就去试试看,对一个正则对象用 dir() 函数能返回什么东西)。

用了这个正则库最大的好处就是非常稳定,任它 Python 版本更替,我自巍然不动。你的 Python 已经不是当年的 Python了,你的 re 永远是你的 re。考虑到我写过那许许多多的正则表达式,却从来没有因为 re 库的变动而重写,那必须是满满的幸福啊。
这个库有一点我觉得设计的挺神奇的,它的构造(compiler)和解析(parser)函数是用 Python 写的,但是匹配(matcher) 函数是用 C 写的。这意味着如果我们愿意的话,就可以将解析器的内部结构传递给编译器,从而完全绕过正则表达式的解析。虽然文档里没写,但事实上确实可以这么干。
还有很多这种例子,但是在(官方)文档中的正则部分都没有收录,或者没讲清楚,所以下面我就给大家演示几个例子,让你见识见识 Python 的正则库到底有多炫酷。
迭代匹配
如果要说在 Python 的正则库当中哪个特性是最大的亮点,那毫无疑问,肯定是把 matching 和 searching 两种功能区别开。这一点上,很多其它正则表达式引擎都没有做到。在使用 match 函数进行匹配的时候,你可以专门指定一个起始索引位置,让它从此位置开始匹配。
也就是说,你可以这么写:

这在写词法分析的时候就非常实用,因为你可以一直用 “^” 符号来表示行首,然后只要调整后面的 pos 索引参数就可以一直匹配下去。同时,有了这个功能,我们再也不需要自己手动分割字符串来匹配了,一下就省掉大量的内存分配和字符串复制的过程(况且 Python 并不擅长这个)。
除了 match 函数, Python 还提供了 search 函数,它能自动跳过字符串头,直到成功匹配:

空既是色
想在 Python 中使用正则表达式实现逆匹配(一个 pattern 与指定字符串不匹配)一般来说比较麻烦。假设我们要写一个类似维基语言那样(比如 Markdown 语言)的语法分析器。除了那些表示特定格式的语法标记,中间还有许多文本也需要我们来处理。这时我们只想匹配那些已知的标记符号,但是中间还有很多别的内容(非语法标记)也需要处理。怎么才能跳过这些内容呢?
一种方案是编译一组正则表达式然后放到一个列表里,逐个去尝试匹配。如果全部匹配失败,就跳过当前字符(然后继续匹配)。
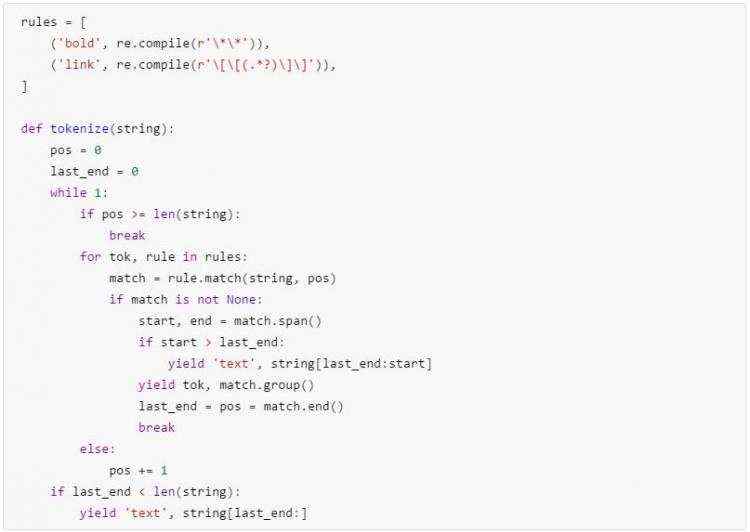
这个方案既不优雅也不高效。一般来说,匹配失败的情况越多代码效率就越低。因为那样就意味着我们每次只能向后跳过一个字符,而且还是用的 Python 这种解释型的语言(来循环)。同时,这种方案灵活性也不够好,每次只能匹配到对应的标记符号,如果还要匹配分组就只能再把这段重新扩展一下。
难道就没什么好办法了吗?我们就不能让正则引擎直接去扫描指定的一批正则表达式吗?
下面有意思的来了。实际上,如果我们把表达式写成 (a | b)这种分枝条件的样式,它就会同时搜索是否匹配 a 或者 b。所以我们可以把要匹配的所有语法标记全部这样写到一起,然后去匹配就好了。这么匹配写起来很方便,但是匹配结果你肯定一脸懵比,因为完全不知道是被那一堆表达式中的哪一个匹配成功的。
深入正则引擎
下面进入正题。在过去的差不多 15 年里,有一个奇葩特性一直没有写到正则表达式的文档当中,那就是“扫描器”。扫描器是底层的 SRE 对象的一个属性,让引擎在找到一个匹配结果之后能继续向后匹配。甚至还有一个 re.Scanner 的类(也没有收到文档中),它是在 SRE 模式扫描器之上构建的,提供了一个稍微高级一点的接口。
re 库里这个扫描器虽然并不能帮助逆匹配变快,但是通过查看它的原代码能让我们了解到,它是怎么基于 SRE 来实现的。
它的工作原理是先接收一个正则表达式和回调元组列表,每次匹配成功就调用回调函数,返回 match 对象,最后生成一个结果列表。如果进一步查看实现细节,就会发现它其实会手动在内部创建 SRE 模式和子模式对象。(就是说,它构造了一个大型的正则表达式而不必进行解析)。现在有了这些知识,我们就可以这样扩展了:
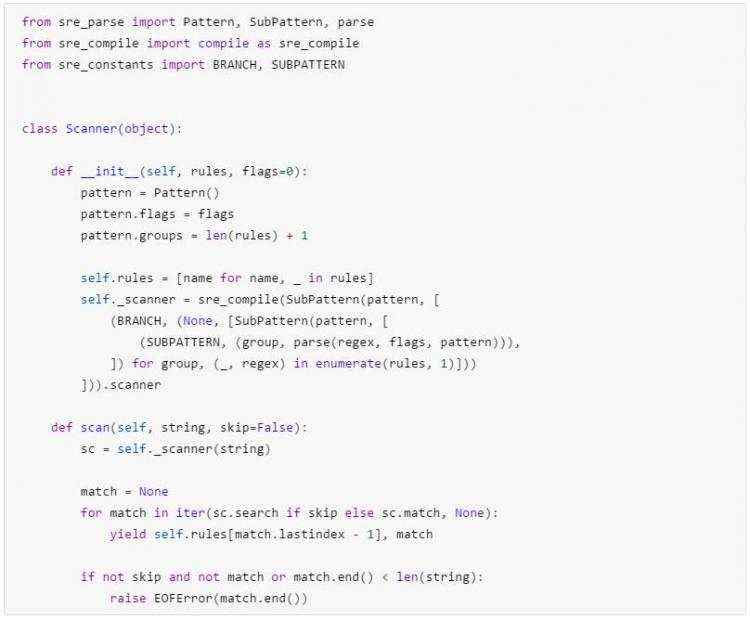
这段代码怎么用呢?照下面这样写:
这里如果没有匹配到任何内容会抛出一个 EOFError ,如果你设置 skip = True 的话它就可以跳过未匹配的部分,用它来设计一个像维基语法分析器这种东西真是再完美不过了。
查找空位
匹配搜索时被跳过的部分我们可以用 match.start() 和 match.end() 来确定跳过部分的起止位置。那么,之前第一个例子经过调整,就变成这样:
解决分组问题
还有一件头疼的事情,我们的组索引并不是正则表达式的索引,而是组合索引。这就意味着如果你的条件是像 (a | b) 这种格式,当你打算通过索引访问这个组的时候会出问题。这还需要我们做一些额外的工作把 SRE 匹配对象用一个类包装起来,让它能和组索引以及组名称相统一。如果你有兴趣,我在 github 里还做了一个比上面的解决方案更复杂的版本,基本实现了包装的效果,而且还准备了一些示例供你参考。
英文原文:http://lucumr.pocoo.org/2015/11/18/pythons-hidden-re-gems/
译者:WDatou







 京公网安备 11010802041100号
京公网安备 11010802041100号