【51CTO技术译文】为什么Java程序员要考虑使用Google的Java App Engine呢,主要有以下几点原因:只要你的页面访问量每月不超过500万,Google就免费向你提供空间。如果访问量超过了这一限额,你也可以随时通过升级为付费用户取消这一限制。
◆Google的App Engine 平台(包括Java和Python版本)让你不用做什么额外工作就有很强的伸缩性
◆App Engine 提供了一个功能很强的管理界面,你可以通过它查看错误日志,浏览你所保存的数据,分析程序的性能(例如请求响应时间等),还可以实时监控你所部署的应用。即便是和Amazon的EC2这样优秀的Web控制台比起来,Google的Web应用程序管理功能也毫不逊色。
◆只要你愿意,你也可以通过App Engine SDK 把App Engine 上的应用迁移到你自己的服务器上,当然,这样就会损失一些伸缩性(scalability)了。
◆因为在App Engine上开发程序时使用的都是标准的 API,所以当你要把应用移植部署到其它平台上时,就只需要对程序作非常小的改动了。不过反过来做就不是这么简单了。比如说如果你的程序调用大量的J2EE API函数,或者说依赖于关系型数据库等等,那么把这些程序移植到App Engine上就非常麻烦。
◆那些用J2EE写Web程序的开发者们可能一开始会觉得App Engine 的种种限制让人觉得很不适应,但是这样做的好处也是很明显的,服务器的花费将大大减少。如果你想要更大的自由度和伸缩性,那么你还可以考虑Amazon的EC2服务(我是既用App Engine,也用EC2)。
本文接下来将介绍Java开发者如何使用Google应用程序引擎。它演示了如何在App Engine上编写实现文档的存储和搜索功能。本文还探讨了Java App Engine文档里的一些有用技术和应用程序示例。
你需要作的准备
◆Eclipse或IntelliJ IDEA开发环境
◆一个App Engine 帐号,如果还没有的话,在这里申请(没有App Engine 帐号的开发者可以通过在你自己电脑上安装App Engine SDK体验它)
◆下载App Engine SDK 供本地开发时使用
◆安装Eclipse的或IntelliJ 的Java App Engine 插件。
示例工程里的文件
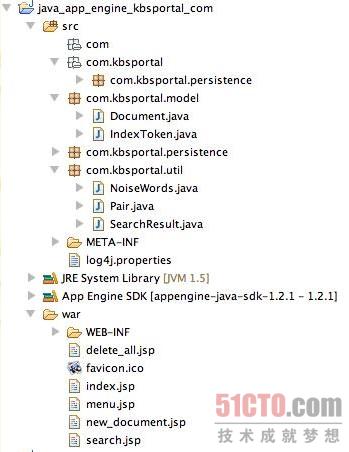
图1 示例工程里的文件
许多Java开发人员使用 Lucene (或基于Lucene的框架)来实现搜索功能。但是,在App Engine环境下使用Lucene的内存索引模式没有什么好处。我们的这个示例工程另辟蹊径在App Engine平台上实现了搜索功能。
App Engine的持久性数据存储效率是非常高的,但它不使用关系模型,也没有Hibernate这样的对象关系映射(Object Relational Mapping ,ORM)框架。不过,App Engine还是提供了对一些标准的持久性API,如JDO,JPA,以及JCache。我们的示例程序使用JDO实现数据持久(data persistence)。
这个程序部署在这里。每个使用这个演示程序的人都可以把数据清空从头再来,所以你这次添加的信息下次可以就会看不到了。
作者注:这个程序演示了JDO的使用以及如何用JDO实现搜索,为了突出重点,程序没有增加对多用户这些功能的支持。
图1显示了这个Java App Engine项目所包含的文件。后续的章节将详细介绍packagecom.kbsportal.model 里的模型类和 com.kbsportal.persistence 里的持久类PMF。由于packagecom.kbsportal.util这个包里的各种类和App Engine里的差别较大,我们就不在这里作过多讨论了。如果要详细了解这些,你可以看看我们的源代码以及JSP文件(在 war/WEB-INF目录里)。我们也会对JSP文件里某些Java代码片段加以解释。
使用JDO实现数据持久化
JDO是一个用于持久化Java对象的古老API。起初,为了实现持久化存储,JDO要求开发者必须编写和维护XML文件,以提供Java类的数据映射属性。Google使用 DataNucleus 工具自动完成这一过程。你只需要在你的Java模型类里面加以注解,DataNucleus工具就会自动为你维护正确的数据映射关系。如果使用了Eclipse的或IntelliJ IDEA的App Engine插件,当你编写持久类时,DataNucleus工具就会自动在后台作用。
警告:JDO和App Engine放到一起有时候会产生兼容性问题。如果你是在本地用Eclipse开发,只要删除目录 WEBAPP /war/WEB-INF/ appengine-generated/ local_db.bin里的文件。 如果你的Web应用已经部署上去了而且要修改模型类,那么你只需在App Engine控制台中把已有的索引文件删除即可
以下各节将介绍两个持久类的实现并探讨这些基于JDO实现的代码。
文档模型类
Eclipse或IntelliJ IDEA的App Engine插件与JDO以及DataNucleus工具的组合非常好用。使用这个组合设计和实现你自己的模型文件,并添加必须的注解,这些对你来说应该不成问题。不过你还是要注意DataNucleus工具在后台运行时所提示的错误信息。
在开始设计实现自己的持久类前,不妨先看看下面这个模型类,它是用来反映一个文件模型的。这个类在定义时会引入所需的JDO 类(实际上你的编辑器会自动帮你填写这些包含语句)。第一行注释声明了这个类是持久的。这个类被标识为APPLICATION,这样你就可以为那些创建后就将持久存在的对象分配ID。如果你要为数据存储对象分配ID,那么你可以把类型指定为DATASTORE。
- package com.kbsportal.model;
-
- import javax.jdo.annotations.IdentityType;
- import javax.jdo.annotations.PersistenceCapable;
- import javax.jdo.annotations.Persistent;
- import javax.jdo.annotations.PrimaryKey;
-
- @PersistenceCapable(identityType=IdentityType.APPLICATION)
- public class Document {
-
这段代码声明了把成员变量uri作为在数据存储里查找Document对象时的主键。JDO的索引主键也被设为URI。本文的示例文本存储在IndexToken这个类里面使用了这个主键(IndexToken类将在下一节进一步讨论)。这段代码还特别说明了title, content以及numWords这几个成员变量要持久保存。
- @PrimaryKey private String uri;
- @Persistent private String title;
- @Persistent private String content;
- @Persistent private int numWords;
类声明里的其它部分则不包含JDO具体说明。
- public Document(String uri, String title, String content) {
- super();
- setContent(content);
- this.title = title;
- this.key = uri;
- }
- public String getUri() { return key; }
- public String getTitle() { return title; }
- public void setTitle(String title) { this.title = title; }
- public String getContent() { return content; }
- public void setContent(String content) {
- this.content = content;
- this.numWords = content.split("[\ \.\,\:\;!]").length;
- System.out.println("** numWords = " + numWords + " content: "+content);
- }
- public int getNumWords() { return numWords; }
- }
注意在内容字符串上所作的长度限制;GoogleApp Engine的数据存储限制字符串不得超过500个字符。(使用com.google.appengine.api.datastore.Textfors可以获得没有长度限制的字串。 )
IndexToken模型类
该IndexToken类基于JDO实现了搜索功能。这个类有两种工作模式:整词索引、整词及词前缀索引。在源文件的头部你可以通过一个常量指定它的工作模式:
- package com.kbsportal.model;
-
- import java.util.ArrayList;
- import java.util.Collections;
- import java.util.Comparator;
- import java.util.HashMap;
- import java.util.List;
-
- import javax.jdo.PersistenceManager;
- import javax.jdo.annotations.IdGeneratorStrategy;
- import javax.jdo.annotations.IdentityType;
- import javax.jdo.annotations.Index;
- import javax.jdo.annotations.PersistenceCapable;
- import javax.jdo.annotations.Persistent;
- import javax.jdo.annotations.PrimaryKey;
-
- import com.kbsportal.persistence.PMF;
- import com.kbsportal.util.NoiseWords;
- import com.kbsportal.util.Pair;
- import com.kbsportal.util.SearchResult;
-
- @PersistenceCapable(identityType=IdentityType.APPLICATION)
- public class IndexToken {
- static boolean MATCH_PARTIAL_WORDS = true;
把这个标志设置为true,就会开启单词的前缀匹配功能,类似于搜索关键字自动校正功能。
现在我们该看看如何建立索引片段(可能还包括单词前缀的索引片段)以及如何确定每个索引片段的匹配度。以下是具体的代码(来自IndexToken.java包里的源文件,它是作为一个单独的局部类实现的,以方便在其他项目重复使用) :
- class StringPrefix {
- public List getPrefixes(String str) {
- List ret = new ArrayList();
- String[] toks = str.toLowerCase().split("[\ \.\,\:\;\(\)\-\[\]!]");
- for (String s : toks) {
- if (!(NoiseWords.checkFor(s))) {
- if (!IndexToken.MATCH_PARTIAL_WORDS) {
- ret.add(new Pair(s, 1f));
- } else {
- int len = s.length();
- if (len > 2) {
- ret.add(new Pair(s, 1f));
- if (len > 3) {
- int start_index = 1 + (len / 2);
- for (int i = start_index; i
- ret.add(new Pair(s.substring(0, i), (0.25f * (float) i) / (float) len));
- }
- }
- }
- }
- }
- }
- return ret;
- }
- }
应用中的一些理念
通过使用 Peter Norvig的拼写检查算法可以实现更完整的拼写检查功能。使用相对较低的相关系数可以生成错误的拼写序列和IndexToken实例。在我所写的书"Practical Artificial Intelligence Programming in Java"的第9章里有一个Java版本的 Norvig算法实现。
其它实现方法
我在另一个大项目里使用了这些代码,那个项目需要一个弹出式的文字补全提示;我们存储的这些前缀起到了“双重作用”。本文主要讲解基于JDO的文件存储和搜索,但你可以简单地使用一个Javascript库,例如 Prototype或GWT实现弹出的提示菜单。另外,你也可以只把词干作为 IndexToken实例保存。点击此处查看相关Java词根提取程序。
Pair这个类是在com.kbsportal.util包里实现的,这个包里面还有另外两个类: NoiseWords和SearchResults 。我们在此不再追究这些类的细节。今后我们将深入这些源文件。
要完成IndexToken,以及示例程序的其余部分,我们要用到JDO的API,首先是在类属性说明里加入这些注解:
- @PrimaryKey
- @Persistent(valueStrategy = IdGeneratorStrategy.IDENTITY)
- private Long id;
- @Persistent @Index private String textToken;
- @Persistent private String documentUri;
- @Persistent private Float ranking;
@Persistent 标示这个成员在整个对象被保存时要被插入到数据存储里去。valueStrategy的值是可选的,按上面这样设置是表明你希望数据存储为你这个类的ID属性自动赋值。@PrimaryKey 注释让DataNucleus工具知道,在查找数据存储区里的这种对象时要以该参数为主键。
作者注:通常情况下都是通过主键获取对象。然而,在我们这个程序里,我们将要通过IndexToken类的参数值 textToken 来查找对象。但是我们不能使用参数textToken 作为主键,因为这样有可能导致在数据存储区里有主键一样的不同实例出现。
下面这个成员方法能获取文件ID(文件的URI)以及文件中的一段文字,实例化一个IndexToken类:
- public static void indexString(String document_id, String text) {
- PersistenceManager pm = PMF.get().getPersistenceManager();
- List lp = new StringPrefix().getPrefixes(text);
- for (Pair p : lp) {
- if (p.str.length() > 0 && !Character.isDigit(p.str.charAt(0))) {
- pm.makePersistent(new IndexToken(document_id, p.str, p.f));
- }
- }
- }
这段代码用到了StringPrefix 类。另外还使用了工具类PMF(等下我们就会更详细地去了解它)来获得一个App Engine持久管理器(persistence manager)的实例。这类似于一个JDBC 连接对象。
在IndexToken里还有一个值得一提的地方就是search这个静态方法.
- public static List search(String query) {
- List ret = new ArrayList();
- PersistenceManager pm = PMF.get().getPersistenceManager();
- String [] tokens = query.toLowerCase().split(" ");
- HashMap matches = new HashMap();
此方法返回SearchResult类的实例。查询字符串被转换为小写并被分割。对于每一个片段,你都将再次用StringPrefix计算前缀(以及原始单词) ,计算结果将用于查找包含这些关键词的文件:
- for (String token : tokens) {
- List lp = new StringPrefix().getPrefixes(token);
- for (Pair p : lp) {
- String q2 = "select from " + IndexToken.class.getName() + " where textToken == '" + p.str + "'";
- @SuppressWarnings("unchecked")
- List itoks = (List) pm.newQuery(q2).execute();
这个查询字符串可能看起来会觉得有点像标准的SQL语句 ,但不是。其实它们是JDO的查询语言( JDOQL ) 。它从一个在数据存储区持久化了的类里面取数据,而不是像SQL语句那样通过一个数据库的表名来提取数据。TextToken就是IndexToken 的一个持久化参数。这个JDOQL能返回数据存储区中所有textToken成员参数与查询关键字匹配的IndexToken实例。(51CTO编者注:JDOQL是JDO的查询语言;它有点象SQL,但却是依照Java的语法的。)
搜索功能的其它部分实现起来就没有什么难点了。只需要保存所有的文件匹配以及根据匹配度计算出的排名权重。
- for (IndexToken it : itoks) {
- Float f = matches.get(it.getDocumentUri());
- if (f == null) f = 0f;
- f += it.getRanking();
- matches.put(it.getDocumentUri(), f);
- }
- }
- }
这样我们就建立好了查询关键字与文件之间的映射关系,还知道了这些文件的URI以及排名权重。我们只需要把匹配结果从数据存储区里取出来就可以了(只有这样我们才有结果可显示), 然后把这些与关键字相匹配的文档按匹配度从高到低排列,就形成了搜索结果。
- for (String s : matches.keySet()) {
- String q2 = "select from " + Document.class.getName() + " where uri == '" + s + "'";
- @SuppressWarnings("unchecked")
- List itoks = (List) pm.newQuery(q2).execute();
- if (!itoks.isEmpty()) {
- int num_words = itoks.get(0).getNumWords();
- ret.add(new SearchResult(s, matches.get(s) / (float)(num_words), itoks.get(0).getTitle()));
- }
- }
- Collections.sort(ret, new ValueComparator());
- return ret;
- }
ValueComparato这个类是在源文件IndexToken.java里定义的,作用就是对搜索结果进行排序。
- static class ValueComparator implements Comparator {
- public int compare(SearchResult o1, SearchResult o2) {
- return (int)((o2.score - o1.score) * 100);
- }
- }
处理持久性数据存储:PMF类
我们这里所展示的PMF类代码是从Google的文档里复制过来的。这个类创建了一个私有的PersistenceManagerFactory实例并重用它。
- package com.kbsportal.persistence;
- import javax.jdo.JDOHelper;
- import javax.jdo.PersistenceManagerFactory;
-
- public final class PMF {
- private static final PersistenceManagerFactory pmfInstance =
- JDOHelper.getPersistenceManagerFactory("transactions-optional");
- private PMF() {}
- public static PersistenceManagerFactory get() {
- return pmfInstance;
- }
- }
示例程序的JSP页面
在写JSP页面时,我通常最开始是把Java代码嵌入到JSP页面里,到最后,我再把一些公用代码提取出来放到自定义的JSP标签库里,再给模型类添加上额外的行为。在这个程序里,我就不演示最后这几步清理工作了。
作为首页显示的index.jsp页面是用来显示系统里所有的文件的。它也包含了一些可选的调试代码(我通常会把这些调试代码注释掉),可以列出所有IndexToken类的实例(见 图2 ) 。index.jsp 这个文件最开头的部分引入了一些必要的类,定义了HTML头信息,然后还引入了menu.jsp,这个文件是用来作分页条的。
- %@ page import="javax.jdo.*, java.util.*,
- com.kbsportal.model.*,com.kbsportal.persistence.PMF" %>
- %@ page language="java" contentType="text/html; charset=ISO-8859-1"
- pageEncoding="ISO-8859-1"%>
- !DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
- "http://www.w3.org/TR/html4/loose.dtd">
- html>
- head>
- meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
- title>KBSportal Java App Engine Search Demo /title>
- /head>
- body>
- %@ include file="menu.jsp" %>

图2 列出所有文件:调试代码列出了所有IndexToken 实例,并显示了一些索引片段。
在IndexToken实例里我们已经见过JDOQL查询语句。在这里,查询语句返回所有文件对象:
- h2>All documents: /h2>
- %
- PersistenceManager pm = PMF.get().getPersistenceManager();
- Query query = pm.newQuery(Document.class);
- try {
- List Document> results = (List Document>)
- query.execute();
- if (results.iterator().hasNext()) {
- for (Document d : results) {
- System.out.println("key: "+d.getUri() +
- ", title: "+d.getTitle());
- %>
- h3> %=d.getTitle()%> /h3>
- p> %=d.getContent()%> /p>
- %
- }
- }
- } finally {
- query.closeAll();
- }
- %>
这里我们没有用JDOQL查询语句,而是用了一个查询对象来获取数据,这样我们所获得的查询结果就在其它JSP文件里也可以使用了,如果你只想获取某个特定标题的文件,那么通过下面的代码可以筛选结果:
- String title_to_find = "Dogs and Cats"
- query.setFilter("title == " + title_to_find);
index.jsp这个文件的后半部分也包含一些调试代码,在调试Web程序时我们可能会需要启用它。这段代码与之前那段调试代码几乎完全一样,只不过这段代码显示的是所有的IndexToken实例。
- query = pm.newQuery(IndexToken.class);
- try {
- List results = (List) query.execute();
- if (results.iterator().hasNext()) {
- for (IndexToken indexToken : results) {
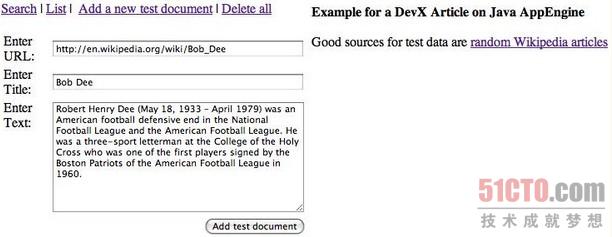
图3 用于向数据存储区添加文件的表单:这个JSP页面提供了一个可以向系统增加“文件” 的HTML输入框
new_document.jsp这个文件提供了一个可以向系统增加“文件” 的HTML输入框。(见 图3 ) 。下面的代码是从new_document.jsp截取出来的,它的作用是页面请求中是否包含表单数据。如果有的话,就向数据存储区里插入一个Document实例。
- %
- String url = request.getParameter("url");
- String title = request.getParameter("title");
- String text = request.getParameter("text");
- if (url!=null && title!=null && text!=null) {
- PersistenceManager pm =
- PMF.get().getPersistenceManager();
- try {
- Document doc = new Document(url, title, text);
- pm.makePersistent(doc);
- IndexToken.indexString(doc.getUri(), doc.getTitle() +
- " " + doc.getContent());
- } finally {
- pm.close();
- }
- }
- %>
makePersistent这个方法会被直接调用并把文件保存到数据存储区。静态方法IndexToken.indexString则把根据文件标题和内容生成的片段插入到数据存储区里。
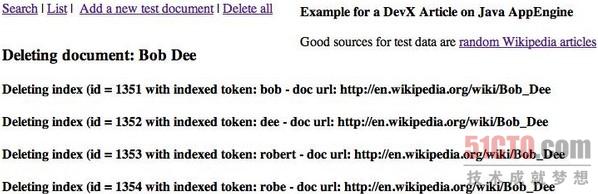
图4 从数据存储区里:删除所有文件和索引片段 示例应用程序需要一个简单的方法来清空数据存储区里所有测试“文件”数据
由于此示例程序是公开托管在Google那里,它需要一个简单的方法来清除文件存储区里所有的测试“文件”。delete_all.jsp这个jsp文件能从数据存储里删除所有的文件和索引片段(参见 图4 ) 。
- PersistenceManager pm = PMF.get().getPersistenceManager();
- Query query = pm.newQuery(Document.class);
- try {
- List results = (List)
- query.execute();
- if (results.iterator().hasNext()) {
- for (Document d : results) {
- pm.deletePersistent(d);
- }
- }
- } finally {
- query.closeAll();
- }
-
- query = pm.newQuery(IndexToken.class);
- try {
- List results = (List) query.execute();
- if (results.iterator().hasNext()) {
- for (IndexToken indexToken : results) {
- pm.deletePersistent(indexToken);
- }
- }
- } finally {
- query.closeAll();
- }
search.jsp的JSP的文件包含了一个HTML搜索框(参见 图5 ) 。以下是处理搜索操作的代码:
- String query = "";
- String results = "Results:";
- Object obj = request.getParameter("search");
- if (obj != null) {
- query = "" + obj;
- List hits = IndexToken.search(query);
- for (SearchResult hit : hits) {
- results += "" + hit + "";
- }
- }

图5 搜索结果: filesearch.jsp包含有一个HTML搜索框。
SearchResults类里新增的ToString 方法用于格式化搜索结果:
- public String toString() { return url +
- " - " + score + ": " + title; }
成本低廉的解决方案
Google App Engine为我们提供了一套无成本(或低成本)的解决方案。尽管对于某些Web应用服务来说,它可能并不是最佳的部署平台,但它绝对值得一试,而且绝对有资格成为我们开发工具箱里的备选项。
【App Engine相关文章推荐】
- 手把手教你在Google App Engine上运行PHP
- Google App Engine免费配额降低公告
- 开始您的第一个Google App Engine应用
- Google App Engine:Java SDK 1.2.1发布
- Google App Engine对Java支持情况一览
- Google App Engine:坚定的站在Java的中心
【责任编辑:杨赛 TEL:(010)68476606】
点赞
0








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
