一、背景
公司基于业务发展以及战略部署,需要实现在多个数据中心单元化部署,一方面可以实现多数据中心容灾,另外可以提升用户请求访问速度。需要保证多数据中心容灾或者实现用户就近访问的话,需要各个数据中心拥有一致的全量数据,如果真正实现用户就近读写,也就是实现真正的业务异地多活,数据同步是异地多活的基础,这就需要多数据中心间数据能够双向同步。
二、原生redis遇到的问题
1、不支持双主同步
原生redis并没有提供跨机房的主主同步机制,仅支持主从同步;如果仅利用redis的主从数据同步机制,只能将主节点与从节点部署在不同的机房。当主节点所在机房出现故障时,从节点可以升级为主节点,应用可以持续对外提供服务。但这种模式下,若要写数据,则只能通过主节点写,异地机房无法实现就近写入,所以不能做到真正的异地多活,只能做到备份容灾。而且机房故障切换时,需要运维手动介入。
因此,想要实现主主同步机制,需要同步工具模拟从节点方式,将本地机房中数据同步到其他机房,其他机房亦如此。同时,使用同步工具实现跨数据中心数据同步,会遇到以下一些问题。
(1)数据回环
数据回环的意思是,A机房就近写入的数据,通过同步工具同步到B机房后,然后又通过B机房同步工具同步回A机房了。所以在同步的过程中需要识别本地就近写入的数据还是其他数据中心同步过来的数据,只有本地就近写入的数据需要同步到其他数据中心。
(2)幂等性
同步过程中的命令可能因断点续传等原因导致重复同步了,此时需要保证同一命令多次执行保证幂等。
(3)多写冲突
以双写冲突为例,如下图所示:
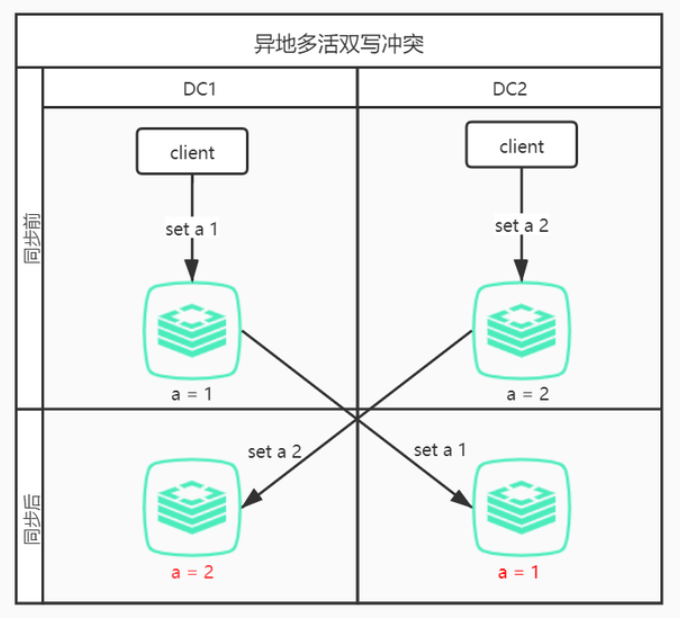
DC1写入set a 1,同时DC2写入set a 2,当这两条命令通过同步工具同步到对方机房时,导致最终DC1中保存的a为2,DC2中保存的a为1,也就是说两个机房最终数据不一致。
2、断点续传
针对瞬时的断开重连、从节点重启等场景,redis为了提高该场景下的主从同步效率,在主节点中增加了环形复制缓冲区,主节点往从节点写数据的同时也往复制缓冲区中也写入一份数据,当从节点断开重连时,则只需要通过复制缓冲区把断开期间新增的增量数据发送给从节点即可,避免了全量同步,提升了这些场景下的同步效率。
但是,该内存复制缓冲区一般来说不会太大,生产目前默认设置为64M,跨数据中心同步场景下,网络环境复杂,断线的频率和时长可能比同机房更频繁和更长;同时,跨数据中心同步数据也是为了机房级故障容灾,所以要求能够支持更长时间的断点续传,无限增大内存复制缓冲区大小显然不是一个好主意。
下面来看看我们支持redis跨数据中心同步的优化工作。
三、redis节点改造
为了支持异地多活场景,我们对原生redis代码进行了优化改造,主要包括以下几个方面:
1、对RESP协议进行扩展
为了支持更高效的断点续传,以及为了解决数据回环问题,我们在redis主节点中对每条需要同步给从节点的命令(大部分为写命令)增加了id,并且扩展了RESP协议,在每条相关命令的头部增加了形如#{id}\r\n形式的协议。
本地业务客户端写入的数据依然遵循原生RESP协议,主节点执行完命令后,同步到从节点的写命令在同步前会进行协议扩展,增加头部id协议;非本地业务客户端(即来自其他数据中心同步)写入的数据均使用扩展的RESP协议。
2、写命令实时写日志
为了支持更长时间的断点续传,容忍长时间的机房级故障,本地业务客户端写入的写命令在进行协议扩展后,会顺序写入日志文件,同时生成对应的索引文件;为了减少日志文件大小,以及提高通过日志文件断点续传的效率,来自其他数据中心同步过来的数据不写入日志文件中。
3、同步流程改造
原生redis数据同步分为全量同步和部分同步,并且每个主节点有一个内存环形复制缓冲区;初次同步使用全量同步,断点续传时使用部分同步,即先尝试从主节点环形复制缓冲区中进行同步,同步成功的话则同步完缓冲区中的数据后即可进行增量数据同步,如果不成功,则仍然需要先进行全量同步再增量同步。
由于全量同步需要生成一个子进程,并且在子进程中生成一个RDB文件,所以对主节点性能影响比较大,我们应该尽量减少全量同步的次数。
为了减少全量同步的次数,我们对redis同步流程进行改造,当部分同步中无法使用环形复制缓冲区完成同步时,增加先尝试使用日志rlog进行同步,如果同步成功,则同步完日志中数据后即可进行增量同步,否则需要先进行全量同步。
四、rLog日志设计
分为索引文件与日志文件,均采用顺序写的方式,提高性能,经测试与原生redis开启aof持久化性能一致;但是rlog会定期删除,原生redis为了防止aof文件无限膨胀,会定期通过子进程执行aof文件重写,这个对主节点性能比较大,所以实质上rlog对redis的性能相对于aof会更小。
索引文件和日志文件文件名均为文件中保存的第一条命令的id。
索引文件与日志文件均先写内存缓冲区,然后批量写入操作系统缓冲区,并每秒定期刷新操作系统缓冲区真正落入磁盘文件中。相比较于aof文件缓冲区,我们对rlog缓冲区进行了预分配优化,达到提升性能目的。
1、索引文件格式
索引文件格式如下所示,每条命令对应的索引数据包含三部分:
-
pos:该条命令第一个字节在对应的日志文件中相对于该日志文件起始位置的偏移
-
len:该条命令的长度
-
offset:该条命令第一个字节在主节点复制缓冲区中累积的偏移
2、日志文件拆分
为了防止单个文件无限膨胀,redis在写文件时会定期对文件进行拆分,拆分依据两个维度,分别是文件大小和时间。
默认拆分阈值分别为,当日志文件大小达到128M或者每隔一小时同时并且日志条目数大于10w时,写新的日志文件和索引文件。
在每次循环处理中,当内存缓冲区的数据全部写入文件时,判断是否满足日志文件拆分条件,如果满足,加上一个日志文件拆分标志,下一次循环处理中,将内存缓冲区数据写入文件之前,先关闭当前的索引文件和日志,同时新建索引文件和日志文件。
3、日志文件删除
为了防止日志文件数量无限增长并且消耗磁盘存储空间,以及由于未做日志重写、通过过多的文件进行断点续传效率低下、意义不大,所以redis定期对日志文件和相应的索引文件进行删除。
默认日志文件最多保留一天,redis定期删除一天以前的日志文件和索引文件,也就是最多容忍一天时间的机房级故障,否则需要进行机房间数据全量同步。
在断点续传时,如果需要从日志文件中同步数据,在同步开始前会临时禁止日志文件删除逻辑,待同步完成后恢复正常,避免出现在同步的数据被删除的情况。
五、redis数据同步
1、断点续传
如前所述,为了容忍更长时间的机房级故障,提高跨数据中心容灾能力,提升机房间故障恢复效率,我们对redis同步流程进行改造,当部分同步中无法使用环形复制缓冲区完成同步时,增加先尝试使用日志rlog进行同步,流程图如下所示:

首先,同步工具连接上主节点后,除了发送认证外,需要先通过replconf capa命令告知主节点具备通过rlog断点续传的能力。
-
从节点先发送psync runId offset,如果是第一次启动,则先发送psync ? -1,主节点会返回一个runId和offset
-
如果能够通过复制缓冲区同步,主节点给从节点返回 +CONTINUE runId
-
如果不能够通过复制缓冲区同步,主节点给从节点返回 +LPSYNC
-
如果从节点收到+CONTINUE,则继续接收增量数据即可,并继续更新offset和命令id
-
如果从节点收到+LPSYNC,则从节点继续给主节点发送 LPSYNC runId id
-
主节点收到LPSYNC命令后,如果能够通过rlog继续同步数据,则给从节点发送 +LCONTINUE runId;
-
从节点收到+LCONTINUE后,可以把offset设置为LONG_LONG_MIN,或者后续数据不更新offset;继续接收通过rlog同步的增量数据即可;
-
通过rlog同步的增量数据传输完毕后,主节点会给从节点发送 lcommit offset命令;
-
从节点在解析数据的过程中,收到lcommit命令时,更新本地offset,后续的增量数据继续增加offset,同时lcommit命令无需同步到对端(通过id<0识别即可,所有id<0的命令均无需同步到对端)
-
如果不能,此时主节点给从节点返回 +FULLRESYNC runId offset;后续进行全量同步;
2、幂等性
迁移工具为了提高性能,并不是实时往zk保存同步偏移offset和id,而是定期(默认每秒)向zk进行同步,所以当断点续传时,迁移工具从zk获取断线前同步的偏移,尝试向主节点继续同步数据,这中间可能会有部分数据重复发送,所以为了保证数据一致性,需要保证命令多次执行具备幂等性。
为了保证redis命令具备幂等性,对redis中部分非幂等性命令进行了改造,具体设计改造的命令如下所示:

注:list类型命令暂未改造,不具备幂等性
3、数据回环处理
数据回环主要是指,当同步工具从A机房redis读取的数据,通过MQ同步到B机房写入后,B机房的同步工具又获取到,再次同步到A机房,导致数据循环复制问题。
对于同步到从节点以及迁移工具的数据,会在头部添加id字段,针对不同来源的数据或者无需同步到远端的数据通过id来标识区分;本地业务客户端写入的数据需要同步到远端数据中心,分配id大于0;来源于其他数据中心的数据分配id小于0;一些仅用于主从心跳交互的命令数据分配id也小于0。
同步工具解析完数据后,过滤掉id小于0的命令,只需要向远端写入id大于0的数据,即本地业务客户端写入的数据。来源于其他数据中心的数据均不回写到远端数据中心。
4、过期与淘汰数据
目前过期与淘汰均由各数据中心redis节点分别独立处理,由过期与淘汰删除的数据不进行同步;即由过期与淘汰产生的删除命令其id分配为小于0,并由同步工具过滤掉。
(1)同步产生的问题
为什么不同步过去?因为在内存中hash表里面保存的数据没有标记数据中心来源,过期与淘汰的数据有可能来自于其他数据中心,如果来自于其他数据中心的数据被过期或淘汰并且又同步到远端其他数据中心,就会出现数据双写冲突的场景。双写冲突可能会导致数据不一致。
(2)不同步产生的问题
对于过期数据来说,不同步删除可能会导致不同数据中心数据显示不一致,但是一定会最终一致,且不会出现脏读;
对于淘汰数据来说,目前的不同步删除的方案,假如出现淘汰,会导致不同数据中心数据不一致;目前只有通过运维手段,比如充足预分配、及时关注内存使用率告警,来规避淘汰数据现象发生。
5、数据迁移
在redis集群模式中,一般是在发生横向扩容增加集群主节点数时,需要进行槽以及数据的迁移。
redis集群中数据迁移以槽为维度进行迁移,将槽中所有数据从源节点迁移到目标节点,然后将槽号标记为由新的目标节点负责,同时每迁移完一个Key,会在源节点中进行删除,将migrate命令替换为del命令;同时迁移数据是在源节点中给目标节点发送restore命令实现。
我们数据迁移的策略依然是,各个数据中心独立的完成扩容与数据迁移工作,迁移过程产生的del和restore命令不进行跨数据中心同步;把替换后的del命令和发送给目标节点的restore命令都分配小于0的id,于是同步过程中会由同步工具进行过滤掉。
六、redis性能
经测试,redis多活实例(默认开启rlog日志),相对于原生redis实例(开启aof持久化)性能基本一致;如下图所示:

注:以上图表使用redis benchmark进行压测,压测时,客户端和服务端在同一个机器上
七、待优化项
1、多写冲突
多个数据中心同时写,key冲突问题暂未解决。
后续解决方案为使用CRDT协议;CRDT(Conflict-Free Replicated Data Type)是各种基础数据结构最终一致算法的理论总结,能根据一定的规则自动合并,解决冲突,达到强最终一致的效果。
目前解决方案为业务对写入不同机房的数据进行拆分,以保证不会出现冲突。
2、list类型幂等性
五种基本类型里面,list类型大部分操作都是非幂等的,暂时未做幂等性改造优化。不建议使用或者业务自身保证使用list的数据操作幂等。
3、过期与淘汰数据一致性问题
正如前文所述,淘汰数据不进行跨数据中心同步会导致数据不一致,如果同步数据可能会出现同一个Key多写冲突,也可能出现数据不一致情况。
目前解决方案为业务尽量合理提前预估所需内存容量、充足预分配、及时关注内存使用率告警,来规避淘汰数据现象发生。
作者:罗明







 京公网安备 11010802041100号
京公网安备 11010802041100号