
【12月公开课预告】,入群直接获取报名地址
12月11日晚8点直播主题:人工智能消化道病理辅助诊断平台——从方法到落地
12月12日晚8点直播:利用容器技术打造AI公司技术中台
12月17日晚8点直播主题:可重构计算:能效比、通用性,一个都不能少
作者 | Just
出品 | AI科技大本营(ID:rgznai100)
距离3米甚至5米处,用户与智能音箱对话是一个典型的远场语音识别应用场景。
在远场环境下,目标声源距离拾音器较远致使目标信号衰减严重,加之环境嘈杂,干扰信号众多,最终导致信噪比较低,语音识别性能较差。为了提升远场语音识别准确率,一般会使用麦克风阵列作为拾音器。利用多通道语音信号处理技术,增强目标信号,提升语音识别精度。
不过,传统数字信号处理技术已经无法满足技术发展的需求,用深度学习技术来替代麦克阵列系统中的传统数字信号处理已经开始成为行业主流。但此前行业提出的解决方案需要和数字信号处理过程看齐的深度学习模型结构设计,严重影响了深度学习技术在该方向上的发挥和延伸,限制了深度学习模型的模型结构的演变,制约了技术的创新和发展。

在近日举办的百度大脑语音能力引擎论坛上,百度语音首席架构师贾磊提出了的基于复数卷积神经网络(Convolutional Neural Network,CNN)的语音增强和声学建模一体化端到端建模技术,它抛弃了数字信号处理学科和语音识别学科的各种先验假设,模型结构设计和数字信号处理学科完全脱钩,发挥了CNN网络的多层结构和多通道特征提提取的优势,同时充分发挥深度学习学科模型设计灵活自由的学科优势。
据介绍,相较于传统基于数字信号处理的麦克阵列算法, 该方法的错误率降低超过30%,目前已经被集成到百度最新发布的百度鸿鹄芯片中。
基于传统数字信号处理的技术
目前,语音识别技术在高信噪比场景下表现良好,但在低信噪比场景下,往往表现不稳定。
典型的语音识别场景如目标声源、非目标声源、拾音器和语音识别软件系统。以家居场景下的智能音箱产品为例,目标声源是朝音箱发出指令的用户;非目标声源是周围的声音干扰,例如家电噪声;拾音器和语音识别软件系统是智能音箱。在拾音器拾取到的信号中,来自目标声源的信号被称为目标信号,来自非目标声源的信号被称为干扰信号。目标信号强度与干扰信号强度的比值被称为信噪比。
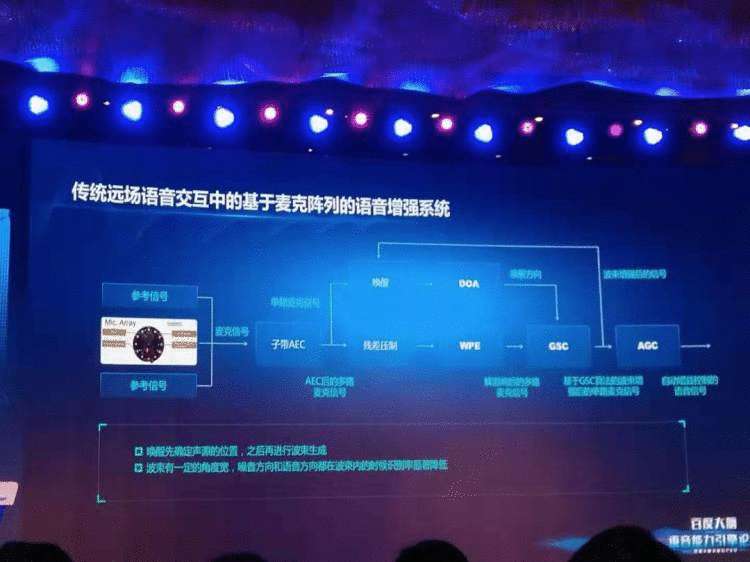
远场语音识别是一个典型的低信噪比场景,绝大多数在售的智能音箱产品系统目前所采用的多通道语音识别系统,都是由一个前端增强模块和一个后端语音识别声学建模模块串联而成的:
前端增强模块通常包括到达方向估计(DOA)和波束生成(BF)。DOA技术主要用于估计目标声源的方向,BF技术则利用目标声源的方位信息,增强目标信号,抑制干扰信号。常用的DOA技术有基于到达时延的定向算法,基于空间谱估计的定向算法等。

常用的BF技术有最小方差无畸变响应波束成形(MVDR BF),线性约束最小方差波束成形(LCMV BF)和广义旁瓣消除波束成形( GSC BF)等。这些BF技术本质上都是提升波束方向内的目标声源方向信号的信噪比,并尽可能的抑制波束外的非目标方向信号。前端增强模块处理后,将产生一路单麦克信号,输入到下面的后端语音识别声学建模模块中。
后端语音识别声学建模模块,会对这一路增强后的语音信号进行深度学习建模。这个建模过程完全类似于手机上的近场语音识别的建模过程,只不过输入建模过程的信号不是手机麦克风采集的一路近场信号,而是用基于麦克阵列数字信号处理技术增强后的一路增强信号。
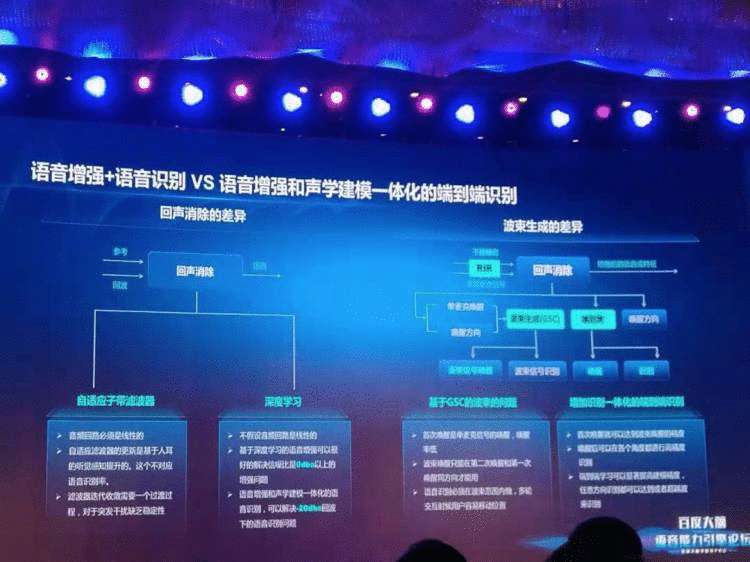
近些年,前端语音增强技术也逐渐开始用深度学习来做到达方向估计(DOA)和波束生成(BF),不少论文中和产品中也都提到了用深度学习技术来替代麦克阵列系统中的传统数字信号处理技术,也获得了一些提升。
但是上面这一类语音增强技术大都是采用基于MSE的优化准则,从听觉感知上使得波束内语音更加清晰,波束外的背景噪音更小。但是听觉感知和识别率并不完全一致。而且这种方法在噪音内容也是语音内容的时候,性能会急剧下降。另外,前端语音增强模块的优化过程独立于后端识别模块。该优化目标与后端识别系统的最终目标不一致。目标的不统一很可能导致前端增强模块的优化结果在最终目标上并非最优。
另外,由于真实产品场合,声源环境复杂,因此大多数产品都是先由DOA确定出声源方向后,再在该方向使用波束生成形成波束,对波束内的信号的信噪比进行提升,同时抑制波束外的噪音的干扰。这样的机制使得整个系统的工作效果都严重依赖于声源定位的准确性。同时用户第一次说唤醒词或者是语音指令的时候,第一次的语音很难准确利用波束信息,影响了首次唤醒率和首句识别率。
2017年,谷歌团队最早提出采用神经网络来解决前端语音增强和语音声学建模的一体化建模问题,文章从信号处理的Filter-and-Sum 方法出发,首先推导出时域上的模型结构,然后进一步推导出频域上的模型结构FCLP(Factored Complex Linear Projection),相比时域模型而言大幅降低了计算量。该结构先后通过空间滤波和频域滤波,从多通道语音中抽取出多个方向的特征,然后将特征送给后端识别模型,最终实现网络的联合优化。
谷歌提出的FCLP结构仍然是以信号处理方法为出发点,起源于delay and sum滤波器,用一个深度学习网络去模拟和逼近信号波束,因此也会受限于信号处理方法的一些先验假设。比如FCLP的最低层没有挖掘频带之间的相关性信息,存在多路麦克信息使用不充分的问题,影响了深度学习建模过程的模型精度。
再比如,beam的方向(looking direction)数目被定义成10个以下,主要是对应于数字信号处理过程的波束空间划分。这种一定要和数字信号处理过程看齐的深度学习模型结构设计,严重影响了深度学习技术在该方向上的发挥和延伸,限制了深度学习模型的模型结构的演变,制约了技术的创新和发展。最终谷歌学术报告,通过这种方法,相对于传统基于数字信号处理的麦克阵列算法,得到了16%的相对错误率降低。
基于复数CNN的语音增强和声学建模一体化端到端建模技术
贾磊在现场披露了基于复数卷积神经网络(Convolutional Neural Network,CNN)的语音增强和声学建模一体化端到端建模技术的更多细节。
具体而言,该模型底部以复数CNN为核心,利用复数CNN网络挖掘生理信号本质特征的特点,采用复数CNN, 复数全连接层以及CNN等多层网络,直接对原始的多通道语音信号进行多尺度、多层次的信息抽取,期间充分挖掘频带之间的关联耦合信息。在保留原始特征相位信息的前提下,同时实现了前端声源定位、波束形成和增强特征提取。该模型底部CNN抽象出来的特征,直接送入百度独有的端到端的流式多级的截断注意力模型中,从而实现了从原始多路麦克信号到识别目标文字的端到端一体化建模。整个网络的优化准则完全依赖于语音识别网络的优化准则来做,完全以识别率提升为目标来做模型参数调优。

除了模型结构外,该方法要想成功落地产品,还必须解决多路麦克的训练数据的获取和建模问题。要知道,目前商业语音识别系统的训练数据,主要依靠从数据公司买来的手机上录制的近场语音数据集合。远场多路麦克数据由于采集设备难于获取和周围噪音环境难于控制,而很少存在成规模的训练集合。

百度则研发了一种利用近场数据来模拟生成远场训练数据的方法:模拟一路信号传输到多路麦克风的信号传输过程,并施加混响噪音和环境加性噪音。利用该方法,他们做出数百万远场房间环境下的远场多路麦可信号的模拟数据,并且成功训练出可以达到产品上线级别的一体化声学模型。
论坛上,搭载了该项语音技术的三款基于鸿鹄语音芯片的硬件产品全新发布:芯片模组 DSP芯片+Flash、Android 开发板DSP芯片+ RK3399、RTOS开发板DSP芯片+ESP32。此外,贾磊还描述了基于鸿鹄语音芯片的端到端软硬一体远场语音交互方案以及全新发布的针对智能家居、智能车载、智能IoT设备的三大场景解决方案。
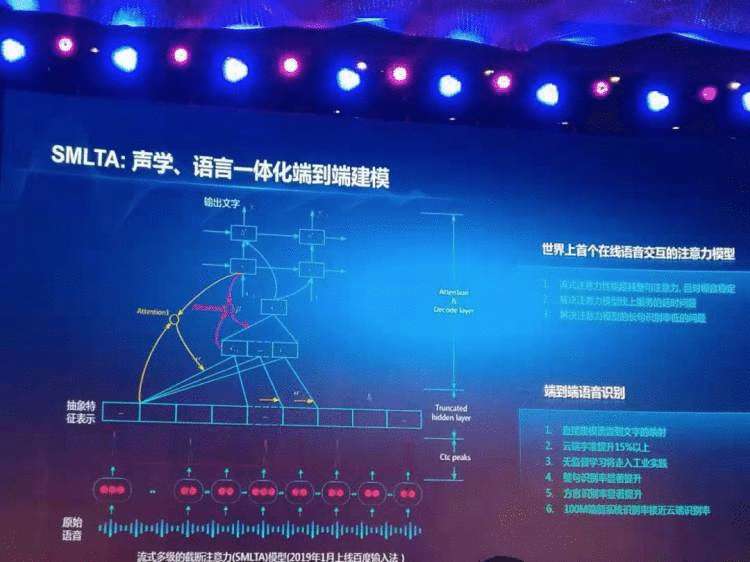
此外,今年年初百度提出截断注意力模型SMLTA,使得句子的整句识别率、方言的识别以及中英文混合的识别率显著提升,实现了语音识别领域注意力模型的大规模工业在线产品落地。
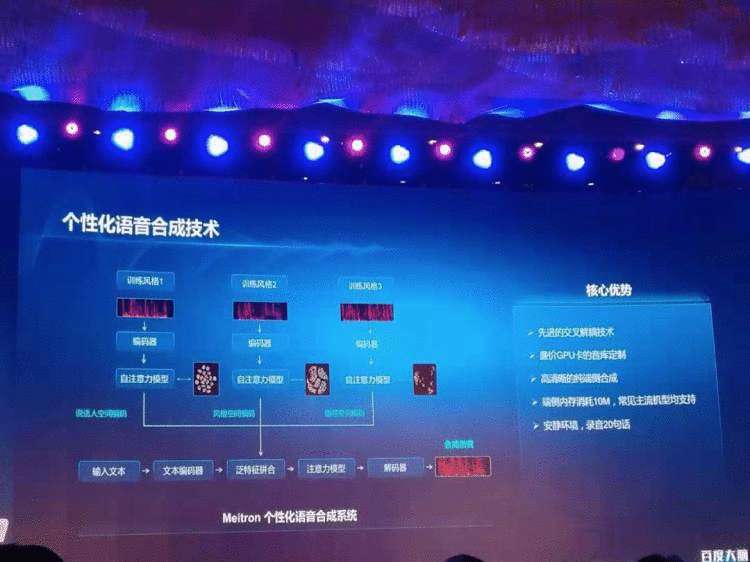
而在语音合成领域,百度首创Tacotron+wavRNN联合训练,大幅提升云端合成速度。百度地图20句话即可录制语音导航的技术基于百度独创的风格迁移技术Meitron模型,特点主要体现在音色转换、多情感朗读和韵律迁移三个方面,从而大大降低语音合成的门槛。
基于深度学习和产业应用加速突破,百度的语音技术已落地到百度App,百度地图、小度音箱,百度输入法等产品。百度CTO王海峰也在会上宣布,百度大脑通过AI开放平台已开放228项技术能力,接入开发者超过150万,而语音技术日均调用量则超过100亿次。
推荐阅读











 京公网安备 11010802041100号
京公网安备 11010802041100号