我正在尝试编译来自大型Dymola模型的生成C代码。生成的代码与人类编写的代码不同,存在许多展开的循环,大量使用了宏,手动索引了巨大的数组,最重要的是源文件很大(> 1e6行)。
当使用O2或编译这些源文件时O3,我的编译时间变得非常高:每个文件10至30分钟。Clang和GCC都有。我不能很好地遵循生成的汇编代码,因此我不确定优化的质量。通过不生成调试信息或关闭警告可以减少编译时间,但是与关闭优化相比,这些警告很小。在运行时方面,O0和之间有明显的区别O2,所以我不能证明这样做是合理的。使用进行编译时-ftime-trace,我可以看到Clang前端负责90%以上的时间。据称,该过程不是内存瓶颈,它似乎完全受CPU限制htop。
我可以做一些预处理来改善编译时间吗?将源文件分成较小的块会提高性能,为什么?编译器是否设计为可以处理这些巨大的源文件?还有其他我应该注意的编译选项吗?
令人惊讶的是,Windows上的MSVC /O2花费的时间只是Clang和GCC的一小部分。
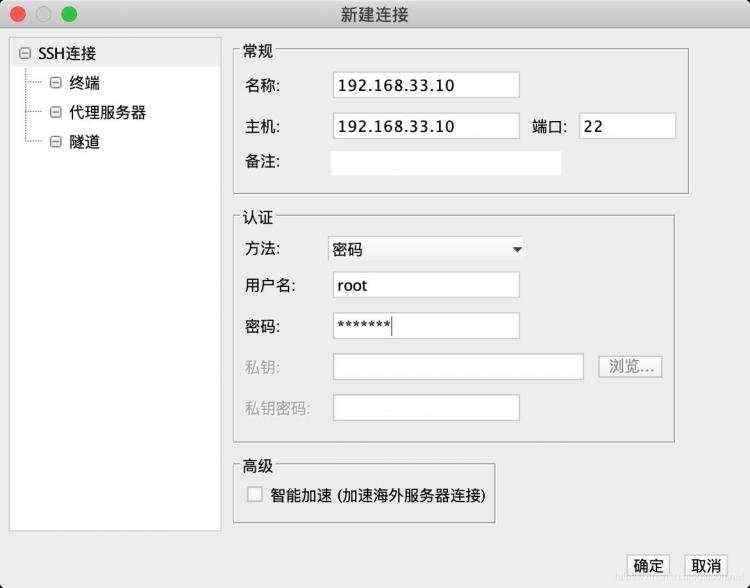
编译器参数示例: clang -m64 -Wno-everything -c -D_GNU_SOURCE -DMATLAB_MEX_FILE -ftime-report -DFMI2_FUNCTION_PREFIX=F2_Simulations_SteadyState_SteadyState2019MPU_ -DRT -I/opt/matlab/r2017b/extern/include -I/opt/matlab/r2017b/simulink/include -I/mnt/vagrant_shared/
平台:在虚拟机VM上运行的CentOS 7。Clang 7,GCC 4.8(由于其他要求,我坚持使用这些旧版本)。









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有