作者:ACHEn大魔王 | 来源:互联网 | 2023-08-23 10:24
>>《用户画像:方法论与工程化解决方案》是一本从技术、产品和运营 3 个角度讲解如何从 0 到 1 构建用户画像系统的书,欢迎参与文末赠书活动 。
开发画像后的标签数据,如果只是“躺在”数据仓库中,并不能发挥更大的业务价值。只有将画像数据产品化后才能更便于业务方使用。在本文中,Web端展示的数据都读取自MySQL这类的关系型数据库,MySQL中存储的数据源自Hive加工后,通过Sqoop同步的结果集。
本问主要介绍用户画像产品化后主要可能涵盖到的功能模块,以及这些功能模块的应用场景。
01 即时查询
即时查询功能主要面向数据分析师。将用户画像相关的标签表、用户特征库相关的表开放出来供数据分析师查询。
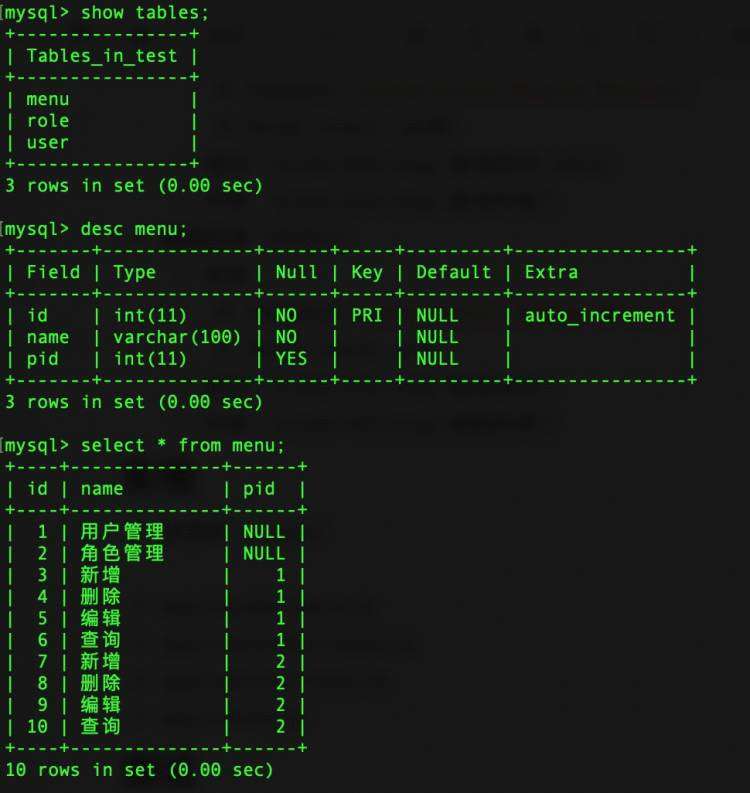
Hive存储的相关标签表,包括userid和COOKIEid两个维度。
- dw.userprofile_attritube_all:存储用户人口属性维度的标签。
- dw.userprofile_action_all:存储用户行为属性维度的标签。
- dw.userprofile_consume_all:存储用户消费商品维度的标签。
- dw.userprofile_riskmanage_all:存储风控维度的标签。
- dw.userprofile_social_all:存储社交维度的标签。
- dw.userprofile_COOKIElabel_map_all:对每个COOKIEid身上的标签做汇聚后输出。
- dw.userprofile_usergroup_labels_all:用户人群分组表。查询应用到业务系统下面,对应人群id里面的用户数据,在营销效果测试中有广泛应用。例如业务人员针对圈定的某人群进行短信营销,数据分析师在分析营销效果时,可以查询这张表中该人群id下面的用户id数据,进一步分析这批用户在后续的活跃和订单方面的表现。
- dw.COOKIE_feature_event_append:用户特征库表,存储用户每一天每一次行为带来的标签数据,可用于挖掘用户行为特征及偏好。
数据分析师在日常分析与用户相关维度的数据时,可查询相应表中的数据,这里通过两个案例来介绍。
对于存储COOKIEid维度数据的标签表dw.userprofile_COOKIElabel_all,如果提取带有男性标签
(id=ATTRITUBE_C_01_001)的用户群体以备后续应用,可使用如下查询语句:
select COOKIEid
from dw.userprofile_attribube_all
where data_date = ‘20190101’
and labelid = ‘ATTRITUBE_C_01_001’ # 分区的标签主题是性别
limit 10
在该查询中,限制查询的日期分区为当前日期前一天,查询标签id为男性用户。
查询结果如下:

对于存储userid维度的聚合标签的表dw.userprofile_userlabel_map_all,如果已知一批用户的id,可查询出该批用户身上带有的全量标签。
select userid,userlabels
from dw.userprofile_userlabel_map_all
where data_date = ‘20181201’
and userid in (‘44463729’,’4069220’,’20101029’,’54597979’,’19816511’)
查询结果如下:

关于用户特征库相关数据的查询和应用方式在4.5节中有详细介绍。面向数据分析师查询时,只需要开放出表结构及详细字段说明即可。
02 标签视图与标签查询
标签视图与标签查询功能主要是面向业务人员使用,如图1所示。

图1 平台标签视图
在标签视图板块中,层级化地展示了目前已经上线使用的全部用户标签。用户可以层级化地通过点击标签,查看每个标签的详细介绍。
在图1中,当点击“用户属性”这个一级类目时,可进入到“自然性别”“购物性别”“用户价值”等二级类目,点击“自然性别”二级类目,可看到展开的“男性”“女性”三级标签,进一步点击三级标签“男性”或是“女性”,可以查看该标签的详细介绍,如图2所示。

图2 标签元数据视图
在该标签详情页中,可以查看人口属性这一个类目下面各个标签的覆盖用户量情况。
每天通过对标签的覆盖用户量进行监控,可以作为预警使用。例如:某天某个标签的覆盖用户量与前一天相比出现了很大比例的波动,需要排查该标签当日ETL作业是否出现异常或是否因业务上的操作导致标签量级的波动。
在标签查询模块中,如图3所示,通过输入用户对应的userid或COOKIEid,可以查看该用户的属性信息、行为信息、风控属性等多个维度的信息,多方位了解一个用户的特征。关于如何存储这种数据结构,在3.1.3节中有介绍,即通过将每个用户对应的标签聚合成map字段格式,如{‘key1’:‘value1’,‘key2’:‘value2’},进行存储。

图3 用户标签查询
03 元数据管理
标签编辑管理功能主要是面向数据开发人员。数据开发人员在开发完标签后,需要将标签录入元数据进行管理,如图4所示。
标签的编辑管理也即对标签做元数据管理,将在Web端编辑表单中填写的数据存储到MySQL等关系型数据库中。用户在该板块中点击“添加标签”按钮或对已添加的标签进行编辑操作,可设置该标签的元数据相关信息(如图5所示)。
可在该页面中编辑标签相关的元数据,包括标签id、名称、开发人员、标签类型、标签描述、数据源等,方便业务人员在应用时理解该标签的业务意义以及其负责人员。对应的元数据信息维护在关系型数据库中,需要创建一些关键字段,如图6所示。通过Navicat等图形化操作界面可查看录入的元数据信息,如图7所示。

图4 标签编辑管理–添加标签

图5 标签编辑管理–编辑元数据

图6 标签元数据字段

图7 通过Navicat查看录入的标签元数据
04 用户分群功能
用户分群功能主要是面向业务人员使用。产品经理、运营、客服等业务人员在应用标签时,可能不仅仅只查看某一个标签对应的人群情况,更多地可能需要组合多个标签来满足其在业务上对人群的定义。例如:组合“近30日购买次数”大于3次和“高活跃”“女性”用户这3个标签定义目标人群,查看该类人群覆盖的用户量,以及该部分人群的各维度特征。下面介绍产品上的实现方式。
在“用户分群”板块下,点击“新建人群”按钮或编辑之前已添加的分组(见图8),进入详情页可自定义涵盖某些标签的人群(如图9所示)。

图8 用户自定义分群板块

图9 用户自定义分群编辑
在自定义编辑用户分群时,对于有统计类标签,可以自定义筛选该标签的取值范围,如图9中“近30日购买次数”标签,业务人员可筛选该标签的数值。对于分类型标签,如图9中的“活跃度”标签,业务人员选中该标签即可圈出包含该标签的用户。“人群名称”和“人群描述”表单用于业务人员描述该人群在业务上的定义,方便后续查看、应用该人群。下面详细介绍一下“人群减法”功能的应用点。
在Web产品端,业务方通过组合多个标签来透视分析人群、圈定人群,并选择推送到的业务系统;在跑ETL任务时,即图9中“数据计算层逻辑”,首先需要从MySQL等关系数据库中读取业务方圈定的人群规则,即标签和标签的权重值,然后将标签规则组合成SQL语句,跑Spark任务将对应的人群计算出来,写入Hive中;在服务层应用时,即图7-9中“输出到服务端”,根据不同的业务系统,分别执行对应的数据同步脚本,将上个过程中计算出来存储到Hive中的各人群数据同步到对应的业务系统中。
05 人群分析功能
人群分析功能主要是面向业务人员、数据分析师、产品经理等人群使用。
人群分析提供根据现有用户标签圈定用户群的功能,同时业务方可以从多个维度(如地域、性别、年龄、消费水平等)进一步分析该批用户群的特征,从而为精细化运营提供支持。和上一小节讲的用户人群功能相似,人群分析功能首先也需要组合标签圈定用户群体,不同之处在于多维透视分析功能支持从多个维度去分析圈定用户群体的特征,而用户分群功能侧重的是将筛选出来的用户群推送到各业务系统中,提供服务支持。
下面介绍人群分析功能和产品形态。首先和用户分群功能一样,需要组合标签筛选出目标用户群体(如图10所示)。
图10 创建需要分析的人群
创建好目标用户群体后,在“对比维度”选择菜单中选择需要分析该批用户的维度(如图11所示),例如这里选择的是下单次数和活跃度。“对比维度”列表中的可选标签也是用户属性、用户行为栏目中已经构建的标签。

图11 对目标人群选择需要分析的维度
选择好透视分析的维度,下面就可以看到刚才筛选出来的用户群在活跃度和下单次数上的表现了(如图12所示)。

图12 从多维度分析目标人群特征
除了能透视分析单个人群在多个维度上的特征,多维透视分析功能还可以支持同时分析多个人群在不同维度上的表现。业务人员根据不同业务规则同时创建两个人群,然后筛选对比维度,可以从多个维度上对比分析这两个人群的特征(如图13所示)。

图13 对比分析两个人群特征
本文介绍了用户画像产品化主要涵盖的功能模块以及这些模块的应用场景。用户画像产品化是把数据应用到业务服务中的一个重要出口,业务人员熟知业务,但对数据不了解。通过这种产品可视化的方式,方便业务人员分析用户群特征,将分析后的用户群推送到对应业务系统中触达用户,更方便、快捷地将数据赋能到业务场景中去。本章通过对产品功能和形态的详细剖析,为数据产品、运营、客服等业务人员提供一种产品规划和标签应用于服务的解决方案。
本文摘编于《用户画像:方法论与工程化解决方案》,经出版方授权发布。
关于作者:
赵宏田,资深大数据技术专家,在大数据、数据分析和数据化运营领域有多年的实践经验,擅长Hadoop、Spark等大数据技术,以及业务数据分析、数据仓库开发、爬虫、用户画像系统搭建等。开源项目的贡献者,知乎专栏作者,撰写了大量专业文章,广受好评。
赵宏田老师将于 10 月 31 日晚 20 点,与大家分享“画像系统的开发方案及产品方案”,欢迎大家扫码准时观看。

点击图片观看直播
【赠书福利】
关注公众号"OSC 开源社区",聊天窗口回复“抽奖”二字即可参与(邀请好友助力可提高中奖概率),我们将从参与者中随机挑取 10 名幸运读者,分别包邮赠送一本《用户画像:方法论与工程化解决方案》。活动截止到 11 月 04 日 12:00 整,快来参与吧~





 京公网安备 11010802041100号
京公网安备 11010802041100号