点击左上方蓝字关注我们

【飞桨开发者说】于航:网名灰酱。飞桨开发者技术专家(PPDE),一名热爱推理部署的飞桨开发者!现任飞桨公众号小编。

大家好,我是飞桨公众号小编,灰酱~
前几天给大家介绍了来自日本算法竞赛网站signate柠檬外观分类的比赛,给大家介绍了飞桨框架2.0从训练到部署的流程,以及如何使用飞桨框架2.0实现一个分类任务。今天继续为大家讲解如何把飞桨框架2.0的模型部署到嵌入式、移动端设备上。
我们先回顾下使用Paddle Lite对模型进行推理部署流程的两个阶段:
模型训练阶段:
主要解决模型训练,利用标注数据训练出对应的模型文件。(PS:面向端侧进行模型设计时,需要考虑模型大小和计算量)
模型部署阶段:
模型转换:
如果是Caffe、TensorFlow或ONNX平台训练的模型,需要使用X2Paddle工具将模型转换到飞桨格式。
(可选)模型压缩:
主要优化模型大小,借助PaddleSlim提供的剪枝、量化等手段降低模型大小,以便在端上使用。
将模型部署到Paddle Lite。
在终端上通过调用Paddle Lite提供的API接口(C++、Java、Python等API接口),完成推理相关的计算。
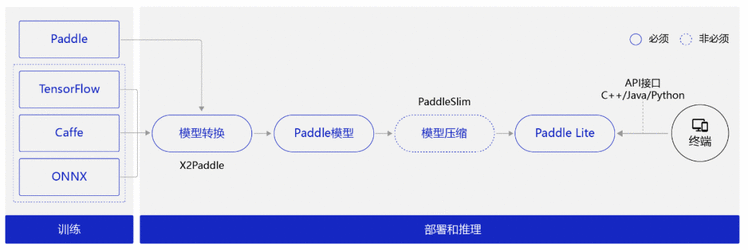
图1 推理部署流程
通过前几天的训练,我们已经得到了可以用于部署的静态图模型,现在我们来开始今天的部署之旅吧!
模型部署阶段
Paddle Lite部署模型工作流
环境准备&跑通Demo
使用自己的模型
opt工具
部署流程详解(图像预处理为重点)
说在最前面:
深度学习的训练调优过程与部署是可以分工来做的。擅长调参的人进行模型调优,擅长部署的人进行模型部署。
对于部署来说,可以不关注这个模型是怎么来的。此时,问题就来了:对于部署在coding的时候需要重点关注是什么呢?
两点:
模型的输入与输出
模型的预处理与后处理
如果你想了解一个陌生模型的输入与输出,该怎么做呢?建议大家使用VisualDL的模型可视化功能观察模型的输入与输出。
如果你想了解一个陌生模型的预处理、后处理,该怎么做呢?以PaddleHub上的预训练模型为例,我们可以去阅读这个模型在PaddleHub上的源代码,从而了解它的预处理、后处理。
如果你无法得知模型的输入与输出、预处理与后处理,那么你是无法进行模型部署的。
部署时预处理、后处理,与训练时对齐,这是部署时的难点。
部署的原则,即与训练对齐。
1.1 Paddle Lite部署模型工作流
使用Paddle Lite部署模型包括如下步骤:
准备Paddle Lite推理库。
Paddle Lite新版本发布时已提供预编译库,因此无需进行手动编译,直接下载编译好的推理库文件即可。
生成和优化模型。
先经过模型训练得到Paddle模型,一般需要通opt离线优化工具做模型优化,得到Paddle Lite nb模型(Paddle Lite移动端轻量化模型)。
如果是Caffe,、TensorFlow或ONNX平台训练的模型,需要使用X2Paddle工具将模型转换到Paddle模型格式,再使用opt优化。
构建推理程序。
使用前续步骤中编译出来的推理库,优化后模型文件,首先经过模型初始化,配置模型位置、线程数等参数,然后进行图像预处理,如图形转换、归一化等处理,处理好以后就可以将数据输入到模型中执行推理计算,并获得推理结果。
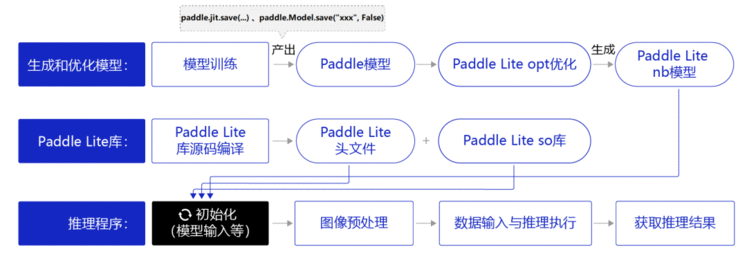
图2 部署模型工作流
1.2 Paddle Lite移动端和嵌入端的模型部署
Paddle Lite提供多平台下的示例工程Paddle-Lite-Demo,其中包含Android、iOS和Armlinux平台,涵盖人脸识别、人像分割、图像分类、目标检测、基于视频流的人脸检测+口罩识别多个应用场景。
本项目以ARMLinux平台为例,Paddle Lite部署的流程是:
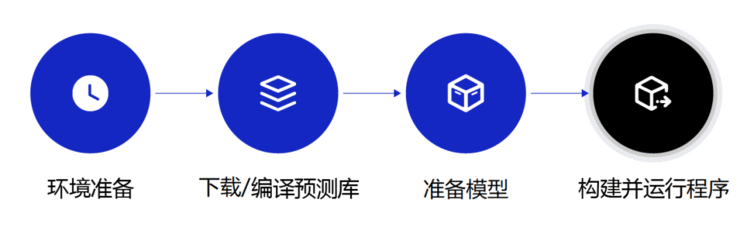
图3 Paddle Lite部署的流程
准备环境。
安装好CMake、OpenCV等工具。
(详情见下文讲述)
下载推理库(不建议自行源码编译)。
从Github下载Paddle Lite预编译库,供程序调用Paddle Lite完成推理。
准备模型。
使用opt工具对模型进行优化,如算子融合、内存复用、类型推断、模型格式变换等等。
构建并运行程序。
使用前续步骤中编译出来的推理库、优化模型,完成Android/iOS平台上的目标检测应用。
我们已为用户准备好了完整的Android/iOS工程示例,方便用户体验和二次开发。
1.3 Paddle Lite部署实战——环境准备&跑通Demo
部署部分代码已经上传至Github:
https://github.com/hang245141253/lemon
首先准备硬件开发板(RK3399,树莓派4B、树莓派3B等ARMLinux开发板,64位系统,如果使用32位系统则只能使用C++部署,因为我没准备Python 32位的pip,需要的同学得自行源码编译)。
环境准备
C++准备环境:
主要安装OpenCV3.2.0(推荐3.2)与CMake3.10
sudo apt-get update
sudo apt-get install gcc g++ make wget unzip libopencv-dev pkg-config
wget https://www.cmake.org/files/v3.10/cmake-3.10.3.tar.gz
tar -zxvf cmake-3.10.3.tar.gz
cd cmake-3.10.3
./configure
make
sudo make install
Python环境准备:
主要是安装,numpy(1.13.3),Pillow(8.1.0),matplotlib(2.1.1),OpenCV(3.2.0)(推荐3.2)。以上工具版本号仅供参考,非必须对齐。
优先推荐通过pip3 install xxx安装numpy,Pillow,matplotlib,OpenCV。可以用如下命令安装:
pip install numpy==1.13.3 pillow==8.1.0 matplotlib==2.1.1 opencv==3.2.0
安装matplotlib,OpenCV可能遇到报错,无需慌张,可apt install python3-dev后再次使用pip安装。若依旧不成功可使用apt install python3-matplotlib 、apt install python3-opencv安装。
配置好环境后稍后克隆一份部署Lemon源码,进入cd ./lemon/wheels文件夹后pip3 install paddlelite-2.8rc0-cp36-cp36m-linux_aarch64.whl(根据自己的Python版本选择,提供了Python2.7,3.5,3.6,3.7的包)。
此类问题多百度,多参考其他人遇到问题解决的方式。当自己这类问题解决后,也写一篇博客来帮助其他人吧!
跑通Demo
首先克隆一份部署Lemon源码
git clone https://github.com/hang245141253/lemon.git
Lemon部署代码结构如下图所示:
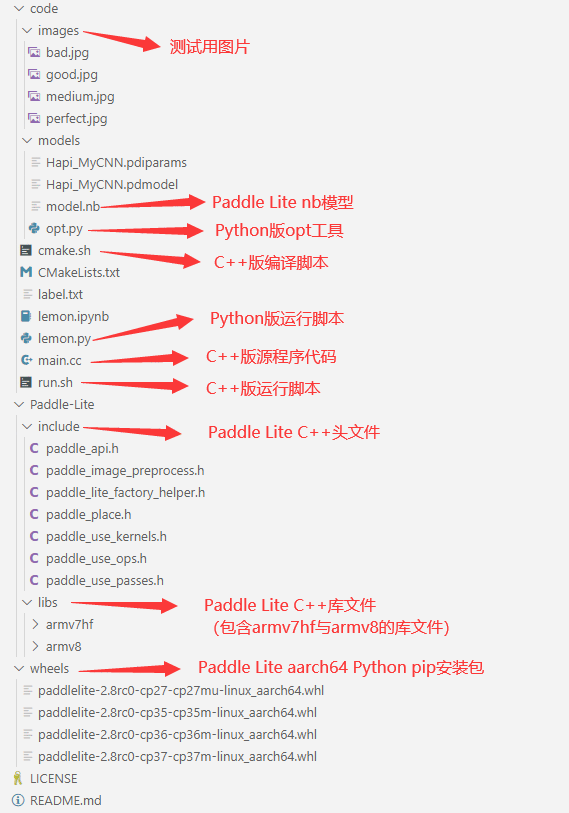
图4 Lemon部署代码结构
部署代码将C++与Python接口代码放入了同一文件中。如果想在Demo的基础上,换新的模型或者改变应用模型的方式,只要替换自己的model.nb或者修改main.cc、lemon.py即可。
如果你已经配置好了对应接口的环境,接下来就可以运行代码了!
C++运行代码:
cd ./lemon/code进入code文件夹里后,执行sh cmake.sh会生成build文件夹,目标程序在build文件夹。在code目录下继续执行sh run.sh则开始执行部署程序。
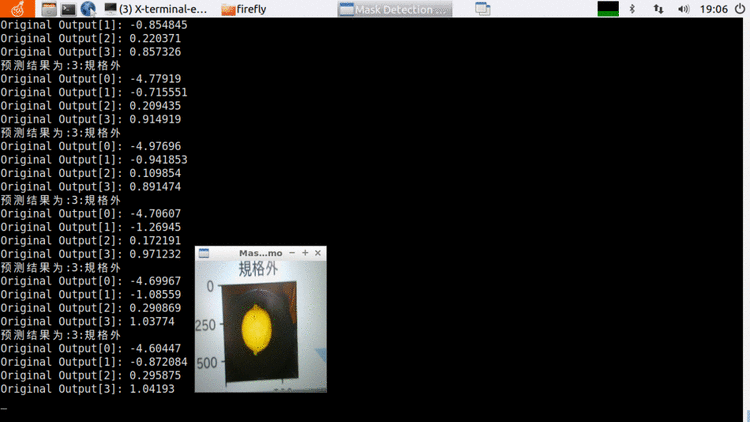
图5 C++运行演示
Python运行代码:
cd ./lemon/code进入code文件夹里后,执行python3 lemon.py运行程序。
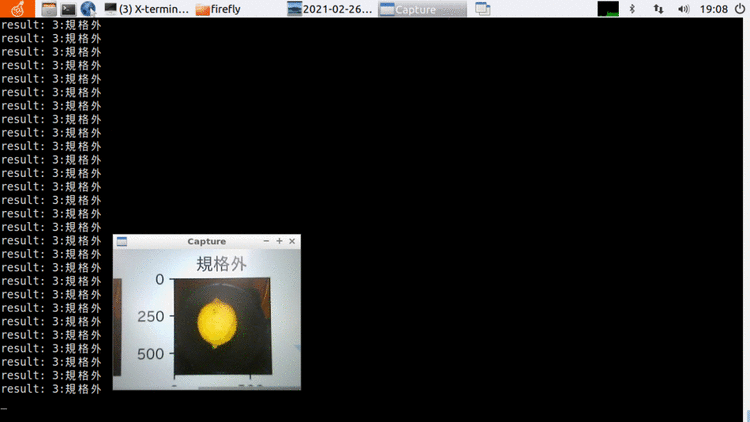
图6 Python运行演示
1.4 Paddle Lite部署实战——使用自己的模型
经过了刚才的实践,我们已经跑通了部署的流程,接下来教会大家如何部署自己的模型。使用opt工具将Paddle模型转化成Paddle Lite nb模型,这里已经将opt工具作为数据集形式上传到了Notebook中,只需执行如下代码即可完成模型转化。
opt_linux --model_file=Hapi_MyCNN.pdmodel --param_file=Hapi_MyCNN.pdiparams --optimize_out=model
# 使用opt工具将Paddle模型转化成Paddle Lite nb模型
!./data/data71619/opt_linux --model_file=Hapi_MyCNN.pdmodel --param_file=Hapi_MyCNN.pdiparams --optimize_out=model
然后下载模型文件 到开发板上,接着cd ./lemon/code/models进入目录,替换模型文件即可,无需修改代码。
到开发板上,接着cd ./lemon/code/models进入目录,替换模型文件即可,无需修改代码。
1.5 Paddle Lite部署实战——opt工具
关于opt离线优化工具
这个时候你可能会问,opt工具是什么?直接运行Paddle的模型不好吗?首先看一下Paddle Lite的架构图:
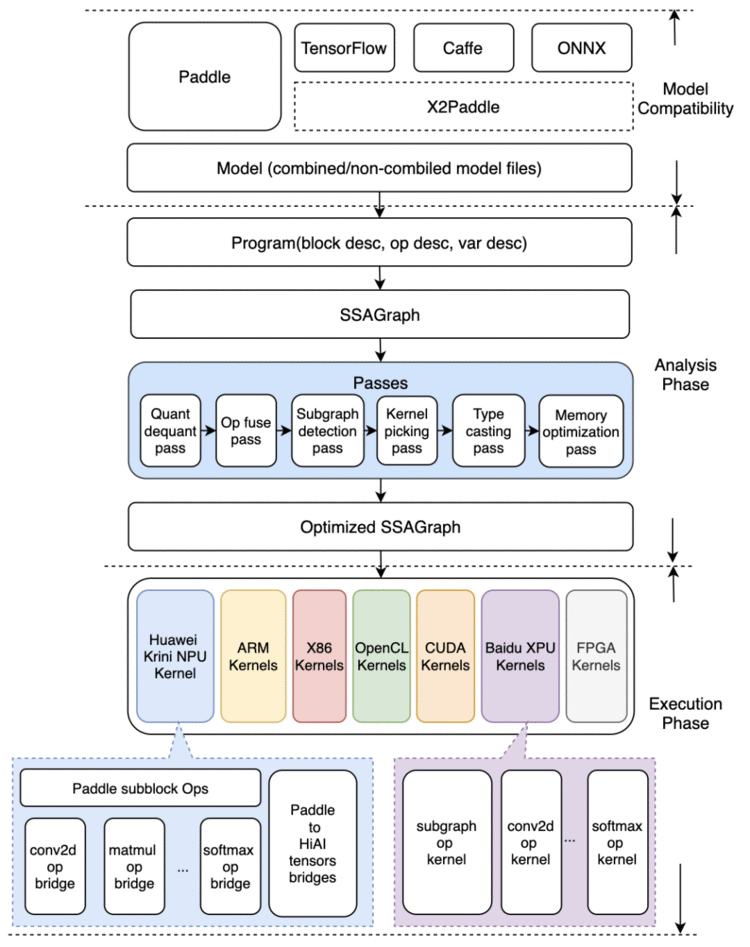
图7 Paddle Lite的架构图
看完是不是有点一脸懵逼?不要慌,这个架构图跟opt工具可是有着千丝万缕的关系。
模型优化阶段和预测执行阶段的隔离设计:
我们关注图右边的Analysis Phase 和 Execution Phase。
Analysis Phase为模型优化阶段,输入为Paddle的推理模型,通过Lite的模型加速和优化策略对计算图进行相关的优化分析,包含算子融、计算裁剪、存储优化、量化精度转换、存储优化、Kernel优选等多类图优化手段。优化后的模型更轻量级,在相应的硬件上运行时耗费资源更少,并且执行速度也更快。
Execution Phase为预测执行阶段,输入为优化后的Lite模型,仅做模型加载和预测执行两步操作,支持极致的轻量级部署,无任何第三方依赖。
Lite设计了两套 API 及对应的预测库,满足不同场景需求:
CxxPredictor同时包含Analysis Phase和Execution Phase,支持一站式的预测任务,同时支持模型进行分析优化与预测执行任务,适用于对预测库大小不敏感的硬件场景。
MobilePredictor只包含Execution Phase,保持预测部署和执行的轻量级和高性能,支持从内存或者文件中加载优化后的模型,并进行预测执行。
上文的描述,简单来说就是CxxPredictor用来运行Paddle模型,MobilePredictor用来运行Lite的nb模型。而CxxPredictor与MobilePredictor差了一个Analysis Phase,我们的Opt工具就是把Analysis Phase这部分进行了离线优化。
这样做的好处是:功能上,CxxPredictor = Opt + MobilePredictor。 同样的模型,经过Opt优化过的nb模型,移动端的 MobilePredictor 更小、更轻量化。
为了使优化过程更加方便易用,Paddle Lite提供了多种策略来自动优化原始的训练模型,其中包括量化、子图融合、混合调度、Kernel优选等等方法。Paddle Lite提供的Opt工具可以自动完成优化步骤,输出一个轻量的、最优的可执行模型。
所以,官方也是不推荐使用Paddle Lite直接运行Paddle模型,上文所述“一般需要通Opt离线优化工具做模型优化”,也是这个原因。
1.6 Paddle Lite部署实战——部署流程详解
不管什么编程接口,使用Paddle Lite基本是5个流程:
创建config信息
创建predictor预测器
设置数据输入(输入前需要准备数据预处理)
执行预测
获取输出数据(输出后需要准备数据后处理)
然而在部署上的难点并非是调用Lite接口,而是部署时的预处理与后处理如何与训练时对齐。这块需要对OpenCV、Pillow这些API接口有一定的了解,需要对图像处理有一定的了解。
后面内容在简单介绍Python接口与C++接口使用流程后,将重点讲述两种接口下的预处理与后处理。
Python部署详解:
Python部署十分简单,但是推理速度上可以明显感受到速度慢于C++部署。在安装好pip3 install paddlelite-2.8rc0-cp36-cp36m-linux_aarch64.whl后,就可以进入Python解释器from paddlelite.lite import *开始编程了。简单流程:
from paddlelite.lite import *# 设置config信息
config = MobileConfig()
config.set_model_from_file(/YOU_MODEL_PATH/mobilenet_v1_opt.nb)# 创建predictor
predictor = create_paddle_predictor(config)# 从图片读入数据
image = Image.open('./example.jpg')
resized_image = image.resize((224, 224), Image.BILINEAR)
image_data = np.array(resized_image).flatten().tolist()# 设置输入数据
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, 224, 224])
input_tensor.set_float_data(image_data)# 执行预测
predictor.run()# 得到输出数据
output_tensor = predictor.get_output(0)
print(output_tensor.shape())
print(output_tensor.float_data()[:10])
以上为Python接口基本使用流程,具体接口参考Paddle Lite Python API文档。
预处理部分:
Python的预处理部分很简单,下面代码直接套用了上节模型测试中的预处理代码。
def preprocess(img):'''预测图片预处理'''#resizeimg = img.resize((224, 224), Image.BILINEAR) #Image.BILINEAR双线性插值img = np.array(img).astype('float32')# HWC to CHW img = img.transpose((2, 0, 1))#Normalizeimg = img / 255 #像素值归一化mean = [0.31169346, 0.25506335, 0.12432463] std = [0.34042713, 0.29819837, 0.1375536]img[0] = (img[0] - mean[0]) / std[0]img[1] = (img[1] - mean[1]) / std[1]img[2] = (img[2] - mean[2]) / std[2]return img
后处理部分代码十分简单,将输出列表中最大值的索引作为返回值,直接输出label_list对应的文本即可。
lab = np.argmax(output_tensor.numpy()) #argmax():返回最大数的索引
C++部署详解:
// 引用头文件和命名空间
#include "paddle_api.h"
using namespace paddle::lite_api;// 指定模型文件,创建Predictor
// 1. Set MobileConfig, model_file_path is the path to model model file.
MobileConfig config;
config.set_model_from_file(model_file_path);
// 2. Create PaddlePredictor by MobileConfig
std::shared_ptr
std::unique_ptr
input_tensor->Resize({1, 3, 224, 224});
auto* data = input_tensor->mutable_data
for (int i &#61; 0; i < ShapeProduction(input_tensor->shape()); &#43;&#43;i) {data[i] &#61; 1;
}// 执行预测
predictor->Run();// 获得预测结果
std::unique_ptr
auto output_data&#61;output_tensor->data
以上为C&#43;&#43;接口基本使用流程&#xff0c;具体接口参考Paddle Lite C&#43;&#43; API文档。
C&#43;&#43;的预处理部分相对Python的预处理稍微有点麻烦。但是核心思想是不变的。要与训练对齐。
在HWC->CHW时使用了NEON指令&#xff0c;NEON是适用于ARM Cortex-A系列处理器的一种128位SIMD&#xff08;Single Instruction&#xff0c;Multiple Data&#xff0c;单指令、多数据&#xff09;扩展结构。通过这种方式来transpose的速度是极快的。由于C&#43;&#43;本身的特性&#xff0c;加上NEON的加速&#xff0c;我们在相同环境部署程序中是能明显感受到我们C&#43;&#43;的推理程序运行速度是优于Python的。
void preprocess(cv::Mat &photo,float *input_data) {cv::resize(photo, photo, cv::Size(224, 224), 0.f, 0.f, cv::INTER_LINEAR); //resize到224x224,INTER_LINEAR双线性插值cv::cvtColor(photo, photo, CV_BGRA2RGB); //BGR->RGB 与训练时输入一致photo.convertTo(photo, CV_32FC3, 1 / 255.f, 0.f); //归一化
// std::cout << photo << std::endl;//查看形状// NHWC->NCHWint image_size &#61; photo.cols * photo.rows;const float *image_data &#61; reinterpret_cast
}
后处理部分代码也是保持一致&#xff0c;将输出列表中最大值的索引作为返回值&#xff0c;直接输出word_labels对应的文本即可。
std::cout << "预测结果为:" << word_labels[std::distance(output_data, std::max_element(output_data, output_data &#43; 4))]<< std::endl;
至此&#xff0c;我们完成了模型部署阶段 &#xff0c;现在可以插上摄像头来运行我们的部署程序了。
如果不插入摄像头&#xff0c;运行Python接口的预测程序是会报错的哦~&#xff08;需要预测图片可自行二次修改&#xff09;。
C&#43;&#43;接口的部署程序可以修改run.sh文件去预测images文件夹下的4张测试图片。
总结
至此&#xff0c;我们全面的讲述了飞桨框架2.0训练到Paddle Lite部署的全流程&#xff0c;以及部署时需要注意的问题。
最后再强调一点&#xff0c;如果想部署飞桨框架2.0的模型&#xff0c;请务必使用Paddle Lite2.8-rc版本。2.7及以前的版本是不能友好地部署飞桨框架2.0的模型。
关于配套代码及视频讲解

马上扫码关注【飞桨】公众号
回复『柠檬分类』获取项目
欢迎大家也积极报名课程&#xff01;
在AI Studio上的柠檬分类Notebook项目中&#xff0c;一键fork即可获得。项目内置数据集&#xff0c;无需再科学上网下载比赛数据集&#xff01;一键运行全部&#xff0c;训练部署一条龙服务&#xff0c;从头到尾无bug&#xff01;
&#xff08;Emmmmm&#xff0c;万一发现了bug请评论区悄悄告诉我[手动狗头]&#xff09;
回顾往期&#xff1a;
用飞桨扛起日本分类竞赛头旗&#xff01;绽放你的能量&#xff01;—— 训练篇(一)
如果你热爱推理部署的话&#xff0c;欢迎加入【飞桨推理部署交流群】&#xff1a;959308808
如果您想详细了解更多Paddle Lite的相关内容&#xff0c;请参阅以下文档。
·Paddle Lite项目地址·
GitHub:
https://github.com/PaddlePaddle/Paddle-Lite
Gitee:
https://gitee.com/paddlepaddle/paddle-lite

????长按上方二维码立即star&#xff01;????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础&#xff0c;是中国首个开源开放、技术领先、功能完备的产业级深度学习平台&#xff0c;包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件&#xff0c;持续开源核心能力&#xff0c;为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台&#xff0c;针对企业级需求增强了相应特性&#xff0c;包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业&#xff0c;提供零门槛、预置丰富网络和模型、便捷高效的开发平台&#xff1b;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
