弹性非常适用于流系统,以保证针对工作负载动态的低延迟,例如到达率的激增和数据分布的波动。现有系统使用以resource-centric的方法实现弹性,该方法在并行实例(即执行程序)之间重新分配Key,以平衡工作负载和扩展Operator。然而,这种Operator级别的重新分区需要全局同步并且禁止快速弹性。我们提出了一种以executor-centric的方法,它避免了Operator级别的Key数据重新分区,并将执行程序作为弹性的构建块。通过这种新方法,我们设计了具有两级优化的Elasticutor框架:i)执行器的新颖实现,即elastic executors,通过有效的executror内负载均衡和executor扩展来执行弹性多核执行,以及ii)a基于全局模型的调度程序,可根据瞬时工作负载为执行程序动态分配CPU内核。我们实施了一个原型Elasticutor并进行了大量实验。我们表明,与实际应用程序的动态工作负载方法相比,Elasticutor的吞吐量增加了一倍,延迟降低了两个数量级。
分布式流系统[8,12,40,43,45,50,51]实现了对连续流的实时数据处理,并已广泛用于欺诈检测,监控分析和定量融资等应用。 在这样的系统中,应用程序逻辑被建模为计算图,其中每个顶点表示与用户定义的处理逻辑相关联的Operator,并且每个边指定运算符之间的数据流的输入-输出关系。 为了实现大规模数据处理,输入数据流通常被定义为通过key 空间分区到下游子分区中。并行执行实例(即执行程序)以将每个key的子空间静态绑定到一定量的计算资源,通常是CPU核心。 结果,每个执行器可以独立地进行与其key SubSpace相关联的计算。
然而,在股票交易和视频分析等实际应用中,工作量随时间波动很大,导致严重的性能下降[15,39]。 从时间角度来看,发送到Operator的总工作量可能会在短时间内显着激增,例如10秒,这使得Operator成为整个处理流程的瓶颈。 从空间角度来看,Key空间上的工作负载分布可能不稳定,导致执行程序中的工作负载偏差,其中一些CPU利用率较低,而另一些则过载。 为了适应工作负载波动,先前的工作[14,15,39,41]提出了实现弹性的解决方案,即Operator扩展和负载平衡。 所有这些解决方案都以资源为中心,因为执行程序受特定资源的约束,并且通过跨执行程序动态地重新分配Key来实现弹性。
图1(a)说明了由于工作负载分配不平衡而导致执行程序过载的情况。为了减轻性能瓶颈,重新分区Key空间,以便将重载执行程序中的一定数量的工作负载与相应的Key一起迁移到负载较轻的执行程序。但是,这个过程需要一个耗时的协议[15,39]来维持状态一致性。特别是,系统需要执行以下操作:(a)阻止上游执行程序向下游发送元组; (b)等待所有飞行中的元组进行处理; (c)根据新的Key空间划分,将状态迁移到新的key space分区汇总; (d)更新上游执行者的路由表;最后(e)恢复向下游发送元组的上游执行者。由于Operator间路由更新和执行器间状态迁移都需要昂贵的全局同步,因此Key Space重新分配可能持续数秒,在此期间无法处理新的传入元组并导致严重延迟。
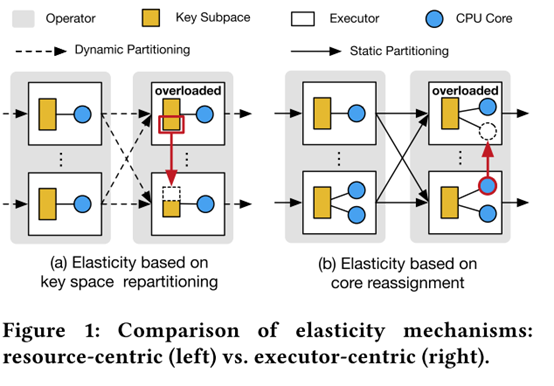
为了实现快速弹性,我们提出了一种以执行者为中心的范式。 核心思想是在执行程序之间静态划分Operator的Key Space,但根据其瞬时工作负载动态地为每个执行程序分配CPU核心。 图1(b)说明了新方法不是对Key Space进行重新分区,而是通过将CPU内核从较轻负载的执行程序重新分配给过载的执行程序来平衡工作负载。 由于每个执行器拥有固定Key SubSpace,新方法实现了Operator间独立性,即上游Operator不需要与下游Operator同步,并且执行器间独立性,即与Key SubSpace相关联的状态不需要迁移跨执行者。 换句话说,这种新方法优雅地解耦了Operator Key Space重新分区和计算资源的动态供应之间的绑定。
基于以执行器为中心的方法,我们设计了具有两个优化级别的Elasticutor框架。 在执行程序级别,作为轻量级分布式子系统实现,每个弹性执行程序在其分配的CPU核心上均匀分配其工作负载,并在调度程序分配/取消分配CPU核心时快速扩展。 在整体层面,基于模型的动态调度程序设计用于根据测量的性能指标Metrics优化核心到执行程序的分配,以便以最小的状态迁移开销和最大的计算局部性来适应工作负载动态。 我们实现了Elasticutor的原型,并使用合成和真实数据集进行了大量的实验。 结果表明,Elasticutor使吞吐量翻倍,并且比现有方法实现了更低的延迟。
本文的其余部分安排如下。 第2节介绍了以执行者为中心的范例,并概述了Elasticutor框架。 第3节和第4节分别介绍了弹性执行器和动态调度器的设计。 第5节讨论了实验结果。 第6节回顾了相关工作。 第7节总结了论文。
我们考虑在由快速网络设备连接的称为节点的机器群集上的实时有状态流处理系统。流是一个无限的序列。来自输入流的元组连续到达系统并立即处理。用户应用程序被建模为计算的有向图,称为Topology,其中顶点是具有用户定义的处理逻辑的运算符,并且边表示运算符之间的处理序列。对于每对相邻Operator,流的元组由上游Operator生成并由下游Operator消费。在有状态计算中,Operator维护内部状态,该状态用于计算并将在输入元组的处理期间更新。为了分配和并行化计算,操作符的状态被实现为在key space上定义的可分割数据结构。系统将key space划分为sub space,并创建一个称为执行程序的并行实例,每个实例具有相同的数据处理逻辑。为了保证在这样的分布式系统上维护的状态的一致性,需要将元组正确路由到下游执行器。因为以不同顺序处理相同的输入元组序列可能导致不同的输出元组和状态,所以有状态计算中的另一个基本要求是按到达顺序处理相同key的元组。
流处理工作负载通常是动态的,因为对Operator的输入速率和元组的key分配随时间波动。为了保证动态工作负载下的性能,应该向Operator适当地提供计算资源,即CPU核心,以便确保1)Operator扩展,即CPU核心根据其工作负载动态地分配给Operator; 2)负载平衡,即每个Operator的工作负载均匀分布在分配的CPU核心上。如果不实现前者,一些Operator可能会过载或过度配置,分别成为性能瓶颈或浪费计算资源。如果不实现后者,一些CPU内核将会过载,而其他CPU内核将未得到充分利用,从而导致性能下降。我们将Operator缩放和负载平衡的机制称为弹性。为了在动态工作负载下保持高性能,快速弹性是一项至关重要的要求。

表1总结了现有两种弹性范式的主要特征:静态和以资源为中心的方法。 静态方法使用固定数量的执行程序实现每个Operator,并使用静态Operator Key Space在执行程序之间分配工作负载。 每个执行程序由绑定到指定CPU核心的单个数据处理线程组成。 由于静态Key分区和CPU内核与执行器的一对一绑定,静态方法简化了系统实现,并在大多数最先进的系统中采用[30,43]。 但是,由于既不能平衡分配的CPU内核的工作负载,也不能调整分配给特定Operator的CPU内核数量,因此这种方法对分区模式非常敏感,并且由于缺乏弹性而在动态工作负载下效率低下。
以资源为中心的方法通过支持动态Operator级Key分区来解决静态方法的限制,同时遵循与静态方法相同的执行程序实现。 凭借Operator级Key重新分区的功能,以资源为中心的方法实现了弹性,因为它可以将一些Key及其相应的工作负载从重载执行程序迁移到负载较轻的执行程序,以平衡工作负载,或从现有执行程序迁移到新创建的执行者以扩展Operator。 但是,如引言部分所述,此Operator级Key重新分区是一个耗时的过程,在此过程中需要昂贵的全局同步来迁移状态并更新所有上游执行程序的路由表。 因此,以资源为中心的方法不能实现快速弹性,只能解决非常有限的工作量动态。
为了实现快速弹性,我们提出了一种新的执行范式:以executor-centric的方法。我们的想法来自观察到Operator级别的Key重新分区太昂贵而无法实现快速弹性。因此,以执行器为中心的方法使用静态Operator级别的Key分区,但将每个执行程序实现为弹性的构建块以处理工作负载波动。特别是,每个执行程序都旨在通过动态创建或删除数据处理线程来利用各种计算资源。因此,为了实现负载平衡和Operator扩展,系统可以为每个弹性执行器动态分配适当数量的CPU内核,而不是执行昂贵的Operator Key重新分区。与Operator Key重新分区相比,可以有效地实现CPU内核的重新分配和内部执行器负载平衡,因为它们不需要任何Operator间或执行器间同步。有趣的是,我们的新方法通过避免全局同步实现了快速弹性。
遵循以执行者为中心的方法,我们设计了专注于支持有状态流处理的Elasticutor。 为了处理流系统上的大规模数据,我们假设数据和状态是在Key Space下定义的,基于哪些分区数据流和状态可以由分布式计算单元并行处理和维护。 我们假设Key Space足够细粒度,以便甚至可以在越来越多的计算资源(即CPU核心)上分配和平衡扭曲的工作负载。 对于像Heron,Flink和Samza这样的其他最先进的流处理系统,还需要这种假设来实现高度并行化的有状态流处理。
我们的设计目标是实现实时响应,归结为保证低延迟。 然而,过度延迟可能是由于较高的数据到达率导致的系统资源不足,或导致工作负载不平衡的低效资源分配和调度。 前者需要资源缩放,而后者则不需要。 基于关注点分离原则,我们将Elasticutor设计为两级架构,如图2所示。

高级调度程序(在第4节中描述)处理可能在一段时间内激增的动态工作负载,在此期间现有系统容量不足并需要扩展。不需要过度配置,但我们假设可以从基于云的平台按需获取资源。我们假设工作负载的总体激增不会太频繁发生,例如,在几分钟到几小时的时间范围内。动态调度程序确定每个弹性执行程序应在瞬时工作负载下提供的所需CPU核心数。它采用基于排队网络的性能模型,并使用弹性执行器的收集性能Metrics指标作为输入来生成资源分配决策。根据现有的核心到执行器分配和集群中CPU核心的可用性,调度程序改进了分配以适应新的资源分配计划,同时考虑了CPU重新分配开销和计算资源的位置。
每个low-level执行程序(在第3节中描述)被设计为一个轻量级,自包含的分布式子系统,称为弹性执行程序,负责处理固定key subspace下的输入。 为适应工作负载波动,弹性执行器可以使用动态数量的CPU核心,可能来自多个节点,由动态调度程序决定。 为了在工作负载波动的情况下充分利用其分配的CPU内核,弹性执行器具有高效的内部负载平衡机制,可以在更短的时间范围内将分配的CPU内核的输入流的计算均匀分布。
以有状态处理为目标的流处理系统的设计空间还包括诸如状态大小和数据流特征之类的维度,即每元组的计算和大小,以及key space下数据流的倾斜程度和动态性。我们将讨论权衡Elasticutor与第5节中的变更方法进行比较。
为了有效地利用CPU资源,弹性执行器被设计为适应两种动态:1)key分配的变化和2)CPU core重新分配,如图3所示。前者来自输入流的波动,而后者由调度程序确定全局优化。 为了在其计算资源上分配工作负载,弹性执行程序为每个分配的CPU核心创建任务,并在其上分配输入数据元组。 在CPU重新分配时,将创建新任务或删除现有任务。 这两种动态都会在任务之间引入不平衡的工作负载,从而导致资源利用不足或性能下降。 因此,一个中心设计问题是如何在存在这种动态的情况下在任务之间保持平衡的工作负载分配。

如图4所示,弹性执行器被实现为轻量级,自包含的分布式子系统,其可以利用多个物理节点上的计算资源。 每个弹性执行程序主要驻留在一个称为其本地节点的物理节点中,在该节点中,它运行本地主进程以接收输入元组并发送输出元组。 对于每个分配的CPU核心,在该过程中创建作为数据处理线程实现的任务。 要在远程节点上使用CPU核心,可以创建远程进程来托管远程数据处理的远程任务。
Intra-Executor Routing: 我们采用双层设计,在图4中央结构中显示的路由表中实现,根据瞬时工作负载分配动态地将输入元组映射到任务。第一层使用静态散列函数将key Sub Space静态划分为Shard;第二层显式维护动态Shard到任务映射,该映射在Shard重新分配时更新。我们在粗粒度而非每个Key的基础上平衡工作负载,主要是因为细粒度方法需要维护每个Key的工作负载,因此遭受高内存消耗。Shard数量的选择提供了负载平衡质量和维护开销之间的权衡。然而,在实践中,合理数量的Shard(例如,任务数量的4或8倍)实现了良好的平衡质量,同时保持低维护开销。我们将在5.3节讨论Shard数如何影响某些极端设置中的系统性能。

Executor-Level Fault Tolerance:在流处理系统中已经广泛研究了容错[8,11,14,35,49],因此既不是本文的重点也不是本文的贡献。 在这里,我们只讨论如何从故障中恢复每个弹性执行器的远程任务,以便Elasticutor可以利用最先进的状态检查点技术,如流水线快照协议[11],实现容错。
弹性执行程序的主要过程在逻辑上维护其任务状态的主副本。默认情况下,状态在主进程的内存中维护以进行高效访问,但是当状态太大而无法容纳在内存中时,也可以将状态存储在外部存储中。主进程还用增加的元组ID标记每个输入数据元组。对于每个远程任务T,弹性执行程序维护一个待处理的元组队列以备份发送到T的数据元组,并且值ts表示已经处理了ID小于ts的所有数据元组,并且处理这些元组产生的状态更新已被冲回主副本。每个远程任务周期性地,例如每10秒,将其本地状态的更新与tmax(即,已经处理的元组的最大ID)一起发送到弹性执行器的主进程。在从远程任务T接收到状态更新时,弹性执行器更新状态的主副本,在T的待处理队列中移除ID不大于tmax的元组,并更新ts = tmax。当远程任务T失败时,弹性执行程序使用状态的主副本创建新任务,并通过在待处理队列T中重放大于ts的ID的元组来开始执行新任务。
虽然状态共享提高了Shard重新分配的效率,但需要注意保证一致性。 一般而言,尽管使用与以资源为中心的方法的Key重新分区类似的过程,我们通过利用以执行器为中心的方法启用的Operator间和执行者间的独立性来实现具有状态一致性的有效分片重新分配。
考虑图4中的情况,其中元组t1处于任务T2的待处理队列中,元组t2刚刚到达执行器的主进程,并且元组t3将由上游执行器发出。 假设所有三个元组都属于shard r4。 如果在处理t1之前或在更新t2和t3的路由之前将shard r4从源任务T2重新分配给新的目标任务,则状态将变得不一致。 特别地,如果目的地任务是本地的,例如T1,那么t2可能在t1之前被处理,违反了顺序处理的要求。 如果目的地任务是远程的,例如T0,则由t1对状态的修改将丢失。
Inter-Operator Consistent Routing:为了保证从上游Operator到分配的任务所在的正确进程的一致路由(例如t3),弹性执行器在其本地主进程中实现接收器守护进程,作为来自上游Operator的所有元组的单一入口。接收器根据内部路由表将元组路由到适当的本地或远程任务。类似地,发射器守护程序在主进程中实现为执行程序的单个退出,以将任务生成的输出元组转发给下游Operator。远程过程仅与弹性执行器的主过程上的接收器和发射器通信。因此,无论在弹性执行器中的任务之间如何动态重新分配分片,上游和下游Operator总是通过其接收器和发送器向执行器发送元组或从接收器接收元组,从而避免由分片重新分配引起的任何Operator间同步。相反,以资源为中心的方法通过Operator级key space重新分区来重新分配工作负载,从而导致与所有上游执行程序同步。
请注意,与以资源为中心的方法相比,来自上游执行器的元组直接路由到下游Operator,Elasticutor可能涉及接收器/发射器和远程任务之间的额外远程数据传输。 这是我们为实现快速弹性而做出的权衡。 在典型的工作负载中,远程数据传输不是性能瓶颈,如图13所示。在5.3节中,我们通过正确配置Operator的执行器数量,讨论如何避免/减少某些极端工作负载中的远程数据传输。
Intra-Executor State Consistency: 为了保证在重新分区Shard期间的状态一致性,弹性检测器采用类似于以资源为中心的方法中使用的Operator级重新分区的Key重新分区过程,但不涉及任何全局同步。关键是要确保a)在将shard状态迁移到目标任务之前必须处理挂起的元组,即SOurce任务中排队的分片的未处理元组。 b)具有相同Key的元组不会同时在任何两个任务中处理。在图4中Shard r4的重新分配期间,暂停了元组r4的路由,并将标签元组发送到其Source taskT2。由于任务以先来先服务的方式处理其输入元组,因此当T2从其待处理队列中拉出标签元组时,保证已经发送到T2的任何待处理元组呗处理。之后,r4的状态将迁移到目标任务。如果将分片重新分配给其源任务的本地任务,则省略状态迁移。在状态迁移之后,在恢复r4的元组的路由之前,在路由表中更新Shard到任务映射。
Discussions:值得注意的是,我们提出的以执行为中心的范例适用于其他现有的分布式流系统,例如Apache Flink,Apache Heron和Apache Samza,其中有状态处理可以通过在key space下划分状态和数据来并行化。 对于无状态应用程序,我们的方法仍然可以应用,但可能不一定是最佳选择,因为通过简单地以循环方式发送元组或者向负载最少的执行程序发送元组可以轻松实现负载平衡。
虽然我们的方法不适用于基于批处理的系统,但我们的双层负载平衡设计与小批量定向的Spark Streaming [50]采用的方法有一些相似之处。 两个主要的区别是:1)我们设计一个额外的中间层碎片提供了维护成本和平衡负载之间的权衡,2)我们的测量和平衡设计对流量系统更自然,其中操作过程输入元组 而不是基于小批量。
动态调度程序的目标是通过在不断变化的工作负载下自适应地将CPU核心分配给弹性执行程序来满足用户定义的延迟要求。 通过使用由系统测量的瞬时性能指标,调度程序首先根据排队网络模型估计每个执行程序所需的核心数量,并进一步(重新)将物理核心分配给执行者,以便最小化重新分配开销 并最大化执行程序内的计算位置。
我们将m个弹性执行器的拓扑E = {1,··,m}建模为Jackson网络,其中每个执行器j∈E被视为M / M / kj系统[42],其中kj表示分配给j的CPU核心数。 输入流的平均处理等待时间,表示为E [T],可以作为资源分配决策k的函数来计算。

其中λ0表示输入流的到达率,Tj和λj分别表示执行器j的平均处理时间和到达率。 当kj>λj/μj时,每个E [Tj](kj)是有界的,其中μj表示弹性执行器j的处理速率,并且可以作为由系统测量的参数λ0,{λj}和{μj}的函数来计算。基于等式(1),调度器尝试找到分配k以确保E [T]不大于用户指定的等待时间目标Tmax,同时最小化CPU核心的总数。 特别地,每个kj被初始化为λj/μj+ 1,这是使系统稳定的最低要求。 我们重复向向量k中的值加1,导致E [T]的最显着减少,直到E [T]≤Tmax或Íkj超过可用CPU资源的数量。 这个贪心算法在找到解k时已经证明是最优的[22]。
性能模型仅建议新的分配,即每个执行者需要的CPU核心数量,这是由工作负载波动引起的; 调度程序仍然需要通过更新现有的核心到执行程序分配来适应新的分配计划。 新分配计划的CPU重新分配是系统性能的关键,因为它可能会引入1)转换期间的状态迁移成本,以及2)之后的远程数据传输成本。 例如,在重新分配CPU内核时,弹性检测器会创建一个新任务,如果CPU内核远离弹性执行程序,则涉及状态迁移和将来的远程数据传输。 为了优化执行效率,我们搜索最小化迁移成本的CPU到执行器分配,同时限制计算局部性以限制未来的远程数据传输成本。
为了模拟迁移成本,我们考虑一个n个节点的集群,其中每个节点都有ci CPU核心。对于任何执行器j∈E,我们用I(j)表示其主进程所在的节点,并且通过列向量xj =(x1j,...,xnj)T表示在所有节点上分配给它的核的数量。我们将jj = i = 1 xi jas定义为j的指定核心总数,并用矩阵X =(x1,···,xm)表示CPU到执行器的分配。给定任何新的分配k,从现有分配X到新分配X的转换需要执行一组CPU分配/解除分配。核心重新分配的开销由状态迁移成本决定,状态迁移成本与跨网络移动的状态大小成比例。我们用sj表示任何执行者j的聚合状态大小。为简单起见,我们假设弹性执行器的分片均匀分布在分配的CPU核心上;因此,与每个CPU核心相关的状态数据量大约是sj / Xj。给定任何分配k,可用核心c和现有分配X~,我们按如下方式制定CPU分配问题。

上述优化问题最小化了从现有赋值X到新赋值X的迁移成本C(X | X〜),其中求和中的每个项都测量执行者j将其状态迁移出节点i的成本。约束包括(a)CPU核心的数量,(b)分配要求和(c)计算局部性,即,要求分配给执行器的集合E(φ)的所有核心都在其本地节点上。系统通过其总输入和输出数据速率除以核心数kj来测量任何执行器j的瞬时每核数据强度,并且E(φ)表示数据强度高于阈值的执行器集合。 。因为如果分配的核心是远程的,数据密集型执行程序将产生更高的网络成本,我们通过避免将远程核心分配给E(φ)的成员来强制执行计算局部性。这个整数规划问题可以简化为NP-hard多处理器调度问题[23]。因此,我们设计了一个有效的贪婪算法1来找到近似解。对于任何赋值X,我们将E + = {j∈E| Xj
C-ij(X)分别表示在节点i上分配/取消分配CPU核心到执行器j的开销,可以导出为C + ij(X)= sj(Xj-xi j)/(Xj( Xj + 1))和C-ij(X)= sj(Xj-xi j)/(Xj(Xj-1))。

算法1按数据强度按降序对E +中的执行程序进行排序,并尝试通过从其他执行程序解除分配核心,逐个为每个执行程序j分配目标CPU核心数。具体来说,如果弹性执行器j是数据密集型的,即j∈E(φ),它只接受节点i = I(j)上的CPU核心,以避免创建远程任务。因此,在所有非数据密集型执行程序中,算法在节点I(j)上找到一个CPU核心,可以用最小的释放开销重新分配给j(第7行)。相反,如果j不是数据密集型,则它接受任何节点上的CPU核心。该算法搜索E-中的所有执行程序,以获得具有CPU内核的执行程序,该内核可以通过最小的释放和分配开销重新分配给j(第9行)。在任何一种情况下,如果找到这样的有效核心重新分配,则算法将其添加到新的赋值X中;否则,它返回FAIL,这表示没有找到可行的解决方案,并且暗示需要更高的数据不敏感阈值φ来获得可行的解决方案。
算法1按数据强度按降序对E +中的执行程序进行排序,并尝试通过从其他执行程序解除分配核心,逐个为每个执行程序j分配目标CPU核心数。具体来说,如果弹性执行器j是数据密集型的,即j∈E(φ),它只接受节点i = I(j)上的CPU核心,以避免创建远程任务。因此,在所有非数据密集型执行程序中,算法在节点I(j)上找到一个CPU核心,可以用最小的释放开销重新分配给j(第7行)。相反,如果j不是数据密集型,则它接受任何节点上的CPU核心。该算法搜索E-中的所有执行程序,以获得具有CPU内核的执行程序,该内核可以通过最小的释放和分配开销重新分配给j(第9行)。在任何一种情况下,如果找到这样的有效核心重新分配,则算法将其添加到新的赋值X中;否则,它返回FAIL,这表示没有找到可行的解决方案,并且暗示需要更高的数据不敏感阈值φ来获得可行的解决方案。
φ的选择提供了公式4.2的可行性与弹性执行器的计算局部性之间的权衡。由于动态分配算法非常有效,我们使用低默认值φ=〜φ运行算法。如果没有找到可行的解决方案,我们将φ加倍并重新运行算法,直到我们找到一个。在我们的实验中,我们将φ~设置为512 KB / s,低于该值时,计算局部性的好处可以忽略不计。
Discussions:我们的动态调度程序设计适用于使用连续运算符的流处理,并遵循数据流模型[5]。调度程序确定每个执行程序满足延迟要求所需的资源,并计算资源分配以最大限度地降低状态迁移成本。在这个级别工作的其他调度程序包括Flink的DS2 [28],Heron的Dhalion [21],Storm的RAS [36]等等。相比之下,基于云的资源管理系统(如YARN [44]和Mesos [25])更加以集群为中心[26,27],即它们主要旨在管理不同应用程序之间的集群资源。他们通常会收到应用程序经理的资源需求,并根据效率和公平等标准来决定如何配置资源。通常开发协商器/协调器模块用于协助不同级别的调度器之间的交互。典型的例子包括Storm-on-Yarn [3]和Flink-on-Yarn [2]。
我们在Apache Storm上大约10,000行Java中实现了Elasticutor的原型[43]。 Elasticutor的源代码可在[4]获得。 Storm是一种流行的分布式流处理系统,它暴露了低级API,例如Bolt API。 这对于原型研究思想来说相对容易一些。 Storm遵循静态方法,其操作符由用户通过抽象类Bolt实现。 我们添加了一个新的抽象类ElasticBolt,它提供了与Bolt相同的编程接口,但是向用户空间公开了一个新的状态访问接口。 对于任何定义为ElasticBolt的运算符,Elasticutor创建了许多具有内置状态管理,度量标准Metrics测量和弹性功能的弹性执行器。 动态调度程序实现为在Storm的主节点(nimbus)上运行的守护程序进程。
我们的实验在Amazon EC2上进行,具有32个t2.2x大型实例(节点),每个实例具有8个CPU核心和32GB RAM,运行Ubuntu 16.04。网络是1Gbps以太网。在所有方法下,执行器以循环方式分配给节点。除非另有说明,否则Elasticutor每个运算符使用32个弹性执行程序,每个执行程序使用256个分片(每个运算符8192个分片)。为了公平比较,我们为静态方法中的Operator创建了足够的执行程序,以充分利用集群中的所有CPU核心;并将RC方法中的key spcae分区的粒度设置为每个运算符8192个分片,与Elasticutor中的相同。为确保系统稳定性,Storm,Heron和Flink等现有流系统实施反压机制,以控制Operator的输入速率。为了关注系统性能,我们评估压力情况,其中足够高的到达率使输入队列保持非空并且可能触发Storm的背压机制。
我们在2.3节中详细讨论了有状态流处理设计空间中的Elasticutor。在本节中,我们将Elasticutor的性能与静态方法(默认Storm)和以资源为中心(RC)方法的性能进行比较。第2.2节总结了这三种方法的主要区别。我们通过启用创建/删除执行程序和Operator级Key重新分区来实现基于Storm的RC。为了公平比较,RC使用与Elasticutor相同的性能模型,负载平衡算法和进程内状态共享机制。我们将评估Elasticutor在设计空间中的不同维度所做出的性能和权衡,包括状态大小,每元组计算和大小,以及数据流的偏度和动态性。通常,只要有足够的计算资源可用于系统中的扩展,Elasticutor amis的设计就可以容纳计算密集型工作负载。但是,由于远程任务的引入可能会导致数据传输和状态迁移开销和延迟,我们的设计假定工作负载在元组大小和状态大小方面不会过于数据密集,并且网络带宽容量确实如此不成为瓶颈。我们假设在关键领域的数据分布中表现出的倾斜度是一种规范,我们关注的是更具挑战性的情况,其中数据倾斜度也会突然变化,这可以在股票交易数据集和评估中显示出来。
在本小节中,我们使用一个简单而有代表性的拓扑结构,如图5所示,它允许轻松控制工作负载特性,例如输入速率,计算成本和数据分布。拓扑由生成器和计算器组成,输入数据流由生成器馈送到计算器进行处理。我们确保数据生成速率使计算器的输入队列饱和。计算器运算符中每个元组的处理时间遵循正态分布N(μ,δ2=0.5μ)。通过在执行时间内循环运行数据加密来实现计算,以耗尽CPU周期并模拟计算密集型工作负载。除非另有说明,否则每个元组由一个整数键和一个128字节的有效负载组成,并且处理的平均CPU成本为1 ms。密钥空间包含10K个不同的值,其频率遵循zipf分布[37],偏差因子为0.5。默认状态大小为256MB,每个分片为32KB。为了模拟工作负载动态,我们通过应用每分钟ω次随机排列来改变元组Key的频率。

工作负载动态的稳健性:图6描绘了随着ω沿x轴变化的三种方法下的吞吐量和平均处理延迟。我们观察到,当工作负载是动态的时,Elasicutor在两个指标方面始终优于其他方法,即ω > 0。特别是,由于密钥分配偏差导致工作负载不平衡,静态方法的性能较差,但由于没有执行弹性操作,因此在所有情况下都相对稳定。 由于RC和Elasticutor都能够适应偏斜的键分布,因此当ω很小时,它们会大大优于静态。 然而,随着ω的增加,尽管由于弹性操作成本较高而导致RC和Elasticutor的性能下降,但Elasticutor的性能下降是微不足道的,而RC的性能下降变大了2-3个数量级,使RC无用为ω 达到16。

为了更好地解释ω变化时三种方法的性能,我们关注ω= 2的情景,即每30秒进行一次混洗,并绘制在图7中1秒的滑动时间窗口内测量的瞬时吞吐量。我们观察到 静态方法的吞吐量始终远低于RC和Elasticutor的吞吐量,尽管变化不大。 由于关键混洗触发弹性操作的执行,RC和Elasticutor每30秒就会出现一次瞬态吞吐量降低。 然而,RC的退化要差得多,其瞬态持续时间为10到20秒,而Elasticutor的衰减仅持续1到3秒。 这解释了随着工作负载变得更加动态,两种方法中性能差距扩大的原因。
在不同数据强度下的性能:为了评估工作负载的数据强度如何影响三种方法的性能,我们改变元组大小(表示为s)和每个元组的计算成本(表示为c),并将其性能进行比较。结果表明,在数据强度较高的情况下,例如,元组大小较大或每个元组的计算成本较低,由于数据传输开销较高,三种方法的吞吐量会下降。例如,当c = 0.01ms且s = 2KB时,一个CPU内核上的全速元组处理的数据传输要求是2Gbps,超过了网络带宽,即1Gbps,因此导致性能显着下降。所有的方法。但是,Elasticutor通常对元组大小比竞争对手更敏感,特别是当计算成本极低时,例如,每个元组c = 0.01ms,因为它具有独特的两级元组路由机制,从而带来更高的数据传输开销数据强度。
不同状态大小下的性能:图9比较了三种方法在吞吐量和延迟方面的性能,因为状态大小沿x轴变化。请注意,由于每个运算符有8192个分片,因此当每个分片的状态大小为32MB时,运算符的状态大小将为256GB,这相当大。结果表明,随着状态大小的增加,RC和Elasticutor的性能下降,这是由于较大的状态大小导致的状态迁移开销增加。当状态大小接近32MB时,作为一种极端情况,由于执行弹性的巨大运营成本,Elasticutor和RC都比静态方法表现更差。我们还观察到,在相同的州规模下,Elasicutor的表现优于RC方法。这表明Elasticutor中使用的技术,如状态共享机制和动态调度,可以有效地减少弹性操作中的状态迁移开销。

对执行工作负载分配倾斜的鲁棒性&#xff1a;实际上&#xff0c;由于Key分配偏差或者由于Operator级Key分区功能的不正确配置&#xff0c;工作负载可能无法在执行程序之间平均分配。为了评估三种方法对倾斜执行器工作负载分布的稳健性&#xff0c;我们使用由图10中的偏度因子α控制的变化的密钥分布偏度来评估它们的性能。注意&#xff0c;α越大&#xff0c;密钥分布具有越大的偏斜。例如&#xff0c;当α&#61; 0时&#xff0c;密钥遵循均匀分布&#xff0c;而当α≥0.8时&#xff0c;大多数工作负荷落入几个密钥。结果表明&#xff0c;静态方法受到负载不平衡的影响很大&#xff0c;而α<0.8时&#xff0c;Elasticutor和RC对执行器负载不平衡的抵抗力更强。主要观察结果是&#xff0c;当α≤0.6时&#xff0c;Elasticutor始终优于RC&#xff0c;但其性能急剧下降&#xff0c;并且在极度偏斜的工作负荷分布下比RC差&#xff0c;例如α≥0.7。这表明尽管依赖于创建更多远程任务来处理倾斜的执行程序工作负载分配&#xff0c;但Elasticutor中的执行程序能够处理高达α&#61; 0.5的工作负载不平衡&#xff0c;而不会在运行远程任务时引入明显的延迟增加和吞吐量降低。但是&#xff0c;当0.6≤α≤0.8时&#xff0c;大多数过载执行器无法通过有效利用更多远程任务来进一步卸载其工作负载&#xff0c;这主要是由于拥塞的网络带宽&#xff0c;因此成为性能瓶颈&#xff0c;导致系统吞吐量和延迟较差。
Shard reassignment cost&#xff1a;因为RC方法和Elasticutor都使用碎片重新分配来平衡工作负载&#xff0c;我们会比较它们的成本以更好地理解产生的不同延迟。 图11显示了每个分片的平均节点内和节点间重新分配时间&#xff0c;分为同步时间和状态迁移时间。 我们观察到RC中的碎片重新分配时间远远长于Elasticutor&#xff0c;这主要是由于RC方法中的同步时间极长。 我们还可以看到Elasticutor在状态迁移中花费的时间比RC短&#xff0c;但与同步时间相比&#xff0c;状态迁移中两种方法之间的差异较小。
为了深入了解两种方法之间的同步时间差异&#xff0c;我们改变了上游执行器的数量&#xff0c;并发现RC比Elasticutor需要2-3个更大的时间来同步&#xff0c;并且它们的差异随着更多的上游执行器而变宽&#xff0c; 如图12&#xff08;a&#xff09;所示。 Elasticutor遵循以执行者为中心的标准&#xff0c;从而避免在分片重新分配期间与上游检查员同步。 因此&#xff0c;无论上游执行器的数量如何&#xff0c;其同步时间约为2 ms。 相反&#xff0c;在RC方法中&#xff0c;需要更新上游执行器的路由表&#xff0c;并且需要全局同步来清除执行器和上游执行器之间的飞行中元组。 因此&#xff0c;RC中的同步时间要高得多&#xff0c;并且随着上游执行器的数量而大大增加。

图12&#xff08;b&#xff09;描绘了状态大小变化时的状态迁移时间。 我们观察到&#xff0c;由于进程内状态共享机制&#xff0c;两种方法中的节点内状态迁移的延迟可忽略不计。 当状态大小达到32 MB时&#xff0c;节点间状态迁移的时间显着增加&#xff0c;其中状态的网络数据传输是状态迁移过程中的主要开销。 该图还显示&#xff0c;在给定相同状态大小的情况下&#xff0c;由于执行器为中心的范例启用了执行器间独立性&#xff0c;因此Elasticutor迁移状态所需的时间比RC短一些。
Elasticutor的主要优点是它通过分配更多CPU内核而不是通过Operator级Key Space重新分区来处理工作负载动态。 尽管在一个合理的设置中&#xff0c;Operator通常有足够的执行器来分摊单个执行器上的工作负载&#xff0c;但由于Key分配偏差&#xff0c;操作员不正确&#xff0c;执行人员可能负载过重而需要许多远程任务。 级别分区或不必要的执行程序。 因此&#xff0c;为了Elasticutor的健壮性&#xff0c;弹性执行器具有良好的可伸缩性是至关重要的&#xff0c;即能够有效地扩展到许多CPU核心&#xff0c;并且在运行远程任务时不会引入明显的延迟。
为了评估弹性执行器可以有效扩展的范围&#xff0c;我们只为计算Operaotr设置了一个弹性执行器&#xff0c;但逐渐分配更多的CPU核心并测量其吞吐量和处理延迟。 由于每个节点有8个CPU核心&#xff0c;因此分配的前8个核心是本地核心&#xff0c;后续核心是远程核心。 在我们的评估中&#xff0c;我们改变了弹性的数据强度和运营成本&#xff0c;这是影响可扩展性的主要因素。 前者决定了远程数据传输在运行远程任务时的长期成本&#xff0c;并且与元组大小成正比&#xff0c;与每个元组的计算成本成反比。 后者影响执行弹性操作的短期运输开销&#xff0c;并与规模和工作量动态&#xff08;ω&#xff09;呈正相关。

图13描绘了执行器在不同计算成本&#xff08;左&#xff09;和元组大小&#xff08;右&#xff09;下的可伸缩性。我们观察到单个弹性执行器通常可以有效地扩展到整个集群&#xff08;256个CPU核心&#xff09;&#xff0c;这表明远程数据传输的成本可以忽略不计。我们还观察到弹性执行器无法有效地利用超过16个具有非常大的元组大小的CPU核心&#xff0c;例如8KB&#xff0c;或者非常低的计算成本&#xff0c;例如每个元组0.01ms&#xff0c;这表明巨大的远程数据传输链接到高数据强度可防止执行程序扩展。图14显示了弹性执行器向外扩展时的99&#xff05;延迟。我们可以看到&#xff0c;在大多数情况下&#xff0c;由于Netty [1]启用了有效的网络数据传输&#xff0c;处理延迟不会随着弹性执行器的扩展而显着增加。然而&#xff0c;在数据密集型工作负载中&#xff0c;例如&#xff0c;计算成本≤0.1ms或元组大小≥2KB&#xff0c;随着分配的CPU核心数超过远程数据传输成为性能瓶颈的点&#xff0c;等待时间大大增加。请注意&#xff0c;由于我们在任何一对输入输出执行器之间实现了反压机制&#xff0c;因此延迟不会无限增长。
图15显示了弹性执行器在各种碎片状态大小下的可扩展性&#xff0c;ω&#61; 2&#xff08;左&#xff09;和16&#xff08;右&#xff09;。 结果表明&#xff0c;弹性执行器在所有状态尺寸下均可有效扩展&#xff0c;但是32MB。 状态较大时&#xff0c;状态迁移会成为性能瓶颈&#xff0c;从而阻止执行程序有效地使用远程CPU核心。 通过比较两个子图&#xff0c;我们观察到当ω增加到16时&#xff0c;由于与更高工作负载动态相关的状态迁移需求增加&#xff0c;大状态下的可扩展性显着降低。

Elasticutor中有两个重要参数&#xff1a;每个执行程序的硬数&#xff0c;表示为z&#xff0c;每个运算符的执行数&#xff0c;表示为asy。作为一个规则&#xff0c;将z设置在256和1024之间可以实现良好的内部执行器负载平衡&#xff0c;并且将y设置为计算密集型运营商的节点数可以为那些运营商提供足够的潜力来扩展工作负载阵阵。然而&#xff0c;在下文中&#xff0c;我们在各种工作负载下评估系统性能的大范围&#xff08;y&#xff0c;z&#xff09;&#xff0c;以便了解这两个参数影响系统性能的原因和方式以及如何在极端情况下选择合适的参数工作负载。为了进行全面观察&#xff0c;我们使用三种代表性工作负载&#xff0c;即默认工作负载&#xff0c;数据密集型工作负载和高度动态工作负载。设s和ω分别表示以字节为单位的元组大小和每分钟的密钥重组。在默认工作负载中&#xff0c;&#xff08;s&#xff0c;ω&#xff09;&#61;&#xff08;128B&#xff0c;2&#xff09;。我们分别通过将s增加到8K和ω增加到16来获得数据密集型工作负载和高动态工作负载。因此&#xff0c;&#xff08;s&#xff0c;ω&#xff09;&#61;&#xff08;8K&#xff0c;2&#xff09;用于数据密集型工作负载&#xff0c;&#xff08;s&#xff0c;ω&#xff09;&#61;&#xff08;128B&#xff0c;16&#xff09;用于高动态工作负载。图16显示了在三个工作负载下具有各种y和z的系统吞吐量。为了比较&#xff0c;我们还在图中显示了静态和RC方法的吞吐量。
Number of shards&#xff1a;从图16中&#xff0c;我们观察到随着z增加&#xff0c;吞吐量通常会增加&#xff0c;尽管边际增长正在减少。 这表明当使用太少的分片时&#xff0c;例如&#xff0c;z≤64&#xff0c;执行器内负载平衡质量差&#xff0c;妨碍弹性执行器有效地利用多个核心; 然而&#xff0c;太精细的分片&#xff08;例如&#xff0c;z≥1024&#xff09;不会进一步提高吞吐量&#xff0c;因为执行器内的负载平衡已经有效。 基于那些z &#61; 16个观测值&#xff0c;我们验证每个执行器256到1024个分片实现了良好的性能。

Number of executors&#xff1a;如图16&#xff08;a&#xff09;所示&#xff0c;对于一个足够大的z&#xff0c;除了y &#61; 256之外&#xff0c;Elasticutor实现了有希望的性能。当y &#61; 256时&#xff0c;即集群中的CPU核心数量&#xff0c;每个弹性执行器只能分配一个CPU核心。因此&#xff0c;执行者失去弹性&#xff0c;Elasticutor被降级为静态方法。通过比较图16&#xff08;a&#xff09;和图16&#xff08;b&#xff09;&#xff0c;我们可以看到&#xff0c;当元组大小增加到8K时&#xff0c;静态和RC的性能变化不大&#xff0c;而在y &#61; 1的情况下Elasticutor的性能严重下降。与默认工作负载相比&#xff0c;在数据密集型工作负载中运行远程任务时远程数据传输的成本高出64倍。这限制了单个执行程序的可伸缩性&#xff0c;因此导致单个执行程序需要扩展到许多远程CPU核心的小y的性能较差。通过比较图16&#xff08;a&#xff09;和图16&#xff08;c&#xff09;&#xff0c;我们观察到随着洗牌频率从2增加到16&#xff0c;虽然吞吐量一般会减少&#xff0c;但当y很小时&#xff0c;减少幅度要大得多&#xff0c;即1或者8.在频繁混洗的动态工作负载下&#xff0c;例如ω&#61; 16&#xff0c;需要重新分配更多分片以进行负载平衡&#xff0c;从而导致高迁移成本。相反&#xff0c;当y足够大时&#xff0c;大多数执行器可以使用本地CPU内核进行扩展&#xff0c;从而避免由于内部处理状态共享机制导致的状态迁移;因此&#xff0c;吞吐量不会降低太多。总之&#xff0c;为每个节点设置一个或两个执行程序对各种工作负载都很稳健。
为了评估Elasticutor在实际应用中的表现&#xff0c;我们使用上海证券交易所&#xff08;SSE&#xff09;交易的股票的匿名订单数据集&#xff0c;收集时间超过三个月&#xff0c;每个交易时间约有800万条记录。该应用程序执行证券交易所的市场清算机制&#xff0c;并提供实时分析。应用程序的拓扑结构如图17所示。输入流由买方和卖方的限价订单组成&#xff0c;这些限价订单指定了特定库存的特定交易量的出价和要价。顺序元组的大小为96字节。在新订单到达时&#xff0c;交易员操作员针对未完成的订单执行它&#xff0c;并确定交易数量和现金转移。一旦进行了这样的交易&#xff0c;就会向下游运营商发送160字节的交易记录&#xff0c;包括时间&#xff0c;股票数量和交易价格以及卖方&#xff0c;买方和股票的ID&#xff0c;包括6个运营商的统计数据和5个事件处理的运营商。分析运算符生成统计数据&#xff0c;例如移动平均值和综合指数&#xff0c;并触发用户定义的事件&#xff0c;例如当特定股票的交易价格超过预定义阈值时的警报。每个统计运营商的状态大小约为200MB到400MB&#xff0c;而事件处理运营商的状态相对较小&#xff0c;低于10MB。由于交易和分析涉及个股&#xff0c;我们将库存ID的空间划分为并行处理。由于股票交易具有不可预测的性质&#xff0c;股票的到达率和分布均随着时间的推移而波动很大&#xff0c;从而导致高度动态的工作量。为了说明工作负荷动态&#xff0c;图18显示了5种最受欢迎的股票的即时到达率。

除了静态&#xff0c;RC和Elasticutor之外&#xff0c;我们还测试了一个天真的以执行器为中心&#xff08;naive-EC&#xff09;的实现&#xff0c;它与Elasticutor相同&#xff0c;只是在调度程序中禁用了迁移成本和计算局部性的优化。 图19绘制了在32个节点上运行的四种方法下的瞬时吞吐量和第99百分位处理延迟。 我们观察到&#xff0c;naive-EC和Elasicutor都优于静态和RC方法&#xff0c;大约使吞吐量翻倍&#xff0c;并将延迟降低1-2个数量级。 尽管naive-EC和Elasticutor之间的性能差距是可识别的&#xff0c;但与执行者为中心的方法和其他两种方法之间的差距相比&#xff0c;它们之间的差距很小。 这一观察结果表明&#xff0c;尽管动态调度程序中的优化能够显着提高性能&#xff0c;但Elasticutor的更好性能主要归功于采用的以执行器为中心的有利范式。
为了进一步说明naive-EC和Elasticutor之间性能差距背后的原因&#xff0c;我们在表2中显示了它们的状态迁移率和远程数据传输率。前者的速率是整个系统在网络中迁移的状态的聚合大小。 单位时间。 后一种速率是在所有弹性执行器和它们的远程任务之间以单位时间传输的数据的总量。 我们观察到&#xff0c;naive-EC下的状态迁移率和远程数据传输率分别比Elasticutor下的5倍和10倍高。 通过较少的状态迁移&#xff0c;弹性执行器转换到新的资源分配计划将更有效&#xff0c;从而实现更高的性能。 同样&#xff0c;通过较少的远程数据传输&#xff0c;Operator间数据传输可以使用更多的网络带宽&#xff0c;从而进一步提高性能。

最后&#xff0c;我们在SSE工作负载下评估Elasticutor的可伸缩性。 我们改变计算集群的大小&#xff0c;即节点的数量&#xff0c;并测量Elasticutor的吞吐量和调度成本&#xff0c;即动态调度器计算新的CPU到执行器分配所需的平均时间。 保持较低的调度成本对于系统适应动态工作负载非常重要。 表3显示了随着规模增加的吞吐量和调度成本。 我们观察到随着集群的增长&#xff0c;吞吐量几乎呈线性增长; 并且调度成本大约是几毫秒&#xff0c;并且随着节点数量的增加而略有增长.
Stream Processing System 早期的流处理系统&#xff0c;如Aurora [7]&#xff0c;Borealis [6]&#xff0c;TelegraphCQ [17]和STREAM [10]&#xff0c;旨在通过利用分布式但静态的计算资源来处理海量数据更新。 借助云计算技术&#xff0c;出现了新一代流系统&#xff0c;重点是并行数据处理&#xff0c;可用性和容错&#xff0c;以充分利用基于云的平台上的灵活资源管理方案。 Spark Streaming [50]&#xff0c;Storm [43]&#xff0c;Samza [35]&#xff0c;Heron [31]&#xff0c;Flink [12]和Waterwheel [46]是最流行的开源系统&#xff0c;提供分布式流处理和分析。 大型工业企业也在开发内部分布式流系统&#xff0c;如Muppet [32]&#xff0c;MillWheel [8]&#xff0c;Trill [16]&#xff0c;Dataflow [9]和StreamScope [33]。
Elasticity.大量的工作探索了实现弹性的可能性。卡斯特罗等人。 [15]将资源重新扩展操作与分布式流系统中的容错功能相结合&#xff0c;以便在迁移到新计算节点之前将与处理逻辑绑定的中间状态写入持久性存储。王等人。 [47]提出了弹性流水线技术&#xff0c;以便为分布式SQL查询启用动态&#xff0c;工作负载感知的运行时重新配置。在Flux [39]中提出了一种自适应分区算子&#xff0c;以实现节点之间的分区移动以实现负载平衡。但是&#xff0c;由于其工作负载迁移基于每个分区&#xff0c;因此当单个分区超出群集中任何节点的处理能力时&#xff0c;此方法将面临困难。 ChronoStream [48]将计算状态划分为一个集合的粒度切片单元&#xff0c;并在节点之间动态分配它们以支持弹性。 Gedik等人。 [24]提出了在不违反状态一致性的情况下扩展有状态运算符的机制。 Chi [34]是一个具有监控和动态重新配置功能的控制面板。然而&#xff0c;这些方法在以资源为中心的标准之后实现了弹性&#xff0c;这导致了昂贵的同步并且妨碍了快速弹性。它们适用于以粗糙时间粒度使用弹性功能的情况&#xff0c;即每5分钟;实现的弹性太慢&#xff0c;无法应用于具有高动态工作负载的应用中。 Elasticutor采用新的以执行器为中心的方法来避免这个问题。此方法大大降低了执行工作负载重新同步的同步开销&#xff0c;因此可在几毫秒内实现工作负载重新分配。
Workload Distribution。分布式流系统的通用工作负载分配是一个具有挑战性的问题&#xff0c;因为随着时间的推移&#xff0c;输入数据流的偏差很大并且差异很大。 Shah [39]等。为传统流处理框架中的单个操作设计了动态工作负载再分配机制&#xff0c;例如Borealis [6]。 [24]和[20]研究了混合路由策略&#xff0c;通过其密钥对工作负载进行分组&#xff0c;以便根据CPU&#xff0c;内存和带宽资源动态平衡负载。 TimeStream [38]采用图形重组策略&#xff0c;直接用全新的处理拓扑替换原始处理拓扑。然而&#xff0c;系统在所有可应用的图形结构的巨大搜索空间中监视和优化拓扑结构具有挑战性。 Cardellini等。 [13]研究了Storm之上的有状态任务迁移。丁等人。 [18]讨论了基于马尔可夫决策过程&#xff08;MDP&#xff09;制定任务迁移计划的长期优化&#xff0c;以提高分布式流引擎的资源利用率。但是&#xff0c;Elasticutor不仅可以实现工作负载分配中的负载平衡&#xff0c;还可以考虑迁移成本最小化和计算局部性。
我们设计并实现了Elasticutor&#xff0c;它为流处理系统提供了快速弹性。 弹性器遵循一种新的以执行器为中心的方法&#xff0c;该方法将执行程序静态绑定到运算符&#xff0c;但允许执行程序独立扩展。 这种方法将操作员的扩展与有状态处理所需的全局同步分离开来。 Elasticutor框架有两个构建块&#xff1a;弹性执行器&#xff0c;执行动态负载平衡&#xff0c;以及优化计算资源使用的调度程序。 实验表明&#xff0c;与传统的以资源为中心的提供弹性的方法相比&#xff0c;弹性器使吞吐量增加一倍&#xff0c;平均延迟降低了几个数量级。


 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 