论文地址:Learning Identity Mappings with Residual Gates
本文地址:http://blog.csdn.net/wspba/article/details/72789964
前言
自从2015年ResNet在ImageNet比赛上火了之后,现在简直就是大红大紫啊,这两年关于ResNet的研究、基于ResNet网络的延伸、改进也越来越多,包括FractalNet、WideResNet、DenseNet等等,这几篇文章都会一一为大家介绍,今天要介绍的叫做Gated ResNet,它来自一篇发表在今年ICLR上的论文,它没有之前提到的几个网络复杂,它对ResNet所提出的Identity Mapping进行了更加细致的思靠,它认为Identity Mapping才是ResNet包括Highway Network的精髓,并提出了对于一个深层网络,如果它具有退化成Identity Mapping的能力,那么它一定是容易优化、并且具有很好性能的。
精髓:Identity Mapping
ResNet中所提出的Residual block之所以成功,原因有两点,第一,是它的shortcut connection增加了它的信息流动,第二,就是它认为对于一个堆叠的非线性层,那么它最优的情况就是让它成为一个恒等映射,但是shortcut connection的存在恰好使得它能够更加容易的变成一个Identity Mapping。对于第二点,其实刚开始看ResNet原文时,并没有完全理解,直到看到今天所讲的这篇论文时才正真理解到它的含义。
看下图:

下面那行的网络其实就是在上面那行网络的基础上新叠加了一层,而新叠加上那层的权重weight,如果能够学习成为一个恒等的矩阵I,那么其实上下两个网络是等价的,那么也就是说如果继续堆叠的层如果能够学到一个恒等矩阵,那么经过堆叠的网络是不会比原始网络的性能差的,也就是说,如果能够很容易的学到一个恒等映射,那么更深层的网络也就更容易产生更好的性能。这是ResNet所提出的根源,也是本文所强调的重点。
对于一个网络中的一个卷积层f(x,W),W是卷积层的权重,如果要使得这个卷积层是一个恒等映射,即f(x,W)=x,那么W就应该是一个恒等映射I,但是当模型的网络变深时,要使得W=I 就不那么容易。对于ResNet的每一个Residual Block,要使得它为一个恒等映射,即f(x,W)+x=x,就只要使得W=0即可,而学习一个全0的矩阵比学习一个恒等矩阵要容易的多,这就是ResNet在层数达到几百上千层时,依然不存在优化难题的原因。
改进:Residual Gates
学习一个全0矩阵,是要使得一个矩阵中所有的值都为0,那么还有没有更简单的方法呢?比如说,只要一个值为0就够了?这恰恰就是本文的亮点:Residual Gates。
下图是基于plain network的一个改进:
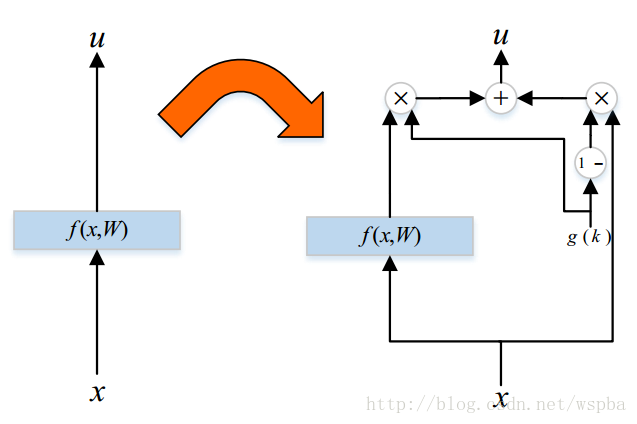
这样f(x,W)就变成了g(k)f(x,W)+(1-g(k))x,很熟悉有没有,是不是很像Highway Network: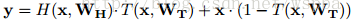 ,但是Highway Network仍然需要学习一个以x为输入的函数T(x,Wt),使Wt为全0矩阵时,整个网络才相当于恒等映射。而在这里,只需要g(k)等于0表示为恒等映射,注意到这里k也是模型的一个参数,也是通过模型的前向和反向训练得出,g为激活函数(ReLU),即只要k学习到一个接近于0或者小于0(由于ReLU的存在)的值,或者k=1,W=I即可,比单纯指望W学习到I要简单得多。按照作者的意思,这个模型就具有了退化成恒等映射的能力,因此当层数加深时,是能够提升模型的性能的。
,但是Highway Network仍然需要学习一个以x为输入的函数T(x,Wt),使Wt为全0矩阵时,整个网络才相当于恒等映射。而在这里,只需要g(k)等于0表示为恒等映射,注意到这里k也是模型的一个参数,也是通过模型的前向和反向训练得出,g为激活函数(ReLU),即只要k学习到一个接近于0或者小于0(由于ReLU的存在)的值,或者k=1,W=I即可,比单纯指望W学习到I要简单得多。按照作者的意思,这个模型就具有了退化成恒等映射的能力,因此当层数加深时,是能够提升模型的性能的。
而对于ResNet,也可以使用同样的Gates:
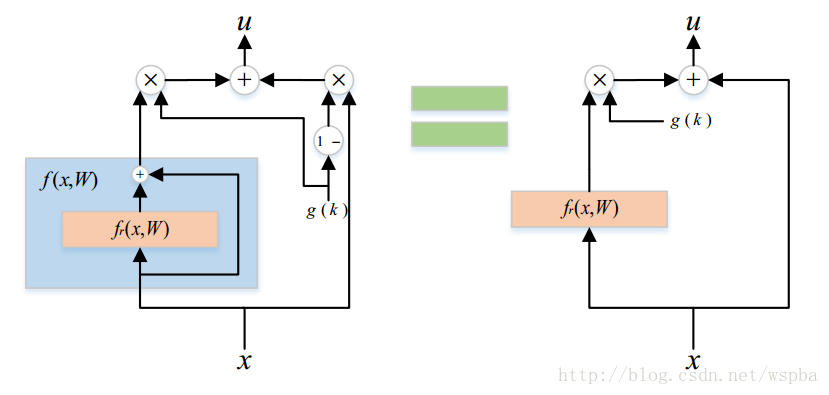
即:g(k)(f(x,W)+x)+(1-g(k))x=g(k)f(x,W)+x ,这样看来g(k)甚至都不需要作为门控的功能,只要相当于一个缩放的作用,相比于原始ResNet需要W学成全0矩阵而言,使得g(k)等于0更加简单,因此作者推断,门控版的Gates ResNet要强于原始的ResNet。
实验
模型在MINIST和CIFAR-10数据集上的结果在这里就不多进行展示和解释。但是有几点我也是比较感兴趣的。
首先:
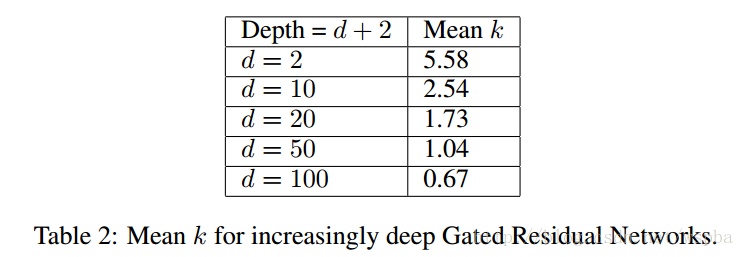
当模型较浅时,参数优化简单,因此k的作用体现不出来,而且k值很大,可能起到的是一个信号的放大或者增强的作用;但是当层数逐渐增加时,k值慢慢减小,比如上图,d=100时,k的均值只有0.67,那么在很多层中,k的值应该是很接近与0的,这些层起到的就是恒等映射的作用,这也就验证了作者的观点。
其次,另外一个图,这是一个100层的深层模型:
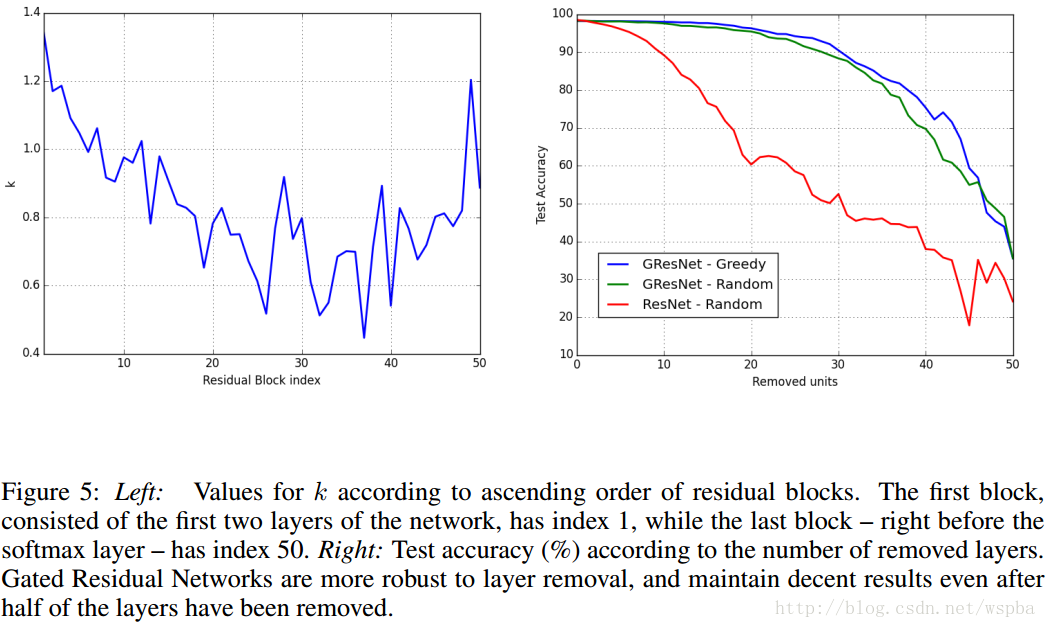
作者发现在ResNet中,k值可能在中间的某些曾具有更低的值,而作者认为,当k接近于0时,该层接近于恒等映射,那么该层可能起到更多的就是信息传递,而不是信息提取的作用,因此,对于整个模型的影响并不大,那么将这些层剔除,模型的性能应该也不会有太大的影响。右图的曲线也证明了这点,作者的这个发现,为模型的压缩也提供的新的思路。
基于第二个发现,在只有24层的浅层模型中:
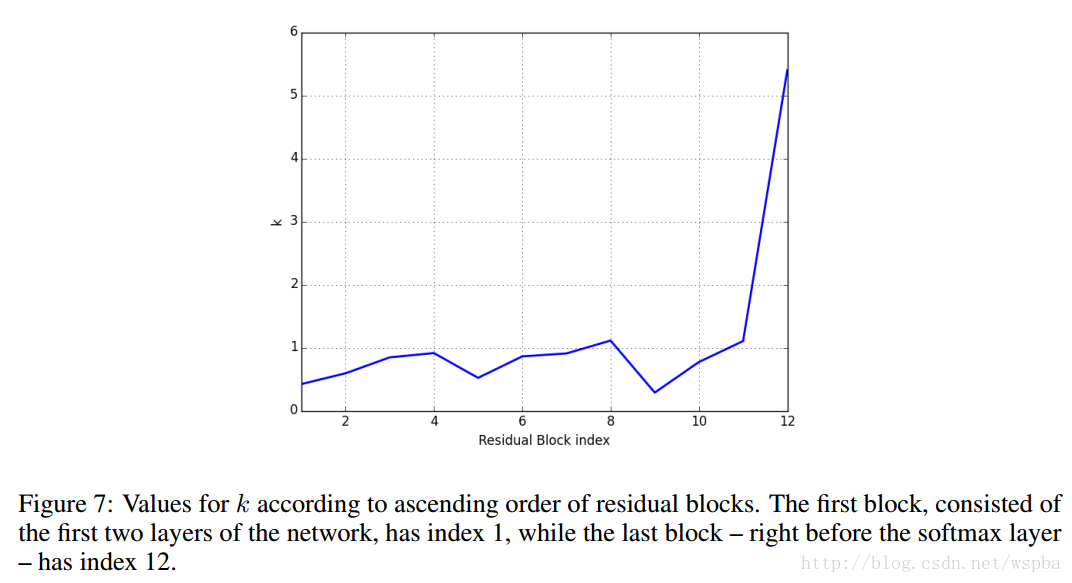
我们发现,在第1、5、9个residual block中,k值很低,而第1、5、9个residual block正好对应了维度上升的层(不明白的可以回去看Wide ResNet或者ResNet的模型结构),这说明了在升维的residual block中,shortcut connection中用来增加维度卷积层起到了更加重要的作用,而在最后一个block中,k值非常高,也就是说明在这里,shortcut connection几乎不起到作用,因此将shortcut connection去除也几乎没有影响。
总结
这篇论文给模型的设计和优化提供了很好的思路,它提出了一个叫做模型退化成恒等映射的能力,即,如果模型具有退化成恒等映射的能力,那么堆叠很多这样的层,将不会比更浅的层效果要差。提出了一个只有单一参数的门控机制,它是的普通的平原网络,甚至是本来就性能很好的ResNet,变得更好,原因是一个参数的学习总会比多维权重的学习更加简单。最后,作者还给出了一个对模型理解以及优化的思路,对于一个含有门控机制的训练好的模型,我们可以通过观察k的值,来判断各个层的作用,并且根据作用的重要性,可以对不重要的层进行剔除而不影响到模型的效果,起到了一个模型压缩的作用。
总的来说,这篇论文真的是非常棒的文章,值得大家细细品读,当然论文中还有很多理解不到位的地方,也希望大家能够提出来,一起交流一起学习!





 京公网安备 11010802041100号
京公网安备 11010802041100号