作者:miss文女1977 | 来源:互联网 | 2023-09-24 07:11
什么是RefinedArchitectureRefinedArchitecture相对于ConceptualArchitecture而言,分别对应于“概念级”解决方案和“规约级”解
什么是Refined Architecture
Refined Architecture相对于Conceptual Architecture而言,分别对应于“概念级”解决方案和“规约级”解决方案。Refined Architecture(细化架构)属于架构设计,不能与Detailed Design(详细设计)相混淆。
架构领域最喜欢将建筑设计的多视图方法与软件架构设计的多视图方法做类比。
实际意义
多视图方法的价值:
1.利于思考
2.便于交流
实践要领
5视图方法
总图:每个视图,一个思维角度
5视图方法包括下面几个视图:
逻辑视图。
开发视图。
运行视图。
物理视图。
数据视图。
5个视图各自“思维立足点”:
职责划分(逻辑视图)。
程序单元组织(开发视图)。
控制流组织(运行视图)。
物理节点安排(物理视图)。
持久化设计(数据视图)。
详图:每个视图,一组技术关注点
5视图方法梳理众多技术关注点:
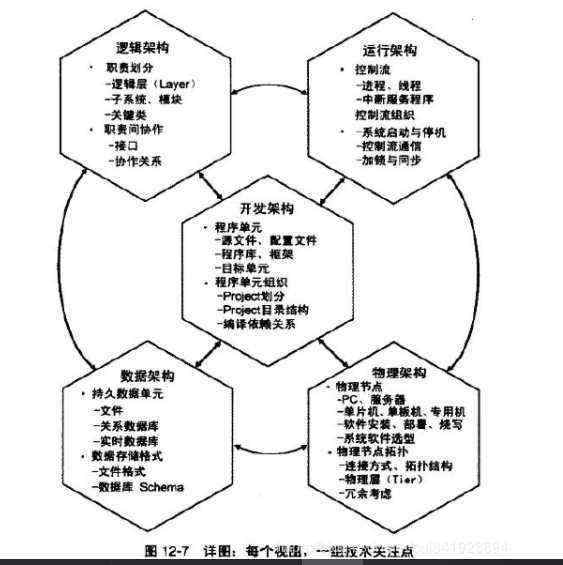
逻辑架构
划分子系统的3种比用策略
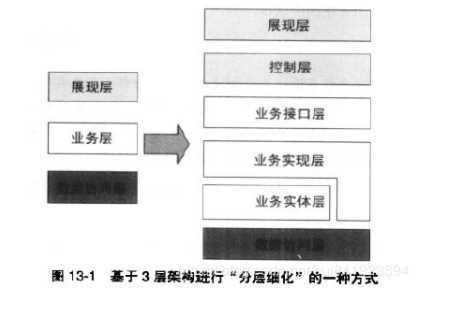
分层的细化
分层是最常用的架构模式。3层或4层架构支持团队的并行开发远远不够,需要“分层细化”(更多层)。
分区的引入
为了支持迭代开发,逻辑架构设计中必须引入分区。分区是一种单元,它位于某个曾的内部,粒度比层要小。
一旦架构师对每个层进行分区设计,“深度优先”式的迭代开发就非常自然。
机制的提取
机制定义:软件系统中的机制,是指预先定义好的、能够完成预期目标的、基于抽象角色的协作方式。机制不仅包含了协作关系,同时也包含了协作流程。
对于面向对象方法而言,“协作”可以被定义为“多个对象为完成某种目标而进行的交互”,而“协作”和“机制”的区别可以概括为:基于接口(和抽象类)的协作是机制,基于具体类的协作则算不上机制。
分层的细化、分区的引入、机制的提取这3种策略背后的4个通用设计原则:
职责不同的单元划归不同子系统。
通用性不同的单元划归不同子系统。
需要不同开发技能的单元划归不同子系统。
兼顾工作量的相对均衡,进一步切分太大的子系统。
逻辑架构设计的整体思维套路
要点:
质疑驱动。
结构设计和行为设计相分离。
架构设计不是一蹴而就。需求对架构设计有“驱动”作用,不断设计中间成果->质疑中间成果->不断调整完善细化中间成果->继续质疑->继续完善…
更多经验总结
物理架构
为什么需要物理结构设计
有时候增加硬件未必能解决问题;
软件实际服务能力不仅受到“硬件资源”的制约,也受到“数据短缺”和“数据争用”的制约。
增加硬件 = 增加计算能力 不等于 软件的实际服务能力增强
物理结构关注如何可以满足软件系统的可靠性、可伸缩性、持续可用性、性能、安全性等方面的要求。
物理架构设计的工作内容
物理架构设计主要的3项任务:
硬件选择和物理拓扑。
软件到硬件的映射关系。
方案的优化。
物理架构的设计思维
从设计结果层面,决策无非围绕物理节点、网络、软件单元、数据单元等内容展开。
运行架构
为什么需要运行架构设计
当系统并不引入任何并行或并发处理,并且也没有给予SDK、API等基础软件进行定制开发,那就不需要设计运行架构设计。
如果系统为了应对复杂的业务逻辑或者复杂的互操作逻辑(含硬件交互),或者为了优化关键资源使用效率,而必须借助多条控制流并行或者并发执行时,就需要设计运行架构。
运行架构设计工作内容
运行架构设计可能根据具体情况不同包括下列工作内容:
确定引入哪些控制流。
确定每条控制流的任务。
处理相关问题:控制流的创建、销毁、通信机制等。
进一步考虑:控制流之间的同步关系,若有资源争用还要引入加锁机制。
控制流图是关键。运行架构设计的工作看似多而杂,单其实只要把握“控制流图”,就能够提纲挈领地开展其他相关设计。
实现控制流的3种常见手段
最常用于实现控制流的3种手段:
进程、线程、中断服务程序。
开发架构
为什么开发架构是必须的
并行开发所需的“程序单元”、“源码目录结构”等概念,是不同程序团队开展具体工作的基础。
能支持并行的详细设计。
让程序经理参与到架构实践的工作,免去大量的“单纯架构交流”的工作量,更让程序人员有“成就感”。
开发架构设计的工作内容
一般完成:
1.将“逻辑职责”映射为“程序单元”:
要自主编写的源程序
可重用的库、框架
其他方式(如shell脚本、平台支持下的配置文件)
2.开发技术选型
开发语言
开发工具
3.“程序单元”间的关系
Project划分
Project目录结构
编译依赖关系
重用测试是关键
解决年复一年修复类似问题的问题
从根本上降低维护成本
数据分布
数据分布的6种策略
1.独立Schema
当一个大系统由相关的多个小系统组成,且不同小系统具有互不相同的数据库Schema定义,这种情况称为“独立Schema”。
如果可以架构师应首选此种分布策略,以减少系统间无谓的互相影响,避免人为地将问题复杂化。
2.集中(Centralized)
指一个大系统必须支持来自不同地点的访问,或者该系统由相关的多个小系统组成,而将持久集中化数据进行集中化的、统一格式的存储。
特点:集中存储、分布访问
3.分区(Partitioned)
分区方式包括水平分区和垂直分区。
当系统要为“地域分布广泛的用户”提供“相同的服务”时,常常采用水平分区。特点:两个相同,两个不同——相同的应用程序、不同的应用程序部署实例,相同的数据类型、不同的数据值。
一般垂直分区作用较小。特点:不同数据节点的Schema会有“部分字段”的差异。
4.复制(Replicated)
整个分布式系统中,数据保存多个副本,并且以某种机制(实时或快照)保持多个数据副本之间的数据一致性。
特点:通过数据“本地化”,提升了数据访性能;数据的专门副本,有利于针对性地进行优化;数据的专门副本,提高可管理性,加强安全控制。
5.子集(Subset)
“子集”是“复制”的特殊方式,就是某节点因功能或非功能考虑而保存全体数据的一个相对固定的子集。
子集相对复制特点(优点):减少了跨机器进行数据传递的开销;降低了数据冗余,节省了存储成本。
6.重组(Reorganized)
不同数据节点因要支持的功能不同,而以不同的Schema保存数据——但本质上这些数据是同源的。数据不是直接复制,而是以“重新组织”格式进行传递或者保存。
数据分布策略大局观




 京公网安备 11010802041100号
京公网安备 11010802041100号