续《一个IO的传奇一生(13)—— Linux中的MD开源RAID(1)》
4.6 make_request函数说明
函数原型:static int make_request (request_queue_t *q, struct bio * bi)
参数:*q,请求队列
*bi,IO请求数据结构
各个RAID Level的IO请求函数相同,但是他们的实现是不一样的。RAID1中make_request()函数的主要功能是将上层的bio分发到底层驱动中去,但是,RAID5中的函数并没有实现这样的功能,其主要实现的功能如下:
1. 通过raid5_compute_sector()函数得到逻辑块号所对应的实际物理块号,另外还得到了RAID磁盘阵列中所对应的数据盘索引和校验盘索引。
2. 通过get_active_stripe()函数得到一个stripe,如果在stripe的hash表中无法找到sector对应的条带,那么就从inactive_list中分配一个stripe,如果没有多余的条带,那么整个操作无法进行。如果能够得到一个active的stripe,那么将输入的bio直接挂接到active_stripe上。
3. 调用handle_stripe()函数实现真正的IO读写请求操作。
从上面的分析可以看出,RAID5的make_request()函数实际上实现了条带(stripe)的查找/申请和bio请求数据结构的挂接事情。真正的读写操作由handle_stripe()实现。
4.7 sync_request函数说明
Sync_request()这个函数是RAID5的同步处理函数。
该函数注册到md的mdk_personality_s结构体下的sync_request中。
因此,在md_do_sync()函数中可以采用如下方法来调用RAID5的同步处理函数:
mddev->pers->sync_request(mddev, j, currspeed
在分析md_check_recovery()这个函数的时候,我们可以看到,当需要做数据同步或者数据恢复的时候,md_check_recovery()是需要调用md_do_sync()过程的。
函数原型:static int sync_request (mddev_t *mddev, sector_t sector_nr, int go_faster)
输入参数: *mddev,md设备
Sector_nr,起始扇区
go_faster,需不需要延迟操作
返回值:这一次完成的扇区数目
4.8 raid5d函数说明
这是RAID5的守护线程,该函数在RAID5初始化的时候被注册:
mddev->thread = md_register_thread(raid5d, mddev, "%s_raid5");
在守护线程运行的一开始会调用md_check_recovery(),通过该函数来检查存储是否有故障,如果有故障,那么调用md_do_sync()函数。md_do_sync()函数实际上是不会完成具体同步工作的,它会调用相应级别的RAID同步处理函数sync_request()去实现具体功能。
Raid5d()守护线程是一个while(1)的死循环,他的退出条件是:list_empty(&conf->handle_list)。即当handle_list为空的情况下,raid5d退出睡眠。
Raid5d()守护线程从handle_list中得到active stripe,然后调用handle_stripe()函数对该stripe进行处理。
Handle_stripe()处理完之后,该stripe又被挂接到不活动的list(inactive list)上。
4.9 两个IO读写回调函数说明
RAID5中有两个请求结束回调函数,他们为:
1、raid5_end_read_request()
2、raid5_end_write_request()
这两个回调函数在generic_make_request()的时候被注册到bio中。
Raid5_end_read_request()函数实现如下功能:
u 清除IO请求标志:R5_LOCKED
u 如果数据有效(update),那么设置数据有效标记:R5_UPTODATE
u 如果数据读写错误,那么调用md_error(),需要recovery。
u 设置stripe的handle_list标记,STRIPE_HANDLE,说明要让Raid5d()调用handle_stripe进行处理
Raid5_end_write_request()函数实现如下功能:
u 清除IO请求标记:R5_LOCKED
u 如果写发生错误(uptodate == 0),那么调用md_error(),需要recovery。
u 设置stripe的标记STRIPE_HANDLE,说明要让raid5d()调用handle_stripe()进行处理。
4.10 出错函数error说明
error()函数是RAID5出错处理函数,其被注册到mdk_personality_t的error_handler函数上,所以在MD驱动程序中当出现IO读写错误的时候,直接调用md_error()函数即可。
在raid5.c文件中,有两个地方调度md_error(),他们是raid_end_read_request()和raid_end_write_request()这两个回调函数。当读写I/O错误的时候,回调函数就会调用md_error(),然后设置相应的标志位,进行recovery操作。
函数原型:static void error(mddev_t *mddev, mdk_rdev_t *rdev)
参数: *mddev,md设备的数据结构
*rdev,具体出错的设备
4.11 list链表处理函数release_stripe说明
release_stripe()函数封装了_release_stripe()。因此,讨论_release_stripe()。
函数原型:static inline void __release_stripe(raid5_conf_t *conf, struct stripe_head *sh)
参数:*conf,RAID5私有数据结构体
*sh,需要处理的stripe
该函数实现了handle_list,delayed_list和inactive_list链表之间的转换关系处理。
首先需要讲一下几个重要的状态标记:
1、 STRIPE_PREREAD_ACTIVE:该标记为预读标记,当RAID5 进行IO写的时候需要进行该标记的判断,即在读的第一阶段需要判断该标记。实际上根据字面意思也知道,在写操作的时候需要一个pre_read过程,即读操作的第一个步骤。
2、 STRIPE_DELAYED:该标记为延迟处理标记,该标记有效时,release_stripe()函数会将list挂接到delayed_list中。
从上面的分析中,我们可以看到写操作的第一个步骤是一个pre_read的过程,并且是一个延迟操作的过程。延迟操作往往需要等到handle_list中的stripe处理完成之后,再从delayed_list挂接到handle_stripe中。因为在写操作的第一阶段需要置Wantread标记,调度一个读操作,那么STRIPE_PREREAD_ACTIVE标记必须有效。而该标记的设置在raid5_activate_delayed()函数中实现。该函数的调用又需要等到handle_list为空(raid5d()中实现)。这个过程可以描述成如下流程:

Release_stripe()函数执行过程:
1、 当STRIPE_HANDLE标记有效的时候,可以将stripe挂接到handle_list或者delayed_list上,否则这个stripe将会被挂接到inactive_list上。
2、 当STRIPE_DELAYED标记有效的时候,stripe将会被挂接到delayed_list上,实现一个延迟处理。否则,stripe将会被挂接到handle_list上。
3、 挂接到handle_list或者delayed_list上之后,调用md_wakeup_thread(conf->mddev->thread)函数唤醒守护进程。
5、RAID5 中I/O读写方法
RAID5中I/O的读写操作由make_request发起,该函数被注册到mdk_personality_s结构的make_request函数中,当操作系统调用make_request_fn函数进行块设备读写操作的时候,直接调用make_request()函数实现相应功能。
在RAID1的make_request函数中直接将上层的bio分发下去,实现IO读写操作,但是在RAID5中的实现方法有所不同,其调用了handle_stripe函数实现读写操作。
RAID5中实现IO读写操作的函数主要有:
1、 make_request()。该函数传递上层发送的IO请求
2、 handle_stripe()。实现IO读写请求的主干函数
3、 generic_make_request()。发送IO请求至底层驱动程序
4、 raid5_end_read_request()。读操作结束回调函数
5、 raid5_end_write_request()。写操作结束回调函数
6、 release_stripe()。Sh挂接至handle_list处理函数
7、 raid5d()。守护线程
I/O写操作过程:
写操作过程历经如下函数调用过程:
读取数据过程:
Make_request()-> handle_stripe()->generic_make_request()底层驱动工作…
计算/写数据过程:
Raid5_end_read_request()-> release_stripe()-> raid5d ()-> handle_stripe()底层驱动工作…
结束写过程:
Raid5_end_write_request()->release_stripe()->raid5d()->handle_stripe()
具体的IO写过程参考handle_stripe()写过程分析。
I/O读操作过程:
IO读过程比较简单,其经历的函数调用过程如下:
调度一个读过程:
Make_request()-> handle_stripe()-> generic_make_request()底层驱动工作…
从page缓存中拷贝数据:
Raid5_end_read_request()-> release_stripe()-> raid5d()-> handle_stripe()
具体的分析可以参考handle_stripe()读过程分析。
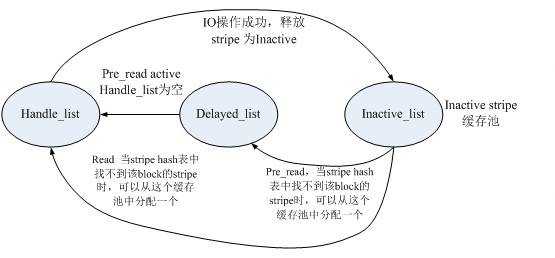
6、几个list的关系及数据挂接关系
RAID5中涉及的几个list:
1、 handle_list:这个list中的stripe需要分发执行
2、 delayed_list:这个list中的stripe延迟分发执行
3、 inactive_list:这个list中的stripe为不活动的条带
当需要进行一个IO操作的时候,首先要获取一个active stripe(get_active_stripe()函数实现),这个stripe可以从hash表中找到,当找不到的时候,可以从inactive_list中请求一个(get_free_stripe()函数实现)。当handle_stripe()函数将stripe处理完毕之后,release_stripe()函数又将stripe放入inactive_list。
几个list的挂接关系可以基本描述如下:
7、错误处理数据恢复方法
RAID需要进行IO的出错处理。在RAID5这个级别可以纠正由于一个磁盘故障导致的错误,在raid驱动中通过error()函数来报错,然后通过md_check_recovery()函数来检错,通过md_do_sync()、sync_request()函数来纠错。他的运行机制和相互之间的逻辑关系又是怎样的呢?
基本的数据恢复过程如下图所示:
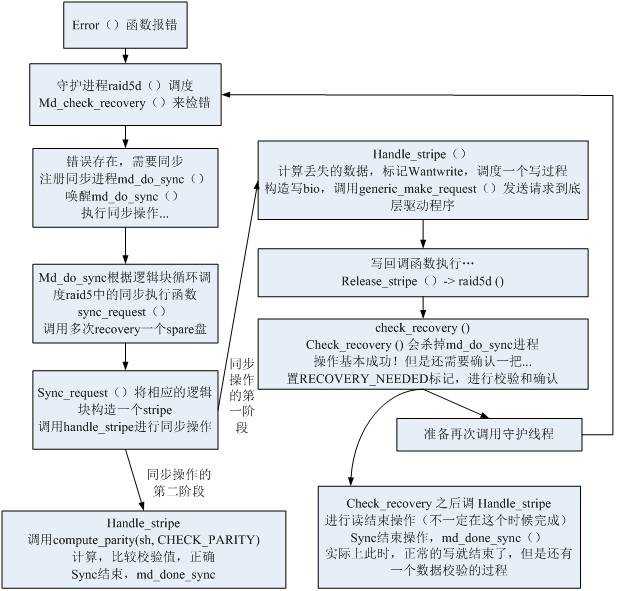
在RAID5系统中,其数据同步/恢复操作分为两个阶段:
1、 数据写阶段,将有效数据写到spare盘上去。
2、 数据校验阶段,确认校验和是否正确,如果正确,那么整个recovery操作才算真正的结束。
<结束>
本文出自 “存储之道” 博客,请务必保留此出处http://alanwu.blog.51cto.com/3652632/1549758
一个IO的传奇一生(14)—— Linux中的MD开源RAID(2)









 京公网安备 11010802041100号
京公网安备 11010802041100号