作者:心情爱心_634 | 来源:互联网 | 2023-07-26 09:44
一、引言P2SP是迅雷公司自造的术语,其定义为:他不但支持P2P技术,害通过多媒体检索数据库这个桥梁把原本孤立的服务器资源和P2P资源整合在一起在P2SP中,迅雷大致确立了用户辅助
一、引言
- P2SP是迅雷公司自造的术语,其定义为:他不但支持P2P技术,害通过多媒体检索数据库这个桥梁把原本孤立的服务器资源和P2P资源整合在一起

- 在P2SP中,迅雷大致确立了用户辅助开发模式。在中小规模的文件、专有文件的分发中,服务器负担了文件上传的主要部分,peer只是承担小部分。
- 迅雷作为一个公共下载平台,并不是发明出cs及p2p以外的下载方法,只是通过这个组织形成网络上的一个平台。因此研究迅雷应是研究他做了哪些必要的组织工作,如何对服务器和客户进行承诺的,实际上又是如何实现这些承诺的,以及平台所提供的下载质量。
- 下载过程的演进
最开始,文件下载是浏览器提供的,用户通过点击页面上的一个特定链接触发对该链接指向文件的下载,下载是单线程的,且不支持断点续传。对于大文件的下载费时下载带宽限制和费力断了必须通过手工操作重新下载。一般下载数据的规模在一字节的范围。
后来出现了NetAnts和FlashGet这类下载代理工具,通过多线程,断点续传和自动重新连接等措施提高了下载的速度和人工干预的过程。不过它仍然维持了原先文件下载中的sever-Client的关系。一般人们也就是下载十几,二十几字节的文件。下载的瓶颈从用户的接入带宽部分转移到了服务器的接入带宽和处理器处理能力上。
再后来出现了eMule和BitTorrent这样的P2P下载工具,能够一气下载几百M到几个G字节规模的文件。这样一个环境就像一个自由集市,用户自己提供资源,大家共享,根本无法实施任何程度的产权保护.
- 一个P2P的分发模式远比server-client模式复杂。后者一般只需要一台服务器,而前者一般需要的是一个平台。所谓一个平台,是指一个分工且相互密切联系的服务器群,他们要协同完成对每一个文件的在线用户收集,甄别和记录的工作,要对新加入的以及任何提出请求的老用户提供在线用户列表等等.
二、理解P2SP
P2SP平台的一般意义
- 体系结构如图所示
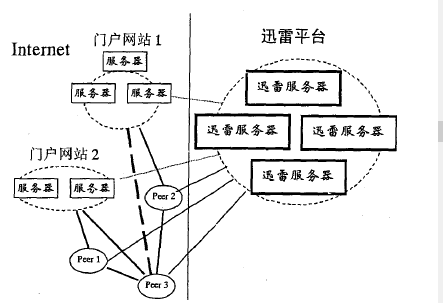
- 与经典P2P的主要不同,是平台所服务的对象不再是单一类型的用户,而是两类不
同的客户,并希望在不同类型客户的不同服务质量要求和安全要求间寻找策略平
衡,在有一定安全的保障下实现最快速的服务。
- 由于大量相同的文件会存放在许多不同的服务商处,因此客户可以选择他向哪个服务商来索取他所要的一个特定文件。也就是说不是用户直接通知我要什么,而是客户必须首先和某个服务商签约而形成一种合同关系。然后才能通过迅雷平台得到相应的服务。
- 很好的总结服务商和用户商之间的关系
用户和服务商是通过签约开始服务和被服务关系的,而这个商业关系中隐含了双方关于:
- 文件下载速率的要求
- 下载文件质量的要求
- 文件下载中的安全的要求
服务商的目标
- 和尽可能多的用户签约并实现服务
- 仅仅提供文件上载服务,
- 希望只为与我签约的客户服务,
- 但又同时希望我的签约客户之间可以实现文件共享,减轻我的服
务器的压力
用户
- 尽量快的下载完我要的文件,但不在乎文件的哪个部分由哪个人提供
- 希望保证下载的文件具有我签约的那个服务商所具有的信誉和可靠性
保障如没有病毒,没有损坏等等
- 如果出事可以向签约服务商投
- 迅雷选择的策略不是包含了上面全部,而是:
形式上支持签约的合同服务模式
- 用户可以方便的通过签约方式进入迅雷系统从而开始接受服务
- 签约服务商一定可以对签约用户实现服务
- 用户经常会通过迅雷系统得知能够提供相同服务的其他服务商及其连接关系
- 用户原则上可以通过迅雷的帮助与其他服务商实现非签约的服务
- 其他服务商一般会通过自己的签约系统阻止这样的非签约服务
以保障用户的下载速度为第一体验
- 迅雷向签约用户提供某些非签约服务商的信息
- 迅雷在返回列表时并不刻意区分的签约服务商,甚至并不保障返回列表中的用户的在线状况
- 迅雷对每个文件记录每个用户的下载日志也就是说迅雷可以支持限定返回用户列表的签约属性
服务商的信誉和用户得到的最终文件质量能够部分得到保障
- 迅雷是按照签约用户的索取文件组织共享的,因此如果没有特别刻意的攻击的情况下,用户将下载得到的文件,应该原则上是他索取的那个签约服务商所提供文件的忠实副本。
- 迅雷的盗链问题需要注意
目前对其指责的盗链问题,实际上主要是指其
- 提供自己的搜索工具,并引导用户以不签约的方式得到服务
- 在签约用户的服务中提供非签约服务商信息,以及
- 记录用户下载信息并在无预告知的情况下强迫用户作为“seed”上载己下载文件。
三、工作流程分析
启动中的迅雷服务器
客户端最开始接入迅雷平台所采用的主要形式是客户端首先通过DNS对迅雷的固定域名进行查询,直接从得到迅雷服务器的IP地址,然后通过这个地址去和迅雷平台建立最初的联系,联系中会同时使用TCP与UDP协议.
迅雷有多个服务器,不同服务器有域名,也有对应的IP地址,有一个域
名对应多个地址的情况,也有多个域名对应一个地址的情况。不同的服务器有不同的功能,比如有用于存储资源和向用户发放所需资源列表的服务器;有提供广告索引的服务器;有广告内容存放的服务器;有热门图片存放的服务器;有查病毒的服务器。
启动过程中的报文协议
- 迅雷每次启动时会查询域名“hub5pn.sandai.net”,目前发现这个域名对应
的IP地址只有两个60.19.64.60和58.254.39.5。客户端不会与这两个IP地址都进
行报文交互,只会与DNS查询结果包中位于第一个的进行交互,使用的报文是UDP.
- 客户端向迅雷tracker发送一个UDP连接报文,如果有响应,则在启动阶段,不会再发连接报文,否则会以第一次发送的时间为起始,每隔10秒向tracker发送连接报文,3次为一组,每组的间隔时间为2分钟。(论文中有讲到报文的格式)
- tracker的响应报文中有返回IP地址(称为迅雷nodes)和nodes的端口号,之后客户端就会使用端口号和nodes交互信息
3. 启动后还会向main server发一个包。主要信息是客户主机的MAC地址,main server不会回复响应包。如果收到tracker的响应包里有关于nodes信息,则客户端会向main server连续发三个包,除了包括本用户的信息,还标识出nodes的信息。
4. 客户端会每隔10秒使用中的回应请求报文去与某个server交互。这类server我们称其为“keep-alive server”。分析normal state及下载过程时发现,这个规律一直存在
5.客户端也会和辅助server进行报文交互。报文格式和与tracker交互的比较类似,有时也会返回nodes的信息,然后客户端会和交互信息,但是不会将nodes的信息向server报告。
空闲状态和空闲过程
迅雷客户端在空闲状态并不完全空闲,它主要工作,是向迅雷平台定期汇报
自己的存在。有比较明显的以下四个规律:
- 每隔10秒使用ICMP报文中的回应请求报文与keep-alive server交互。
- 每隔45秒与nodes使用UDP报文交互。
- 每隔2分钟与辅助server使用UDP报文交互。
- 每隔5分钟向main server发送UDP报文
下载过程
cfg文件
使用迅雷下载一个文件时,在下载过程中会自动生成两个文件,一个文件的后缀为.td,下载完成后的扩展名会自动去掉另一个文件的后缀是td.cfg,这个
文件是下载过程的日志文件,下载完成后也会自动删除。.cfg文件的内容有:
- 提供下载的站点的,文件存放位置及文件名。
- 提供下载的peer的mac地址,IP,及端口信息。
正是由于cfg文件记录了这种信息,我们可以刻意阻止客户端自动删除这些一记录,并利用这些记录中的信息进行许多有意义的推断工作,如在判断IP的类别时,
使用cfg文件来判断一个IP是否是peer。
迅雷中“资源”的概念
“资源”就是指能够为用户提供下载服务可能存有用户指定文件的其它服务器或peers。因此我们将迅雷平台中专门用于存储资源和向用户发放所需资源列表的服务器称为“资源服务器”。
下载过程分析
- 用户A在服务商的服务器A上点击某URL下载一个文件。
- 迅雷除了与该服务器建立连接外,还会与迅雷的资源服务器建立TCP连接,并发送http资源搜索报文。由于报文是加密的,所以具体的信息无法解析,但推测一定是关于指定下载文件属性的通报。
- 迅雷的资源服务器会在其数据库搜索与用户指定文件匹配的资源记录,并返回资源回应报文,报文的内容也是加密的。猜测资源服务器会根据资源搜索报文的信息查找数据库,如果有这个文件的资源,则会向客户端返回这些资源,如果没有,则将报文的信息作为一条新的资源添加至数据库,为下个用户加速。但是目前还没有找到方法证实猜测。
- 客户端在收到返回时,也会向返回的地址发起连接。
- 开始下载数据,下载过程会重复步骤2,3,4.
- 数据下载完成后,客户端会使用DNS解析域名为“tag.sandai.net”的服务
器。获得其IP后,与它建立TCP连接,发送报文。报文的内容有用户的MAC地址、文件长度、文件名、所用下载时间、原始URL等等。这个服务器的作用是搜集每次下载的信息,将文件的固有属性与进行对应,为资源服务器的数据库提供更新。
迅雷如何区分文件
- 迅雷在下载前,靠URL(而不仅是文件名)和文件大小来区分文件。
- 迅雷在下载完成后,会将文件的某些固有属性(例如大小和MD5)等传回服务器。在服务器端,如果两个文件的固有属性是一样的,则认为它们是同一个文件,与URL无关。












 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有