作者:祁晓波很多研发人员在日常工作中经常回遇到以下两个问题:竟然不可以运行,为什么?竟然可以运行,为什么?因此,他们非常期望可观测能够提供解决问题的思路。引言2017年,推特工程师
作者:祁晓波
很多研发人员在日常工作中经常回遇到以下两个问题:竟然不可以运行,为什么?竟然可以运行,为什么?
因此,他们非常期望可观测能够提供解决问题的思路。
引言

2017 年,推特工程师 Cindy 发表了一篇名为《Monitoring and Observability》的文章,首次将可观测性这一词汇带入开发者视野,通过半开玩笑的方式调侃了关于可观测性和监控的区别。在软件产品和服务领域,监控能够告知我们服务究竟是否能正常运行,而可观测性可以告诉我们为为什么服务没有正常运行。
从谷歌趋势图中可以看到,可观测性的普及率呈现逐年上升的态势,它也被视为系统的属性,将逐步成为系统在做开发设计过程中就需要具备的特性。

可观测发展趋势
2020 年后,可观测的搜索趋势出现井喷,很大一部分原因是 SRE 站点可靠性工程逐步普及,国内大厂纷纷设立相关岗位和对应招聘指标,使得可观测性在国内也得到了较多关注。这也意味着越来越多的基础服务面临了稳定性挑战,而破解稳定性挑战的重要手段就在于提供可观测性。
上图左下角为可观测性的全球搜索趋势,其中中国的搜索热度颇高。

可观测性定义
可观测性是由匈牙利工程师提出的一个数学概念,指系统可以由外部输出推断其内部状态的程度。换句话说,可观测性应当可以从数据产出中分析出其内部的具体运转细节。
难点与挑战
业务蓬勃发展 稳定性诉求激增

F6 汽车科技是一家专注于汽车后市场信息化建设的互联网平台公司,目前处于行业内头部位置。随着业务蓬勃发展,F6 支持的商户数目短时间内暴增数十倍,同时也逐步开展了面向技师等 C 端场景的业务,比如 Vin 码解析、数据查询等,对于稳定性的要求显著提高。
康威定律的作用

康威定律是 IT 史上对整个组织架构进行微服务拆分的指导性定律。任何组织在设计系统过程中都是组织架构的翻版,随着业务膨胀,康威定律作用会导致设计微服务时拆分方式趋同于组织架构,业务增长会导致部门拆分,后续设计微服务时也会十分靠近组织架构。哪怕前期组织架构和微服务拆分不一致,后面微服务也会逐步妥协于组织架构。
虽然微服务和组织架构趋同使得系统沟通效率较高,但是这也带来了很多分布式的系统问题。比如微服务之间的交互,没有人能够对服务有整体性、全局性的了解,研发人员最直接的期望就是在分布式系统中也能有单机系统的排查效率,这促使我们需要将系统以服务器为中心的思路转变为以调用链为中心的思路。
稳定性诉求激增

F6 最早进行业务开发时采用烟囱式的建设。单体应用比较简单,但是它在扩展性和可维护性上存在很多问题。比如所有研发都在系统上进行,代码冲突较多,什么时间点能发布,发布会造成多少业务量损失等皆难以明确。因此,越来越多情况导致我们需要进行微服务拆分,而微服务拆分和调用又会导致调用链十分复杂繁琐,如上图右所示,几乎无法人为分析出调用链路。
那么,怎么样才能尽可能降低线上排查故障的难度?
可观测演进
传统监控+微应用日志收集
- ELKStack 获取日志和查询 ElastAlert 完成日志告警

传统的监控和微服务日志收集一般采用 ELKStack 进行日志收集。ELK 是三个开源项目的首字母缩写,分别是 Elasticsearch、Logstash 和 Kibana。
我们重度依赖 ELK 进行微服务日志的收集,与此同时,还使用了开源的基于 ES 的报警系统 ElastAlert 组件,主要功能是从 ES 中查询出匹配规则,对相关类型数据进行报警。

上图描述了通过日志收集进行日常查询的思路。比如研发人员会通过 pipeling 查询线上日志,ElastAlert 通过匹配规则告警获取到 ES 日志中发掘出来异常数据,kibana 可以进行查询,也可以优先定位出系统中发生的异常。
架构升级+可观测性引入
- Grafana 看板+Zorka 支持 jvm 监控

随着业务发展,系统对日志的要求也逐步增加,比如团队非常多,需要配置各种各样的告警规则,因此我们引入了 Grafana 逐步替代 kibana 和 Zabbix 的查询功能。可以通过 Grafana 的 ES 插件查询对日志进行告警,然后通过 alert 功能完成原先 ElastAlert 的排除,同时可以使用 Grafana 做出更直观的可视化大屏进行展示。
除了日志外,我们也期望收集到 Java 应用指标,因此又引入了 Zorka 开源组件。Zorka 和 Zabbix 可以简单地进行结合,可以通过 Zorka 将收集到的信息上报给 Zabbix 进行展示。而 Zabbix 又可以通过 Grafana Zabbix 插件直接输出数据,最终将整个应用大屏和看板信息都收集到 Grafana 界面。

Zorka 的工作机制类似于通过 Zabbix Java gateway 的方式,通过 Java Agent 自动挂载到 Java 进程中,用于统计常见应用容器和请求数指标等,初步解决了我们对于 Java 进程的观测需求。
云原生改造
- K8s 的编排能力和微服务相辅相成迫切需要 trace 组件的支持

随着微服务程度不断提升,传统方式的运维成本越来越高,因此,我们启动了云原生化改造。
首先,云原生化的改造是 K8s 侧就绪探针和存活探针的编写。存活探针的编写提升了服务的自愈能力,出现了 OOM 后服务能够自动恢复、启动新节点,保证数据服务正常提供。除了 K8s 外,我们还引入了 Prometheus 和 ARMS 应用监控。
Prometheus 作为 CNCF 仅次于 K8s 的 2 号项目,在整个 metrics 领域形成了足够的话语权;ARMS 应用监控作为阿里云商业 APM 的拳头产品,使我们能够结合云原生的方式,实现研发无感,无需进行任何代码改动即可拥有 trace 功能。更重要的是,阿里云团队能够保持持续迭代,支持越来越多中间件,因此我们认为它必定会成为诊断利器。
- JmxExporter 快速支持云原生 Java 组件的 jvm 信息展示

进行云原生化改造后,监控模型也发生了改变。最早的监控模型是 push,Zorka 每次发布都在同一台机器上,因此它有固定的 host;而上云后,容器化改造导致 Pod 不再固定,且可能会出现新的应用扩缩容等问题。因此,我们将监控模型逐步从 push 转换成 pull 模式,也更加契合 Prometheus 的收集模型,并逐步将 Zorka 从可观测体系中剥离。
没有使用 ARMS 直接收集 JMX 指标是因为 ARMS 不会覆盖线上和线下所有 java 应用,没有被覆盖的应用也期望有 JVM 数据收集功能,而 ARMS 成本略高。因此,出于成本的考虑,我们没有将 ARMS 作为完整接入,而是选择了 JMX Exporter 组件。
JMX Export 也是 Prometheus 官方社区提供的 exporter 之一。它通过 Java Agent 利用 Java JMX 机制读取 JVM 信息,可以将数据直接转化成为 Prometheus 可以辨识的 metrics 格式,使 Prometheus 能够对其进行监控和采集,并通过 Prometheus Operator 注册对应的 Service Moninor 完成指标收集。

随着公司业务蓬勃发展,人员激增,微服务暴增,研发人数和告警也剧烈增长。为了提升告警触达率和响应率,我们重新使用了 Apollo 配置中心的多语言 SDK,通过 Go 自研了一套基于 Apollo 业务的应用提醒,整体流程如下:
通过 Grafana 收集到 ES 告警或其他场景下的告警,再通过 metrics 应用关联到 alert ,告警时会转发到前文提到的 Go 语言编写的精准告警服务上。精准告警服务解析到对应应用,根据应用从 Apollo 配置中心中获取到 owner 姓名、手机号等信息,再基于此信息通过钉钉进行告警,极大提升了消息阅读率。

此外,我们还引入了阿里云的应用实时监控服务 ARMS ,能够在没有任何代码改造的前提下,支持绝大部分中间件和框架,比如 Kafka、MySQL、Dubbo 等。云原生化后,仅需要在 deployment 里添加注解即可支持相关探针的加载,微服务的可维护性极为友好。同时,还提供了较为完整的 trace 视图,可以查看线上应用节点调用日志的整个 trace 链路,也提供了甘特图的查看方式和依赖拓扑图、上下游耗时图等数据。
可观测升级

可观测在国内微服务领域已遍地开花。因此,F6 公司也升级了可观测思路。业界广泛推行的可观测性包含三大支柱,分别是日志事件、分布式链路追踪以及指标监控。任何时代都需要监控,但是它已经不再是核心需求。上图可以看出,监控仅包含告警和应用概览,而事实上可观测性还需包括排错剖析以及依赖分析。
最早的监控功能使用主体是运维人员,但运维人员大多只能处理系统服务告警。而上升到整个微服务领域,更多问题可能出现在应用之间,需要进行问题排障。比如服务出现了慢请求,有可能是因为代码问题,也可能因为锁或线程池不足,或连接数不够等,以上种种问题最终表现出来的特征是慢和服务无法响应。而如此多的可能性,需要通过可观测性才能定位到真正根因。然而,定位根因并非真实需求,真实需求更多的是利用可观测性分析出问题所处节点,然后通过替换对应组件、进行熔断或限流等措施,尽可能提升整体 SLA 。
可观测性还可以很好的剖析问题,比如线上服务慢,可以观测其每个节点的耗时、每个请求中的耗时等。依赖分析也可以得到解决,比如服务依赖是否合理、服务依赖调用链路是否正常等。
随着应用越来越多,对于可观测性和稳定性的诉求也越来越多。因此,我们自研了一套简单的根因分析系统,通过文本相似度算法将当前服务日志进行归类聚类分析。

上图为典型 ONS 故障,依赖服务进行服务升级。如果这是通过日志抓取智能分析出来的日志,做了很长时间 SRE 后,变更也会对于线上稳定性造成很大破坏。如果能将变更等也收集到可观测体系中,将会带来很大好处。同理,如果能将 ONS 要升级的信息收集到可观测体系统中,通过种种事件关联,能够分析出根因,对于系统稳定性和问题排查将极为有益。
- **ARMS 支持 traceId 透出 responseHeader

F6 公司和 ARMS 团队也进行了深入合作,探索了可观测的最佳实践。ARMS 近期退出了一项新功能,将 traceID 直接透出到 HTTP 头,可以在接入层日志中将它输出到对应日志,通过 Kibana 进行检索。
客户在发生故障时,将日志信息和 traceID 一起上报给技术支持人员,最后研发人员可通过 traceID 快速定位到问题原因、上下游链路,因为 traceID 在整个调用链路中是唯一的,非常适合作为检索条件。
同时,ARMS 支持直接通过 MDC 透传 traceID ,支持 Java 主流日志框架,包括 Logback、Log4j、Log4j2 等,也可以将 traceID 作为标准 Python 输出。
上图展示了典型的日志输出场景下 ARMS 的后台配置,可以打开关联业务日志和 traceID ,支持各种各样的组件,只需在日志系统中定义 eagleeye_traceid 即可输出 traceID。
上述方案较为简单,研发的修改也很少,甚至可以做到免修改,且对于 Loggin 和 Trace 的关联程度做到了较大提升,减少了数据孤岛。

ARMS 为进一步降低 MTTR ,提供了很多数据,但是数据如何到达 SRE 、DevOps 或研发运维人员手里,依然需要花费一些心思。
因此,ARMS 上线了运维告警平台,通过可视化方式完成了告警转发、分流等事件处理,可以通过静默功能、分组等,支持多种集成方式。目前 F6 在用的包括 Prometheus、buffalo、ARMS 以及云监控,其中云监控包含了包括 ONS、Redis 在内的很多数据,研发人员或 SRE 人员在钉钉群里认领对应的响应事件即可。同时还支持报表、定时提醒、事件升级等功能,便于事后复盘和改善。

上图为线上处理问题的界面截图。比如钉钉群里的告警会提示上一次相似告警由谁处理、告警列表以及对应事件处理流程等。同时,还提供了过滤功能,可以分割内容,通过字段丰富或匹配更新等方式替换内容填充模板,用于精准告警,比如识别到应用名称后,可以关联到对应应用的 owner 或告警人员。此功能后续也将逐步替代前文用 Go 语言写的 Apollo SDK 应用。
- Java 生态免修改注入 agent 方式-JAVA_TOOL_OPTIONS

同时,我们也借鉴了 ARMS 免修改注入 Agent 的方式。ARMS 通过one point initContainer 的方式注入了很多 ARMS 信息,也挂载了一个名为 home/admin/.opt 的 mount 用于存储日志。正因为有 initContainer ,它才能够实现自动升级。
在 initContainer 中,可以通过调用 ARMS 接口获取到当前 ARMS Agent 最新版本,然后下载 Java Agent 最新版本,放到 mount 目录下,与目录下对应的数组 Pod 进行通信,通过共享 volume 的方式完成 Java Agent 共享。过程中最核心的点在于,通过 JAVA_TOOL_OPTIONS 实现了 Java Agent 挂载。
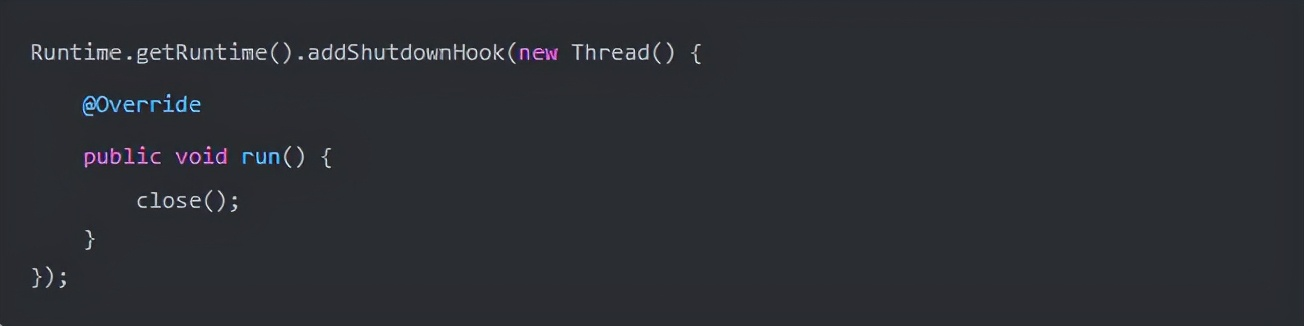
通过上述方式,我们模拟了一套流程,通过openkruise 组件 workspread 使用 patch 方式修改 deployment。最简单的实践是利用 openkruise workspread给对应的 deployment 打注解,从而使得无需由研发或 SRE 团队进行处理,只要编写对应 CRD 即可,CRD 过程直接注入 JAVA_TOOL_OPTIONS(见上图右下角代码)。其应用场景也较为丰富,可以做应用流量回放、自动化测试等。

除了 ARMS 等商业化产品外,我们也积极开源,拥抱 Prometheus 社区,接入了较多 Exporter 组件,包括 SSLExport 和 BlackBoxExporter,极大提升了整个系统的可观测性。Exporter 可以用于黑盒探针,比如探测 HTTP 请求是否正常、HTTPS 请求是否正、DNS 是否正常、TCP 是否正常等,典型的使用场景是探测当前服务入口地址是否正常。SSL 证书异常更为常见,通过 SSLExporter 可以定期轮询证书是否过期,进一步提升可观测性。

除了日常服务可观测,我们还实践了成本可观测等优化项目。对于云原生环境,可以利用 kubecost 开源组件进行成本优化,直接输出资源使用率以及报表等,反馈给研发人员进行优化,甚至可以用来发现 CPU 和内存是否呈正常比例,尽可能实现资源合理分配。
未来畅想
基于 eBPF 的 Kuberneters 一站式可观测性

eBPF 云原生组件愈发进入到深水区,很多问题不再只停留于应用层面,更多地会出现在系统层面和网络层面,需要更加底层的数据进行追踪和排障。利用 eBPF 可以更好地回答 Google SRE 提出的比如延迟、流量、错误率、饱和度等黄金指标出现的问题。
比如 Redis 进行闪断切换的过程中,可能会形成 TCP 半开连接,从而对业务产生影响;再比如 TCP 连接刚建立时,backlog 是否合理等,都可以通过数据得到相应结论。
Chaos-engineering

Chaos-engineering 混沌工程鼓励和利用可观测性,试图帮助用户先发制人地发现和克服系统弱点。2020 年 6 月,CNCF 针对可观测性提出了特别兴趣小组。除了三大支柱外,CNCF 还提出了混沌工程和持续优化。
对于混沌工程是否能划分在可观测性里,当前社区依然存在疑议,而 CNCF 的可观测性特别兴趣小组里已包含了 chaos-engineering 和持续优化。我们认为,CNCF 的做法有一定道理,混沌工程可以被认为是一种可观测性的分析工具,但其重要前提是可观测性。试想,如果在实施混沌工程过程中发生故障,我们甚至都无法确定它是否由混沌工程引起,这也将带来极大麻烦。
因此,可以利用可观测性尽可能缩小爆炸半径、定位问题,通过 chaos-engineering 持续优化系统,提前发现系统薄弱点,更好地为系统稳定性保驾护航。
OpenTelemetry

OpenTelemetry 是一个通过多个项目合并而来的开源框架。我们需要更加面向终端研发统一的可观测性视图,比如期望将 logging、metrics 和 tracing 数据进行互相关联打标,尽可能减少数据孤岛,通过多数据源的关联提升整体可观测性。并利用可观测性尽可能缩短线上故障排查时间,为业务服务恢复争取时间。

了解更多可观测产品详情,点击此处!







 京公网安备 11010802041100号
京公网安备 11010802041100号