消息中间件的工作过程可以用生产者消费者模型来表示.即,生产者不断的向消息队列发送信息,而消费者从消息队列中消费信息.具体过程如下:从上图可看出,对于消息队列来说,生产者,消息队列
消息中间件的工作过程可以用生产者消费者模型来表示.即,生产者不断的向消息队列发送信息,而消费者从消息队列中消费信息.具体过程如下:
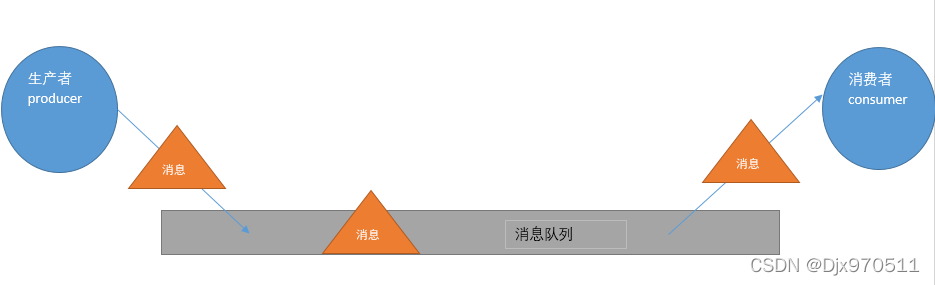
从上图可看出,对于消息队列来说,生产者,消息队列,消费者是最重要的三个概念,生产者发消息到消息队列中去,消费者监听指定的消息队列,并且当消息队列收到消息之后,接收消息队列传来的消息,并且给予相应的处理.消息队列常用于分布式系统之间互相信息的传递。
Rabbit模式大概分为以下三种:单一模式、普通模式、镜像模式
单一模式:最简单的情况,非集群模式,即单实例服务。
普通模式:默认的集群模式。
queue创建之后,如果没有其它policy,则queue就会按照普通模式集群。对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看,./rabbitmqctl list_queues 发现该队列已经丢失,但声明的exchange还存在。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。
所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。
该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。
如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,队列数据就丢失了。
镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案。
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。
该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。
所以在对可靠性要求较高的场合中适用,一个队列想做成镜像队列,需要先设置policy,然后客户端创建队列的时候,rabbitmq集群根据“队列名称”自动设置是普通集群模式或镜像队列。具体如下:
队列通过策略来使能镜像。策略能在任何时刻改变,rabbitmq队列也近可能的将队列随着策略变化而变化;非镜像队列和镜像队列之间是有区别的,前者缺乏额外的镜像基础设施,没有任何slave,因此会运行得更快。
为了使队列称为镜像队列,你将会创建一个策略来匹配队列,设置策略有两个键“ha-mode和 ha-params(可选)”。
了解集群中的基本概念:
RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。不过,如前文所述,如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
一个rabbitmq集群中可以共享user,vhost,queue,exchange等,所有的数据和状态都是必须在所有节点上复制的,一个例外是,那些当前只属于创建它的节点的消息队列,尽管它们可见且可被所有节点读取。rabbitmq节点可以动态的加入到集群中,一个节点它可以加入到集群中,也可以从集群环集群会进行一个基本的负载均衡。
集群中有两种节点:
1 内存节点:只保存状态到内存(一个例外的情况是:持久的queue的持久内容将被保存到disk)
2 磁盘节点:保存状态到内存和磁盘。
内存节点虽然不写入磁盘,但是它执行比磁盘节点要好。集群中,只需要一个磁盘节点来保存状态就足够了如果集群中只有内存节点,那么不能停止它们,否则所有的状态,消息等都会丢失。
RabitMQ的工作流程
对于RabbitMQ来说,除了这三个基本模块以外,还添加了一个模块,即交换机(Exchange).它使得生产者和消息队列之间产生了隔离,生产者将消息发送给交换机,而交换机则根据调度策略把相应的消息转发给对应的消息队列.那么RabitMQ的工作流程如下所示:
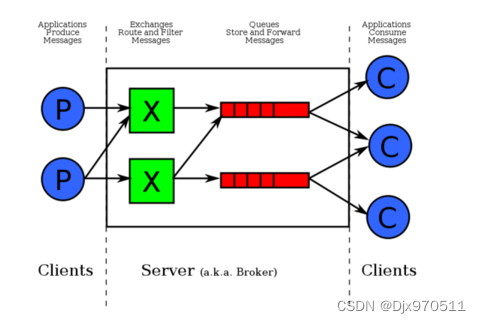
交换机的主要作用是接收相应的消息并且绑定到指定的队列.交换机有四种类型,分别为Direct,topic,headers,Fanout.
1).Direct Exchange
是RabbitMQ默认的交换机模式,也是最简单的模式.即创建消息队列的时候,指定一个BindingKey.当发送者发送消息的时候,指定对应的Key.当Key和消息队列的BindingKey一致的时候,消息将会被发送到该消息队列中.
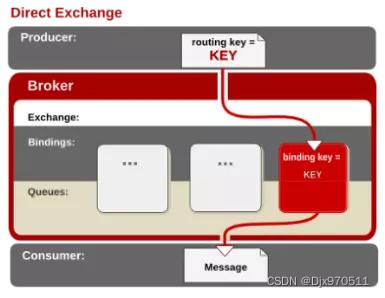
把消息路由到BindingKey和RoutingKey完全匹配的队列中
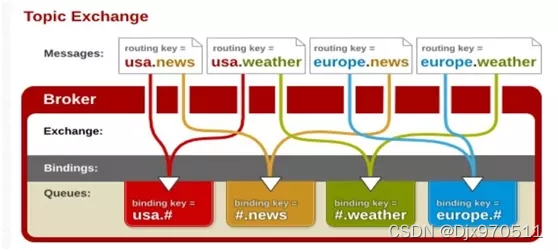
2).topic Exchange
转发信息主要是依据通配符,队列和交换机的绑定主要是依据一种模式(通配符+字符串),而当发送消息的时候,只有指定的Key和该模式相匹配的时候,消息才会被发送到该消息队列中.
3).headers也是根据一个规则进行匹配,在消息队列和交换机绑定的时候会指定一组键值对规则,而发送消息的时候也会指定一组键值对规则,当两组键值对规则相匹配的时候,消息会被发送到匹配的消息队列中.
4).Fanout Exchange 广播的形式
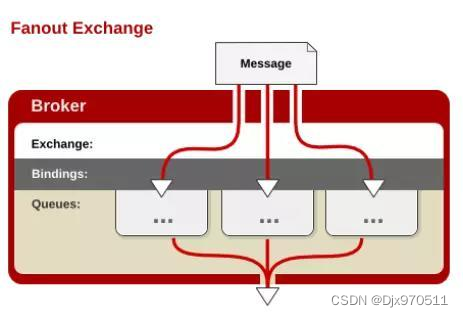
发送到该交换机的消息都会路由到与该交换机绑定的所有队列上,可以用来做广播
不处理路由键,只需要简单的将队列绑定到交换机上
Fanout交换机转发消息是最快的
整理汇总:
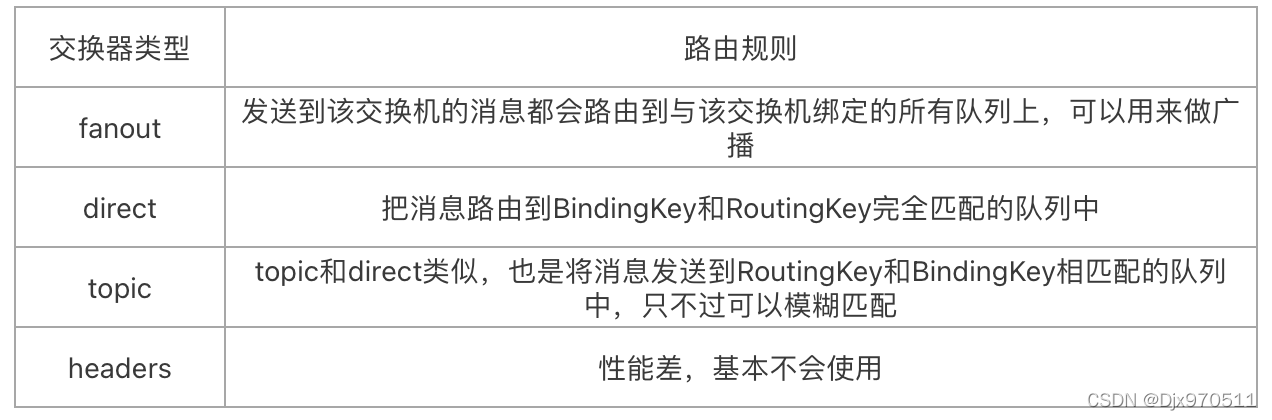
交换器类型 路由规则
fanout 发送到该交换机的消息都会路由到与该交换机绑定的所有队列上,可以用来做广播
direct 把消息路由到BindingKey和RoutingKey完全匹配的队列中
topic topic和direct类似,也是将消息发送到RoutingKey和BindingKey相匹配的队列中,只不过可以模糊匹配
headers 性能差,基本不会使用
消息的获得方式有2种
拉取消息(get message)
推送消息(consume message)
那我们应该拉取消息还是推送消息?get是一个轮询模型,而consumer是一个推送模型。get模型会导致每条消息都会产生与RabbitMQ同步通信的开销,这一个请求由发送请求帧的客户端应用程序和发送应答的RabbitMQ组成。所以选择呢推送消息,避免拉取
RabbitMq-API
消息的确认方式有2种
自动确认(autoAck=true)
手动确认(autoAck=false)
消费者在消费消息的时候,可以指定autoAck参数
String basicConsume(String queue, boolean autoAck, Consumer callback)
autoAck=false: RabbitMQ会等待消费者显示回复确认消息后才从内存(或者磁盘)中移出消息
autoAck=true: RabbitMQ会自动把发送出去的消息置为确认,然后从内存(或者磁盘)中删除,而不管消费者是否真正的消费了这些消息
手动确认的方法如下,有2个参数
basicAck(long deliveryTag, boolean multiple)
deliveryTag: 用来标识信道中投递的消息。RabbitMQ 推送消息给Consumer时,会附带一个deliveryTag,以便Consumer可以在消息确认时告诉RabbitMQ到底是哪条消息被确认了。 RabbitMQ保证在每个信道中,每条消息的deliveryTag从1开始递增
multiple=true: 消息id<=deliveryTag的消息,都会被确认
myltiple=false: 消息id=deliveryTag的消息,都会被确认
消息一直不确认会发生啥?
如果队列中的消息发送到消费者后,消费者不对消息进行确认,那么消息会一直留在队列中,直到确认才会删除。 如果发送到A消费者的消息一直不确认,只有等到A消费者与rabbitmq的连接中断,rabbitmq才会考虑将A消费者未确认的消息重新投递给另一个消费者
拒绝消息的两种方式
basicNack(long deliveryTag, boolean multiple, boolean requeue)
basicReject(long deliveryTag, boolean requeue)
basicNack和basicReject的区别只有一个,basicNack支持批量拒绝
deliveryTag和multiple参数前面已经说过。
requeue=true: 消息会被再次发送到队列中
requeue=false: 消息会被直接丢失
失败通知
主要简述了消息发布时的权衡

我们最常用的就是失败通知和发布者确认
当消息不能被路由到某个queue时,我们如何获取到不能正确路由的消息呢?
在发送消息时设置mandatory为true
生产者可以通过调用channel.addReturnListener来添加ReturnListener监听器获取没有被路由到队列中的消息
mandatory是channel.basicPublish()方法中的参数
mandatory=true: 交换器无法根据路由键找到一个符合条件的队列,那么RabbitMQ会调用Basic.Return命令将消息返回给生产者
发布者确认
当消息被发送后,消息到底有没有到达exchange呢?默认情况下生产者是不知道消息有没有到达exchange
RabbitMQ针对这个问题,提供了两种解决方式
事务(后面会讲到)
发布者确认(publisher confirm)
而发布者确认有三种编程方式
普通confirm模式:每发送一条消息后,调用waitForConfirms()方法,等待服务器端confirm。实际上是一种串行confirm了。
批量confirm模式:每发送一批消息后,调用waitForConfirms()方法,等待服务器端confirm。
异步confirm模式:提供一个回调方法,服务端confirm了一条或者多条消息后Client端会回调这个方法。
异步confirm模式的性能最高,因此经常使用,我想把这个分享的细一下
channel.addConfirmListener(new ConfirmListener() {
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
log.info(“handleAck, deliveryTag: {}, multiple: {}”, deliveryTag, multiple);
}
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {log.info("handleNack, deliveryTag: {}, multiple: {}", deliveryTag, multiple);
}
});
写过异步confirm代码的小伙伴应该对这段代码不陌生,可以看到这里也有deliveryTag和multiple。但是我要说的是这里的deliveryTag和multiple和消息的ack没有一点关系。
confirmListener中的ack: rabbitmq控制的,用来确认消息是否到达exchange
消息的ack: 上面说到可以自动确认,也可以手动确认,用来确认queue中的消息是否被consumer消费
备用交换器
生产者在发送消息的时候如果不设置 mandatory 参数那么消息在未被路由到queue的情况下将会丢失,如果设置了 mandatory 参数,那么需要添加 ReturnListener 的编程逻辑,生产者的代码将变得复杂。如果既不想复杂化生产者的编程逻辑,又不想消息丢失,那么可以使用备用交换器,这样可以将未被路由到queue的消息存储在RabbitMQ 中,在需要的时候去处理这些消息
事务
RabbitMQ中与事务机制相关的方法有3个
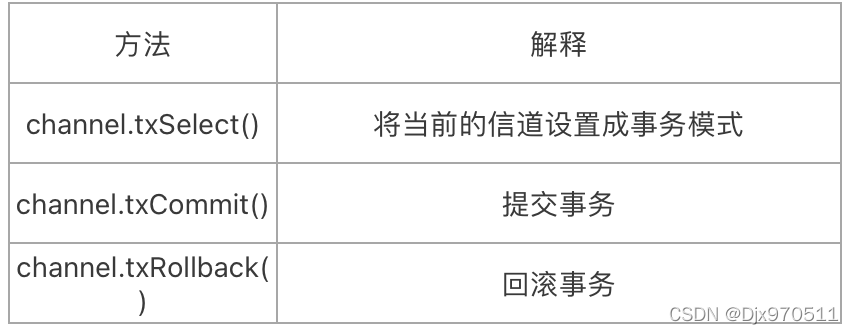
方法 解释
channel.txSelect() 将当前的信道设置成事务模式
channel.txCommit() 提交事务
channel.txRollback() 回滚事务
消息成功被发送到RabbitMQ的exchange上,事务才能提交成功,否则便可在捕获异常之后进行事务回滚,与此同时可以进行消息重发 因为事务会榨干RabbitMQ的性能,所以一般使用发布者确认代替事务
消息持久化
消息做持久化,只需要将消息属性的delivery-mode设置为2即可
RabbitMQ给我们封装了这个属性,即MessageProperties.PERSISTENT_TEXT_PLAIN, 详细使用可以参考github的代码
当我们想做消息的持久化时,最好同时设置队列和消息的持久化,因为只设置队列的持久化,重启之后消息会丢失。只设置队列的持久化,重启后队列消失,继而消息也丢失
死信队列
DLX,全称为Dead-Letter-Exchange,称之为死信交换器。当一个消息在队列中变成死信(dead message)之后,它能被重新发送到另一个交换器中,这个交换器就是DLX,绑定DLX的队列就称之为死信队列。 DLX也是一个正常的交换器,和一般的交换器没有区别,实际上就是设置某个队列的属性
消息变成死信一般是由于以下几种情况
消息被拒绝(Basic.Reject/Basic.Nack)且不重新投递(requeue=false)
消息过期
队列达到最大长度
死信交换器和备用交换器的区别
备用交换器: 1.消息无法路由时转到备用交换器 2.备用交换器是在声明主交换器的时候定义的
死信交换器: 1.消息已经到达队列,但是被消费者拒绝等的消息会转到死信交换器。2.死信交换器是在声明队列的时候定义的
流量控制(服务质量保证)
qos即服务端限流,qos对于拉模式的消费方式无效
使用qos只要进行如下2个步骤即可
autoAck设置为false(autoAck=true的时候不生效)
调用basicConsume方法前先调用basicQos方法,这个方法有3个参数
basicQos(int prefetchSize, int prefetchCount, boolean global)
参数名 含义
prefetchSize 批量取的消息的总大小,0为不限制
prefetchCount 消费完prefetchCount条(prefetchCount条消息被ack)才再次推送
global global为true表示对channel进行限制,否则对每个消费者进行限制,因为一个channel允许有多个消费者
为什么要使用qos?
提高服务稳定性。假设消费端有一段时间不可用,导致队列中有上万条未处理的消息,如果开启客户端, 巨量的消息推送过来,可能会导致消费端变卡,也有可能直接不可用,所以服务端限流很重要
提高吞吐量。当队列有多个消费者时,队列收到的消息以轮询的方式发送给消费者。但由于机器性能等的原因,每个消费者的消费能力不一样, 这就会导致一些消费者处理完了消费的消息,而另一些则还堆积了一些消息,会造成整体应用吞吐量的下降。



 京公网安备 11010802041100号
京公网安备 11010802041100号