Netty的零拷贝技术是自己一直以来不太理解的地方,最近花了一点时间,简单梳理了Netty中Zero Copy的相关知识点,主要从以下两个方面来进行总结。
从这两方面基本上能简单理解操作系统与Netty中零拷贝技术的共性之处以及Netty中针对JVM内存模型的一些拓展手段。
Zero Copy
什么是零拷贝技术 ?
"Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.[1]
零拷贝技术主要是指减少IO时数据在用户态和内核态之间相互转换以及上下文切换的消耗,提升CPU吞吐量,减少内存资源的消耗。在现代操作系统中,一般都会有零拷贝技术的支持。
零拷贝的出现是因为现代操作系统的特性,用户态与内核态。关于用户态与内核态的具体细节这里不多赘述,仅简单分析下和Zero Copy相关的部分内容。
非Zero Copy状态切换分析
掌握这部分内容就能很好的理解什么是零拷贝技术,现在我们来假设一个场景。
现有应用程序 A 运行在操作系统 B 上,A 希望将本地磁盘内的一个文件发送给网络上的另一台机器。
在应用程序中,一般都会有缓冲区,读取一个文件时都会将文件先刷新到缓冲区中,这部分内容可以参考计算机I/O方面的操作。按照正常情况,实现上述的场景需要进行三次buffer刷新。
应用程序 A 通知操作系统 B 读取文件,并将文件刷新到Read Buffer
应用程序 A 将 Read Buffer 中的内容刷新到自己的 Read Buffer
应用程序 A 将自身缓冲区刷新到操作系统中网络I/O的 Write Buffer
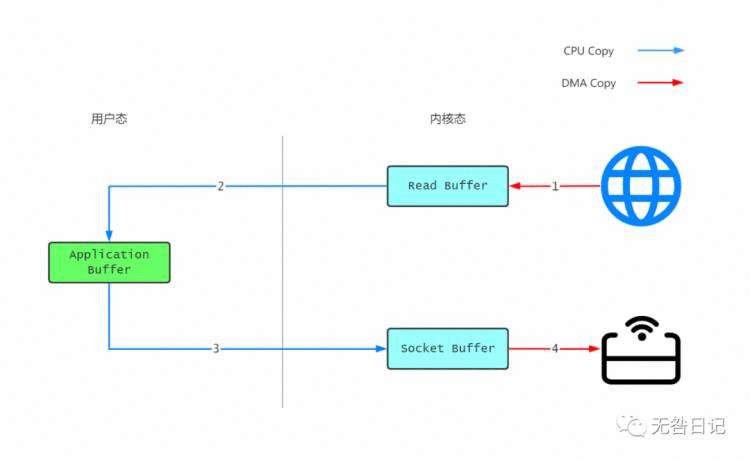
该图是关于缓冲区运行流程,同时我也将上下文切换流程以图展示。

上述两图是在没有Zero Copy时执行该场景进行的操作,但是我们能够明显发现一个缺点。
用户缓冲区和线程都没必要进行多一次的操作,如果能够直接将内核态中的 Read Buffer 直接冲刷进内核态中的 Write Buffer ,这样能减少一次缓冲区的复制,同时也能减少两次上下文的切换。
Zero Copy状态切换分析
在Java中,Zero Copy通常使用 FileChannel.transferTo
方法来实现。
public abstract long transferTo(long position, long count,
WritableByteChannel target)
throws IOException;
transferTo()
方法将数据从文件通道传输到了给定的可写字节通道。在内部,它依赖底层操作系统对零拷贝的支持;在 UNIX 和各种 Linux 系统中,此调用被传递到 sendfile()
系统调用中。

上下文切换流程 :

可以看到,相比较上面的传统方式,这种方式已经减少了性能消耗。拷贝次数从4变为3,上下文切换次数从4变为2。但是还尚未到达完美的地步。当我们的Socket Buffer收到数据后,还需要将数据发送到网卡进行传输,如果网卡支持收集操作,我们是否能直接将数据复制到网卡中进行传输。
在上面这种情况中,Read Buffer拷贝到Socket Buffer实际上还是需要进行一次拷贝操作,这个过程同样需要CPU的资源。而如果将数据直接发送到网卡,就能够再减少一次拷贝操作,真正实现了Zero Copy。
在 Linux 内核 2.4 及后期版本中,套接字缓冲区描述符就做了相应调整,以满足该需求。这种方法不仅可以减少多个上下文切换,还可以消除需要涉及 CPU 的重复的数据拷贝。对于用户方面,用法还是一样的,但是内部操作已经发生了改变:
transferTo() 方法引发 DMA 引擎将文件内容拷贝到内核缓冲区。
数据未被拷贝到套接字缓冲区。取而代之的是,只有包含关于数据的位置和长度的信息的描述符被追加到了套接字缓冲区。DMA 引擎直接把数据从内核缓冲区传输到协议引擎,从而消除了剩下的最后一次 CPU 拷贝。

Netty Zero Copy
Netty的零拷贝技术一直是它高性能的保证,同时也是Netty面试中不得不了的一点,但是需要说明一点,Netty的零拷贝并非特指一项技术,而是多个细节方面的实现,和操作系统中的Zero Copy有着本质的区别。
Netty中的零拷贝主要体现在以下几个方面 :
ByteBuf
的 slice
操作并不会拷贝一份新的 ByteBuf
内存空间,而是直接借用原来的 ByteBuf
,只是独立地保存读写索引。
Netty 提供了 CompositeByteBuf
类,可以将多个 ByteBuf
组合成一个逻辑上的 ByteBuf
。
Netty 的 FileRegion
中包装了 NIO
的 FileChannel.transferTo()
方法,该方法在底层系统支持的情况下会调用 sendfile
方法,从而在传输文件时避免了用户态的内存拷贝。
Netty 的 PooledDirectByteBuf
等类中封装了 NIO
的 DirectByteBuffer
,而 DirectByteBuffer
是直接在 jvm 堆外分配的内存,省去了堆外内存向堆内存拷贝的开销。
slice操作
Netty中的 slice()
方法能够将一个buffer分割为几个小的buffer。但是这种分割并不是真实的物理上的分割,而是一种逻辑分割。
通过slice方法能将一个buffer分割为多个bytebuf对象,这些对象共享统一内存区域。
public ByteBuf slice();
public ByteBuf slice(int index, int length);
提供了两种slice方法,第一种分割只读部分,第二个方法按照index和length分割。
CompositeByteBuf
在有些场景里,我们的数据会分散在多个 ByteBuf
上,但是我们又希望将这些 ByteBuf
聚合在一个 ByteBuf
里处理。这里最直观的想法是将所有 ByteBuf
的数据拷贝到一个 ByteBuf
上,但是这样会有大量的内存拷贝操作,产生很大的CPU开销。
而 CompositeByteBuf
可以很好地解决这个问题,正如名字一样,这是一个复合 ByteBuf
,内部由很多的 ByteBuf
组成,但 CompositeByteBuf
给它们做了一层封装,可以直接以 ByteBuf
的接口操作它们。
我们来看下Netty中的源代码。
private int addComponent0(boolean increaseWriterIndex, int cIndex, ByteBuf buffer) {
assert buffer != null;
boolean wasAdded = false;
try {
// 检查新增的component的索引是否合法
checkComponentIndex(cIndex);
// buffer的长度
int readableBytes = buffer.readableBytes();
// No need to consolidate - just add a component to the list.
@SuppressWarnings("deprecation")
// 统一为大端ByteBuf
Component c = new Component(buffer.order(ByteOrder.BIG_ENDIAN).slice());
if (cIndex == components.size()) {
// 如果索引等于components的大小,则加在components尾部
wasAdded = components.add(c);
if (cIndex == 0) {
// 如果components中只有一个元素
c.endOffset = readableBytes;
} else {
// 如果components中有多个元素
Component prev = components.get(cIndex - 1);
c.offset = prev.endOffset;
c.endOffset = c.offset + readableBytes;
}
} else {
// 如果新的ByteBuf是插在components中间
components.add(cIndex, c);
wasAdded = true;
if (readableBytes != 0) {
// 如果components的大小不为0,则依次更新cIndex之后的
// 所有components的offset和endOffset
updateComponentOffsets(cIndex);
}
}
if (increaseWriterIndex) {
// 如果要更新writerIndex
writerIndex(writerIndex() + buffer.readableBytes());
}
return cIndex;
} finally {
if (!wasAdded) {
// 如果没添加成功,则释放ByteBuf
buffer.release();
}
}
}
这是添加一个新的 ByteBuf
的逻辑,核心是 offset
和 endOffset
,分别指代一个 ByteBuf
在 CompositeByteBuf
中开始和结束的索引,它们唯一标记了这个 ByteBuf
在 CompositeByteBuf
中的位置。
弄清楚了这个,我们会发现上面的代码无外乎做了两件事:
把 ByteBuf
封装成 Component
加到 components
合适的位置上
使 components
里的每个 Component
的 offset
和 endOffset
值都正确
FileRegion
A region of a file that is sent via a Channel which supports zero-copy file transfer.
这是FileRegion的内部注释, FileRegion
内部封装了 Java NIO 的 FileChannel.transferTo()
方法。而transferTo的具体实现我们在上文中已经讲过,这里不多赘述。
当操作系统支持Zero Copy时,Netty会调用java底层的transferTo方法来完成零拷贝。
DirectByteBuffer
如果熟悉Java NIO的读者对于 DirectByteBuffer
应该有所了解,Netty使用 DirectByteBuffer
作为 PooledDirectByteBuf
和 UnpooledDirectByteBuf
的内部数据容器,该缓存能够操作堆外内存。
首先来看下 DirectByteBuffer
的实现结构。
Java本质上是一个运行在JVM上的应用程序,所以Java语言本身并没有直接操作内存的能力,而分配堆外内存的任务就交由 Unsafe
类完成,查看 DirectByteBuffer
源码能够发现,出现了大量的Unsafe类的操作,我们需要注意的重点在 DirectByteBuffer(intcap)
构造方法中,重点放在该行代码。
base = unsafe.allocateMemory(size);
allocateMemory
是一个native方法,底层调用的是C语言中的 malloc
来进行内存的分配。使用该方法分配的内存,并不在堆中而是在系统本地内存中,所以不受JVM的管理。
由于不受JVM管理,所以这部分内存的回收,读取写入等操作需要由 DirectByteBuffer
自己来完成,这些工作都需要依赖一个变量。
// Used only by direct buffers
// NOTE: hoisted here for speed in JNI GetDirectBufferAddress
long address;
address
表示分配的堆外内存的地址,JNI对这个堆外内存的操作都是通过这个 address
实现的。
简单说了 DirectByteBuffer
是如何分配堆外内存的问题后,还需要理解一些概念,在阅读有关Buffer相关的代码时,都会在注释中提到JNI,这里简单介绍下JNI。
In software design, the Java Native Interface (JNI) is a foreign function interface programming framework that enables Java code running in a Java virtual machine (JVM) to call and be called by[1] native applications (programs specific to a hardware and operating system platform) and libraries written in other languages such as C, C++ and assembly.
Java Native Interface简称JNI,即调用本地方法的一个接口。由于需要调用很多操作系统的方法,所以Java会调用C/C++编写的一些DLL,而调用的接口即称为JNI。
同时,还有一个概念需要了解。
操作系统无法直接访问JVM堆的内存区域
由于JVM本身具有一套自己的堆内存管理策略,即对象自动回收和内存分配,如果操作系统通过JNI操作JVM堆内存时,JVM进行了GC操作,由于GC过程中会进行复制,标记整理等算法,此时堆中对象的内存地址已然发生变化,但是对于操作系统来说,这是不可知的,操作系统只会认为JNI的内存调用出现了数据错乱。
为了避免这种情况,一般而言,操作系统会将数据从操作系统本地内存Copy一份到堆内存,Java程序处理完成后,会将堆缓冲区内的数据刷新到操作系统的缓冲区中。
例如我们执行一次文件传输操作,首先会通过一次IO将堆外内存拷贝到堆内内存中,然后再刷新到堆外内存,最后又NIC进行网络传输,整个过程和之前讲的操作系统中传统的流程相仿,都会多做一次Copy。
而Netty通过封装 DirectByteBuffer
作为容器,由Netty框架对该内存区域进行自主管理,这样就能够避免将数据Copy到内存中,直接通过JNI将堆外内存的地址传输给IO的函数即可,直接让操作系统对堆外内存进行操作。
当然,堆外内存减少了数据复制的操作,但是同时也放弃了JVM的内存管理,此时我们对于这部分区域进行精准的分析与管理,否则容易出现缓冲区OOM的情况。同时,创建和销毁一块堆外内存的花销要比堆内存昂贵得多,这是因为堆外内存的创建和销毁要通过系统相关的 native 方法,而不是在 Java 堆上直接由 JVM 操控。








 京公网安备 11010802041100号
京公网安备 11010802041100号