Cloneable这个接口设计得十分奇葩,不符合正常人的使用习惯,然而用这个接口的人很多也很有必要,所以还是有必要了解一下这套扭曲的机制。以下内容来自于对Effective Java ed 2. item 11的整理。
Cloneable接口
首先,Cloneable接口中并没有方法。它的存在意义一是让程序员注明当前对象可以clone,二是改变父类Object类中clone方法的行为:如果某个类实现了Cloneable,那么它的父类Object的clone方法可以调用,否则会抛出CloneNotSupportedException。(奇葩吧)
也就是说,如果我们要告诉用户,这个类是可以clone的,并且在我们的实现中需要调用super.clone,那么我们就必须实现Cloneable。
(然而,即使某个类实现了Cloneable,也不一定保证它就有clone方法,这是这个接口设计的奇葩之处之一,设计者可能是反社会吧)
我们的clone方法
需要重写clone方法的情况分为两类。
1:需要实现Cloneable接口。
2:只需要重写clone方法。
其中,第一种情况比较普遍。第二种可以看作为了讨论的完整性对第一种进行的补充。
需要实现Cloneable接口
考虑到clone方法是直接给用户用的,建议做到以下几点:
将限制符改为public;
将它的返回类型设置成子类类型(可以这么做是因为java允许covariant return type);
接住CloneNotSupportedException并不再抛出(既然已经实现了Cloneable接口,就不会抛出这个异常,不然用户又要在
那里try-catch半天)。
@Override
public PhoneNumber clone() throws ... {
try {
return (PhoneNumber) super.clone();
} catch(CloneNotSupportedException e) {
throw new AssertionError(); // Can't happen
}
}
注意,这里给出的是clone方法的大体写法,包括函数签名等,先让你有一个大略的方向。当我们按照以上三条搭好clone方法的框框后,具体如何去实现克隆的过程,下一节会举例详述。
注:如果当前类是final的,可以直接使用构造器来构造对象。(如果不是final的,那么可能还会有子类,子类再调用super.clone的时候就只能返回父类类型对象,就不太合适了,所以只有final类适合用构造器)
只需要重写clone方法
这个类可能是继承链上的一个中间类。此时该clone方法最好模拟Object.clone的行为,即:
限制符为protected;
不实现Cloneable;
抛出CloneNotSupportedException。
不同情景下的clone方法实现
首先,应熟悉Object.clone的行为(因为在我们自己的类中经常会调用super.clone,最终调用Object.clone):浅拷贝。即:先创建一个新对象,然后将它的所有域初始化为待拷贝对象的域的对应值。
另外,所有数组都会实现Cloneable接口,T[].clone的返回类型也为T[],行为与Object类似。(这是一个好用的feature,实现浅拷贝时会经常用到)
官方文档对clone的实现建议是:先调用super.clone创建对象;如果对象的域都是基本类型,则一切搞定;否则,如果对象是可变对象,则要将组成对象的"deep structure"的对象全部复制,然后将复制品的域引用指向这些复制后的对象。
上一节给出的PhoneNumber的clone属于前者(对象域为电话号码、区号等,为基本类型short),所以调用super.clone再加一个cast就可以搞定。
注意这个蓝色的deep structure,指明了clone方法实现的精髓。以下举两个例子,读者可细细品味。
案例一:Stack
public class Stack {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {...}
public void push(Object e) {...}
public Object pop() {...}
private void ensureCapacity() {...} //omitted for simplicity
}
如果在Stack的clone方法中,也简单地返回super.clone,会有一个严重的后果,就是在原对象中如果增删了元素,在复制对象中的size不变,但是实际上元素被增删了,违反了复制对象的invariant。
解决办法是将elements数组独立克隆:
@Override public Stack clone() {
try {
Stack result = (Stack) super.clone();
result.elements = elements.clone();
return result;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
两种方法的区别如下:(渣图……)
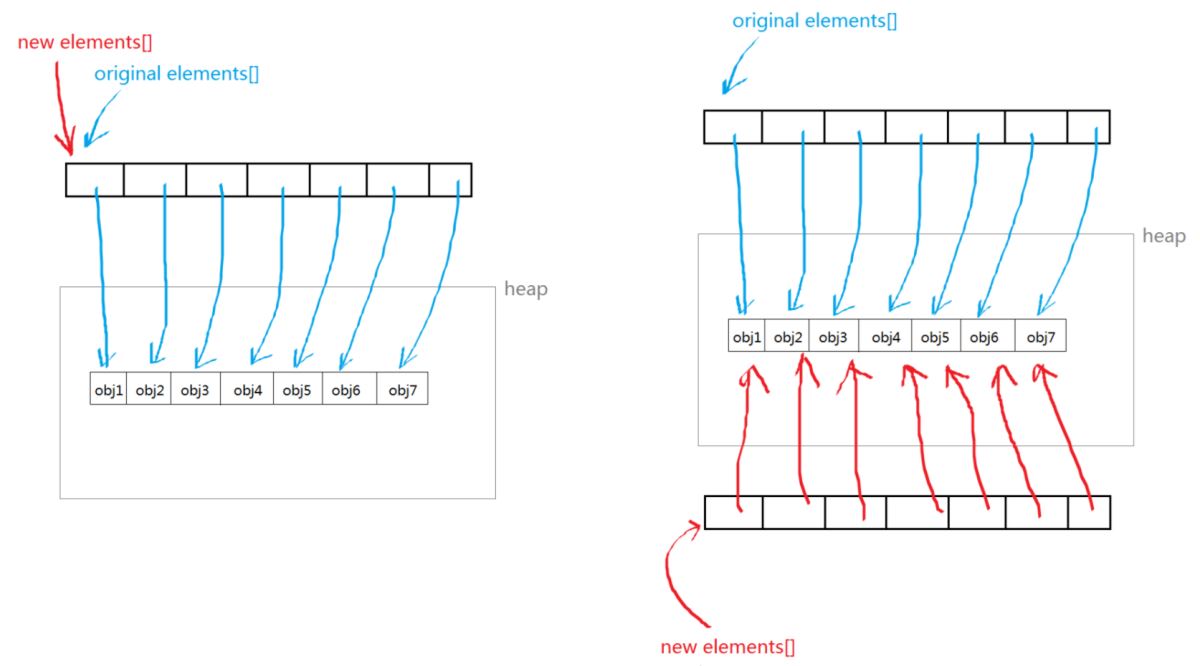
第一种方法对应左图,由于克隆后的对象的elements指向原对象中的数组,当原对象增删元素时,克隆后的对象的backing array也跟着自动变化。第二种方法对应右图,克隆后对象的数组和原对象的数组是互相独立的,当原对象增删元素时,克隆后的对象可以不受影响,因为它还保持原有的那些引用。虽然两种都是浅拷贝,但只有第二种符合不变性。而且第二种是容器类的一种常用做法,如ArrayList的copy constructor。
案例二:HashTable
在Stack的基础上再复杂一点,我们研究一个HashTable:
public class HashTable implements Cloneable {
private Entry[] buckets = ...;
private static class Entry {
final Object key;
Object value;
Entry next;
Entry(Object key, Object value, Entry next) {
this.key = key;
this.value = value;
this.next = next;
}
}
... // Remainder omitted
}
如果我们照搬Stack的克隆方法,是否会有效呢?
@Override public HashTable clone() {
try {
HashTable result = (HashTable) super.clone();
result.buckets = buckets.clone();
return result;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
克隆后的HashTable有自己的array了,看起来好像没什么问题了。然而,HashTable使用的是Entry对象头尾相接的链表。克隆后Entry元素们还指向同样的对象,此时如果原table增删了元素,其实质是它将某些Entry指向了新Entry或指向null;由于克隆后的table与克隆前的table共享一套Entry对象,所以它的内部结构发生了同样的改变,但它并不知道自己发生了改变,这样就出现了奇怪的现象,比如说克隆后的table的size明明没变,却凭空多出/消失了一些元素。
HashTable original = new HashTable();
original.put(x, y);
HashTable clOned= original.clone();
original.remove(x); //cloned gets removed by one element too, but does not know of it!!
if(cloned.size() > 0){
doSomething(); //Danger! It's actually empty!!
}
如图:
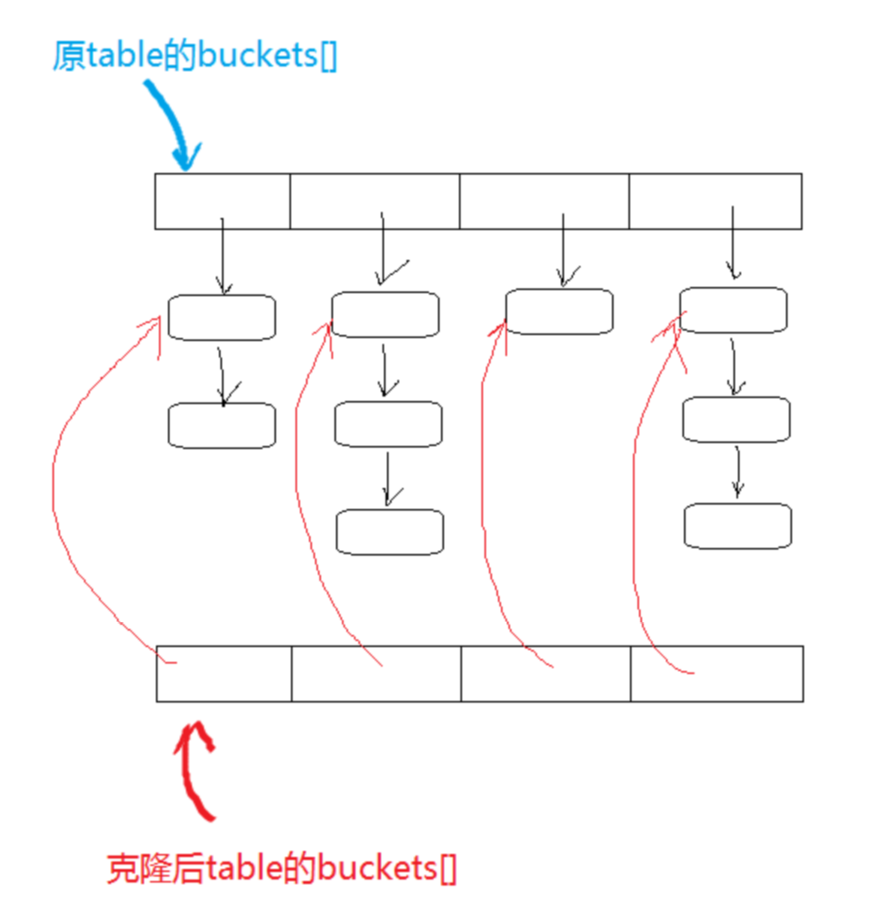
解决方法是将其中value的容器Entry做深拷贝。
public class HashTable implements Cloneable {
private Entry[] buckets = ...;
private static class Entry {
final Object key;
Object value;
Entry next;
Entry(Object key, Object value, Entry next) {
this.key = key;
this.value = value;
this.next = next;
// Recursively copy the linked list headed by this Entry
Entry deepCopy() {
return new Entry(key, value, next == null ? null : next.deepCopy());
}
}
@Override public HashTable clone() {
try {
HashTable result = (HashTable) super.clone();
result.buckets = new Entry[buckets.length];
for (int i = 0; i
注:value指向的Object仍然没变,所以这种方法只是在一定程度上做深拷贝。由于HashTable直接操作的是Entry,将Entry这一层深拷贝即可。
由于上述deepCopy()方法容易引起stack overflow,作者建议使用iteration代替recursion.
//Iteratively copy the linked list headed by this Entry
Entry deepCopy() {
Entry result = new Entry(key, value, next);
for (Entry p = result; p.next != null; p = p.next)
p.next = new Entry(p.next.key, p.next.value, p.next.next);
return result;
}
其他碎碎念
(非final类的)clone方法不应调用克隆后对象的nonfinal方法。若该类的子类重写了这个nonfinal方法,该方法有可能在子类创建完毕之前去调用它的一些方法/数据,可能会引起数据损坏。
如果类中有一个指向可变对象的final域,则以上的clone实现机制无法work,因为对象创建好以后无法再给final域assign一个值。
不可变类不应该支持clone,因为clone后的对象跟原对象没有区别。
其实一种比较好的方法是copy constructor或copy factory。它们没有Cloneable的那些奇葩性,不抛异常,而且可以搞定final域。
public Yum(Yum yum); //copy constructor public static Yum newInstance(Yum yum); //copy factory
一个更好的好处是,interface-based copy constructor或copy factory (称为conversion constructors / conversion factories)可以允许用户选择与原对象不同类的克隆对象。如
HashSet s = ...; new TreeSet(s); //将HashSet转换成TreeSet
总结
以上所述是小编给大家介绍的Java中clone的写法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有