目录
- 1. Pruning Filters for Efficient ConvNets
- 2. Learning Structured Sparsity in Deep Neural Networks
- 3. Learning Efficient Convolutional Networks through Network Slimming
- 4. Channel Pruning for Accelerating Very Deep Neural Networks
- 5. HRank:Filter Pruning using High-Rank Feature Map
- 6. Channel Pruning via Automatic Structure Search
- 7. DropNet: Reducing Neural Network Complexity via Iterative Pruning
- 8. DMCP: Differentiable Markov Channel Pruning for Neural Networks
- 9. Rethinking the Value of Network Pruning
1. Pruning Filters for Efficient ConvNets
| 题目 | Pruning Filters for Efficient ConvNets |
|---|
| 作者与单位 | ICLR2016 美国马里兰大学 Hao Li |
| 方法和要解决的问题 | 过滤器剪枝(基于feater map通道的剪枝)
基于幅度的权重修剪减少了来自完全连接层的大量参数,并且由于修剪网络中的不规则稀疏性,可能不能充分降低卷积层中的计算成本。 |
| idea | 1.对每层的滤波器进行取范数并对比大小,删除其排名靠后的滤波器。主要还考虑了对应特征映射上为0的位置,一并删去。
2.提出了敏感度的概念。即剪枝某层过滤器时对准确度影响小,就是敏感度小,可以参看:图a
3.也重点介绍了对于resnet网络的修剪,所要关注的点。 |
| 讨论 | 这种结构化的剪枝方式,不引入不规则的稀疏性。为了简化修剪,使用了一次性的修剪在训练的策略。 |
| 结果 | 1.VGG-16 34%加速
2.ResNet-110 38%加速
3.同时通过对网络进行再训练,可以恢复到接近原始精度的水平. |
| 备注 | 代码开源,已经阅读对vgg剪枝的代码 |
2. Learning Structured Sparsity in Deep Neural Networks
| 题目 | Learning Structured Sparsity in Deep Neural Networks |
|---|
| 作者与单位 | NIPS2016 匹兹堡大学 Wei Wen |
| 方法和要解决的问题 | 神经网络学习参数冗余,学习更加稀疏的权值。
1.训练更加紧凑的模型,节省计算开销。
2.硬件友好的结构化稀疏,易于加速。
3.提供了正则化,有更好的泛化能力,提升精度。 |
| idea | 1. 借鉴lasso group提出了一种正则化损失函数用于对卷积层,通道,过滤器趋于0。 |
| 讨论 | 仅仅是一种L1正则化方法,让更多的权值为0,在移除实现模型的压缩。 |
| 结果 | 这种方法可以在CPU/GPU上对AlexNet分别达到平均5.1和3,1倍的加速。在CIFAR10上训练ResNet,从20层减少到18层,并提高了精度 |
| 备注 | 代码开源,caffe代码
1.得到的结构化稀疏矩阵用于加速,但是训练的引入的损失函数项目比较多,这个方法需要额外计算新引入的和所有filters有关的梯度项,这是一个问题。
2. 仅仅实验了LeNet and AlexNet.
3. 损失函数变化,需要从头训练,耗费时间。
论文详细介绍  |
3. Learning Efficient Convolutional Networks through Network Slimming
| 题目 | Learning Efficient Convolutional Networks through Network Slimming |
|---|
| 作者与单位 | ICCV2017 清华大学 |
| 方法和要解决的问题 | 模型压缩要解决的问题
1.减小模型的大小
2.减小运行时内存的时间
3.不影响精度的同时,提高计算的操作数。
目前存在的问题是:上篇论文提出的SSL方法缺点看备注。 |
| idea | L=∑(x,y)l(f(x,W),y)+λ∑γ∈Γg(γ)L=\sum_{(x, y)} l(f(x, W), y)+\lambda \sum_{\gamma \in \Gamma} g(\gamma)L=(x,y)∑l(f(x,W),y)+λγ∈Γ∑g(γ)1.我们的方法是将L1正则化施加到BN层的缩放因子上,L1正则化推动BN层的缩放因子趋向于零,这使得我们能够鉴别出不重要的通道或者神经元,因为每一个缩放因子都和一个特定的CNN卷积通道(或者全连接层的一个神经元)相关联。
2.对跳跃连接也提出了方法 |
| 讨论 | 这是结构化稀疏或者剪枝不需要特别的库来实现加速 |
| 结果 | 该方法能够在不损失精度的情况下显著降低现有网络的计算代价(最高可达20倍)。更重要的是,该方法同时减少了模型规模、运行时内存和计算运算量,同时给训练过程带来了最小的开销,并且所得到的模型不需要专门的库/硬件来进行有效的推理。 |
| 备注 | 代码开源,pytorch代码
代码好写,但是仅仅训练过程变得简单(损失函数变得不多),但是在精度上没有特别大的进步
论文详细介绍  |
4. Channel Pruning for Accelerating Very Deep Neural Networks
| 题目 | Channel Pruning for Accelerating Very Deep Neural Networks |
|---|
| 作者与单位 | ICCV2017 旷视科技 |
| 方法和要解决的问题 | 模型存在冗余 |
| idea | argminβ,W12N∥Y−∑i=1cβiXiWi⊤∥F2subject to ∥β∥0≤c\begin{array}{l}\underset{\beta, W}{\arg \min } \frac{1}{2 N}\left\|Y-\sum_{i=1}^{c} \beta_{i} X_{i} W_{i}^{\top}\right\|_{F}^{2} \\\text {subject to }\|\beta\|_{0} \leq c\end{array}β,Wargmin2N1∥∥Y−∑i=1cβiXiWi⊤∥∥F2subject to ∥β∥0≤c1. 提出了一种基于最小化特征重建误差的算法用于通道的裁制。
2. 作者对这种方法提出了两步迭代的优化算法
3. 对应用于多分支结构和和跳跃连接的也提出了额方法。 |
| 讨论 | 该方法是逐层进行剪枝的,比较复杂,其中也有需要手工的感觉,而且训练阶段繁琐。 |
| 结果 | 修剪过的vgg16实现了5倍的加速和只有0.3%的误差增加比起最先进的结果。更重要的是,该方法能够加快ResNet、Xception等现代网络的速度,在2倍的速度提升下,精度损失分别只有1.4%和1.0%, |
| 备注 | 代码开源,咖啡框架组会讲解
训练比较繁琐,而且是两步迭代,而且训练时间很长,需要微调  |
5. HRank:Filter Pruning using High-Rank Feature Map
| 题目 | HRank:Filter Pruning using High-Rank Feature Map |
|---|
| 作者与单位 | CVPR2020 厦门大学 |
| 方法和要解决的问题 | 总结了以往的剪枝主要分为两类
1. 通过判断属性的重要性
2. 通过适应性的属性
它们的区别是:第一种在训练之后进行剪枝,虽然时间的复杂度降低,但是也限制了加速比和压缩比。第二种方法需要将剪枝的要求嵌入到网络训练的损失,但是需要重新训练,比较花时间。
作者提出的了一种有效且高效的滤波器剪枝方法,该方法探索每一层特征图的高矩阵秩(HRank)。它是一种基于属性的修剪方法(第一种,不用重重新训练,简化了剪枝的复杂性)。 |
| idea | minδij∑i=1K∑j=1niδij(wji)∑t=1gRank(oji(t,:,:))\min _{\delta_{i j}} \sum_{i=1}^{K} \sum_{j=1}^{n_{i}} \delta_{i j}\left(\mathbf{w}_{j}^{i}\right) \sum_{t=1}^{g} \mathbf{R} \operatorname{ank}\left(\mathbf{o}_{j}^{i}(t,:,:)\right)minδij∑i=1K∑j=1niδij(wji)∑t=1gRank(oji(t,:,:))
s.t.∑j=1niδij=ni2s . t . \sum_{j=1}^{n_{i}} \delta_{i j}=n_{i 2}s.t.∑j=1niδij=ni21. 在大量统计验证的基础上,证明了单个滤波器生成的特征图的平均秩几乎没有变化。
2. 从数学上证明,具有较低秩特征图的过滤器信息量较小,因此对保持准确性不太重要,可以首先删除这些准确性。
3. 广泛的实验证明了HRank模型压缩和加速在各种最新技术状态下的效率和效果 |
| 讨论 | 我感觉这一种方法是训练之后进行操作,可以进行实现,可以参考 |
| 结果 | 文章在小数据集和大数据集上进行了实验,即CIFAR-10和ImageNet。研究了不同算法在主流CNN模型上的性能,包括VGGNet、GoogLeNet、ResNet和DenseNet。
例如:使用ResNet-110,通过删除59.2%的参数,我们实现了58.2%的FLOPS减少,而CIFAR-10的TOP-1准确率仅有0.14%的微小损失。使用ResNet-50,通过删除36.7%的参数,我们实现了43.8%的Flops减少,而ImageNet上的TOP1准确率仅损失了1.17%。 |
| 备注 | pytorch代码开源,可以下一步实验。
论文详细介绍
 |
6. Channel Pruning via Automatic Structure Search
| 题目 | Channel Pruning via Automatic Structure Search |
|---|
| 作者与单位 | IJCAI_2020 厦门大学 Mingbao Lin |
| 方法和要解决的问题 | 现有的剪枝方法大多侧重于通过重要性/最优化或基于经验规则设计的正则化来选择通道(滤波器),这是次优剪枝的缺陷。 |
| idea | Rethinking the value of network pruning. In ICLR, 2019论文表明,通道修剪的实质在于找到最优的修剪结构,即每层的通道数,而不是选择“重要”的通道。
为了解决深层网络中难以处理的巨大剪枝结构组合问题,首先提出将保留通道限制在特定空间内的组合缩小,从而大大减少剪枝结构的组合。然后,将最优剪枝结构的搜索问题转化为优化问题,并结合ABC算法进行自动求解,以减少人为干扰。ABCPruner已经被证明是更有效的,它还能够以端到端的方式高效地进行微调。 |
| 讨论 | 这个方法不同于先前选择那些重要的通道,而是选择通道数目为优化目标,也是探究的方向 |
| 结果 | 在CIFAR-10上进行的实验表明,ABCPruner减少了73.68%的FLOP和88.68%的参数,而VGGNet-16的准确度甚至提高了0.06%。在ILSVRC-2012上,它减少了62.87%的FLOP,并去除了60.01%的参数,而ResNet-152的准确度损失却微不足道。 |
| 备注 | pytorch代码开源,可以下一步实验。
论文详细介绍
 |
7. DropNet: Reducing Neural Network Complexity via Iterative Pruning
| 题目 | DropNet: Reducing Neural Network Complexity via Iterative Pruning |
|---|
| 作者与单位 | ICML_2020 新加坡
John Tan Chong
Min1Mehul Motani |
| 方法和要解决的问题 | DropNet迭代地删除所有训练样本中具有最低平均postactivation value的节点/滤波器。 |
| idea | 1.提出的DropNet,是一种带重新初始化权重的迭代节点/滤波器剪枝方法,它迭代地删除所有训练样本(无论是分层的还是全局的)激活后平均值最低的节点/滤波器,从而降低了网络复杂度。
2与几个基准指标相比,DropNet在广泛的场景中实现了有较好的鲁棒性。DropNet实现了与Oracle类似的性能,后者一次贪婪地删除一个节点/滤波器,以最大限度地减少训练损失。
3.DropNet不需要特殊的权重和偏差初始化(与(Frankle&Carbin,2018)不同)。在随后的实验中表明,剪枝模型的随机初始化将与原始初始化一样好。这意味着可以使用现成的机器学习库和硬件轻松部署DropNet删减的体系结构。 |
| 讨论 | 作者提出的实验是探究性的,只是自身的对比,采用的网络也是较小的神经网络。但是是第一个提出以样本平均激活值进行剪枝的文章。 |
| 结果 | 实验表明,高达90%的节点/滤波器可以被移除,而不会有任何明显的精度损失。即使在重新初始化权重和偏差的情况下,最终修剪后的网络也表现良好 |
| 备注 | tf2.0代码开源。
论文详细介绍 |
8. DMCP: Differentiable Markov Channel Pruning for Neural Networks
| 题目 | DMCP: Differentiable Markov Channel Pruning for Neural Networks |
|---|
| 作者与单位 | CVPR_2020 旷视
Shaopeng Guo |
| 方法和要解决的问题 | 作者提出了一种新颖的通道剪枝方法,叫做Differentiable Markov Channel Pruning (DMCP),去有效搜索最优子结构。 |
| idea | 方法是可微的,可以通过标准任务损失(交叉熵损失)和预算正则化(FLOPs和latcy限制)的梯度下降来直接优化。在DMCP中,将通道剪枝建模为马尔可夫过程,其中每个状态表示在剪枝过程中保留相应的通道,状态之间的转换表示剪枝过程。最后,能够通过优化转移概率后的马尔可夫过程隐式地选择每一层中合适的通道数目。为了验证该方法的有效性,作者使用ResNet和MobilenetV2在Imagenet上进行了大量的实验 |
| 讨论 | 作者采用的是空间搜索的方法,利用马尔科夫过程使有效解的数量得到了下降,并构造出了预算条件下的损失函数并使其变得可微,采用梯度下降的方法求解。 |
| 结果 | 实验结果表明,在不同的FLOPs设置下,该方法比最新的剪枝方法都能获得相当的改进。 |
| 备注 | 代码开源tf1.x
论文详细介绍
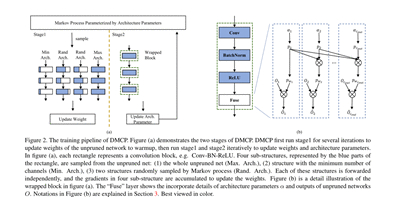 |
9. Rethinking the Value of Network Pruning
| 题目 | Rethinking the Value of Network Pruning |
|---|
| 作者与单位 | ICLR_2019 伯克利分校
刘壮 |
| idea | 1.对于已经预定义网络结构(每层的通道数已知)的修剪,我们可以直接训练出一个小网络,所以这时候训练一个过参数化的大模型没有什么必要。
2.作者做了很多对比实验说明了从头训练(随机初始化)的网络(结构化得剪枝)可以获得与剪枝、微调这种方法相当的精度(甚至更好)。这阐明了一个结论,就是我们做剪枝是为了学习网络的结构(每一层的宽度),而不是“重要的”权重。
3.作者与The Lottery Ticket Hypothesis做了对比,发现在最优学习率下,Frankle&Carbin(2019年)使用的“中奖彩票”初始化并没有带来比随机初始化更好的效果。 |
| 讨论 | 作者的实验打脸很多的结构化剪枝方法。可以把剪枝作为结构搜索。 |
| 备注 | 代码开源
论文详细介绍
 |








 京公网安备 11010802041100号
京公网安备 11010802041100号