作者:嘉信永顺_232 | 来源:互联网 | 2023-07-25 14:08
雷锋网(公众号:雷锋网)按:为了方便读者学习和收藏,雷锋网特地把吴恩达教授在NIPS2016大会中的PPT做为中文版,由三川和亚峰联合编译并制作。今日,在第30届神经信息处理系统大
雷锋网(公众号:雷锋网)按:为了方便读者学习和收藏,雷锋网特地把吴恩达教授在NIPS 2016大会中的PPT做为中文版,由三川和亚峰联合编译并制作。
今日,在第 30 届神经信息处理系统大会(NIPS 2016)中,百度首席科学家吴恩达教授发表演讲:《利用深度学习开发人工智能应用的基本要点(Nuts and Bolts of Building Applications using Deep Learning)》。
此外,吴恩达教授曾在今年 9 月 24/25 日也发表过同为《Nuts and Bolts of Applying Deep Learning》的演讲(1小时20分钟),以下是 YouTube 链接:
https://www.youtube.com/watch?v=F1ka6a13S9I

一、深度学习为何崛起
吴恩达在开场提到:深度学习为何这么火?
答案很简单:
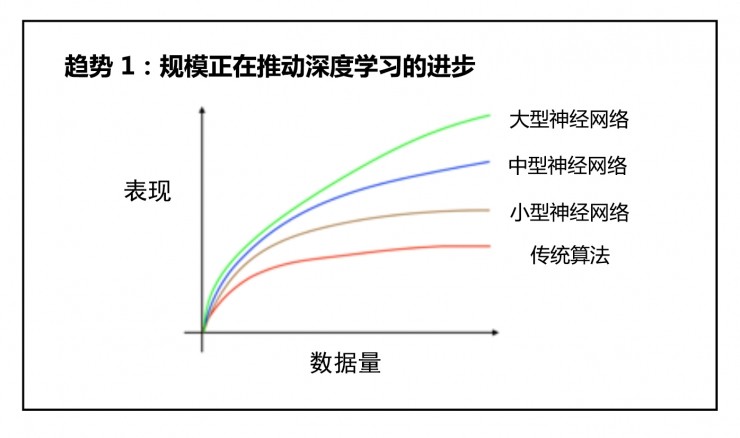
第一是因为规模正在推动深度学习的进步。
从传统算法到小型神经网络、中型神经网络最后演化为现在的大型神经网络。
第二:端到端学习的崛起
从下图中的上半部分可以看出,传统端到端学习是把实体数据表达成数字数据,输出数字值作为结果。如退昂识别最后以整数标签输出为结果。

而现在的端对端学习更为直接纯粹,如机器翻译:输入英语文本,输出法语文本;语音识别:输入音频,输出文本。但端对端学习需要大量的训练集。
吴恩达先讲述了常见的深度学习模型,然后再着分析端到端学习的具体应用。
二、主要的深度学习模型

-
普通神经网络
-
顺序模型 (1D 顺序) RNN, GRU, LSTM, CTC, 注意力模型
-
图像模型 2D 和 3D 卷积神经网络
-
先进/未来 技术:无监督学习(稀疏编码 ICA, SFA,)增强学习
三、端到端学习应用案例
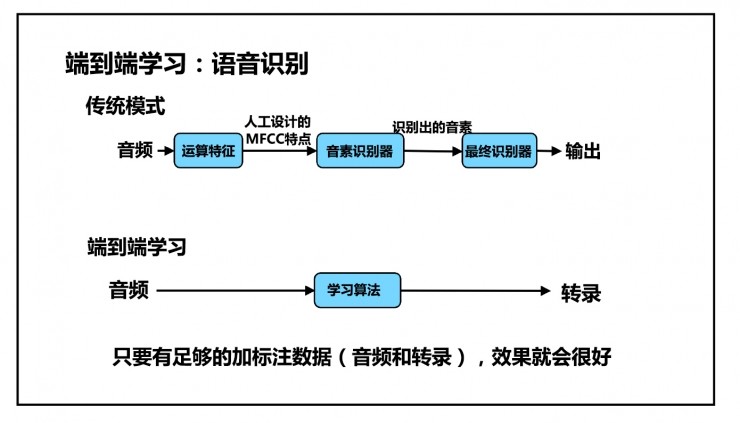
传统模型:语音→运算特征—(人工设计的 MFCC 特征)→音素识别器—(音素识别)→最终识别器→输出。
端到端学习:音频→学习算法→转录结果;在给定了足够的有标注数据(音频、转录结果)时,这种方法的效果会很好。
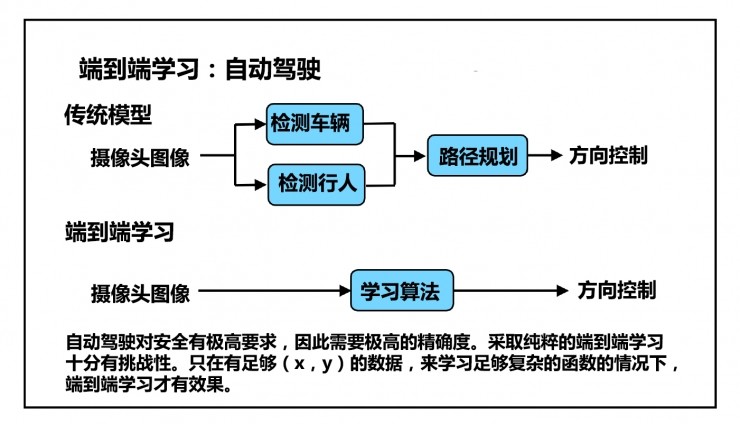
传统模型:摄像头图像→检测汽车+检测行人→路径规划→方向控制。
端到端学习:摄像头图像→学习算法→方向控制。
自动驾驶对安全有极高要求,因此需要极高的精确度。采取纯粹的端到端学习十分有挑战性。只在有足够(x,y)的数据,来学习足够复杂的函数的情况下,端到端学习才有效果。
四、机器学习策略
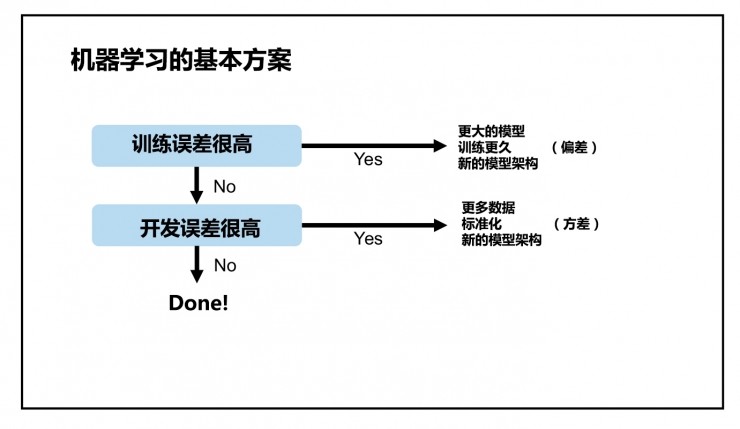
你经常有很多改进 AI 系统的主意,应该怎么做?好的战略能避免浪费数月精力做无用的事。

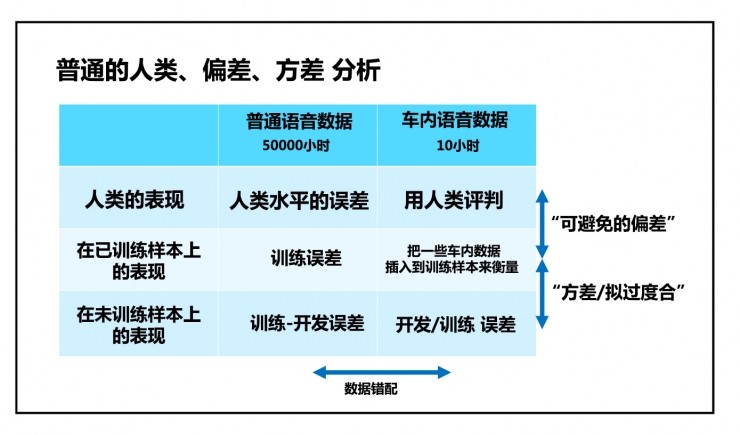
以语音识别为例,可以把原语音数据分割成:
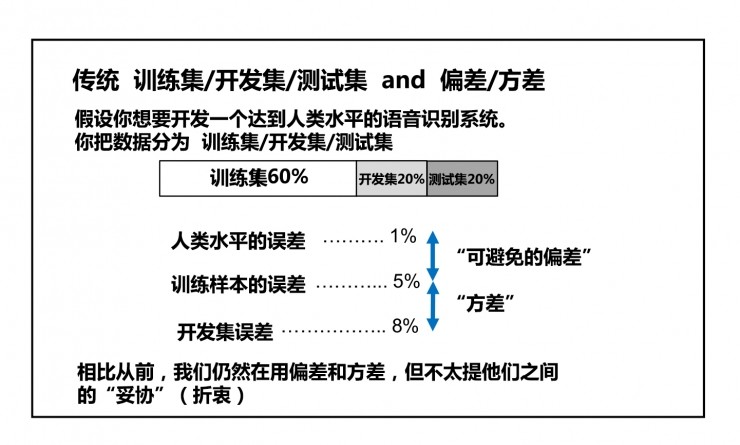
这里面普及几个概念:
人类水平的误差与训练集的误差之间的差距是可避免的偏差,这部分误差可以通过进一步的学习/模型调整优化来避免。
训练集和开发集之间的差距称为方差,其因为跑了不同的数据从而导致误差率变化。
上述两种偏差合在一起,就是偏差-方差权衡(bias-variance trade-off)。
-
自动数据合成示例
-
不同训练、测试集的分布
假设你想要为一个汽车后视镜产品,开发语音识别系统。你有 5000 小时的普通语音数据,还有 10 小时的车内数据。你怎么对数据分组呢?这是一个不恰当的方式:
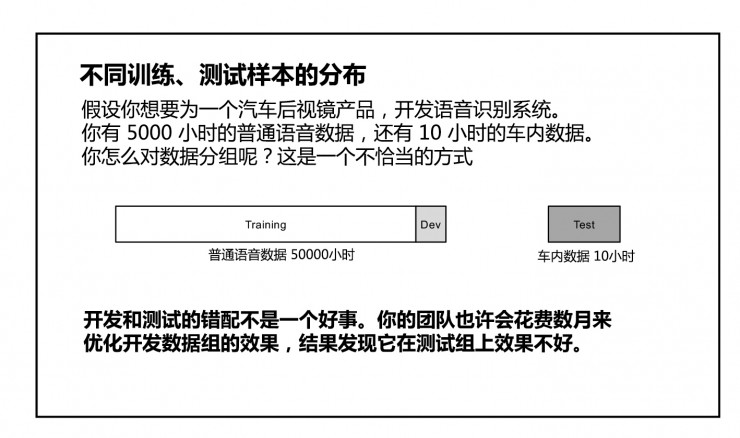
更好的方式:让开发和测试集来自同样的分配机制。

五、机器学习新方案
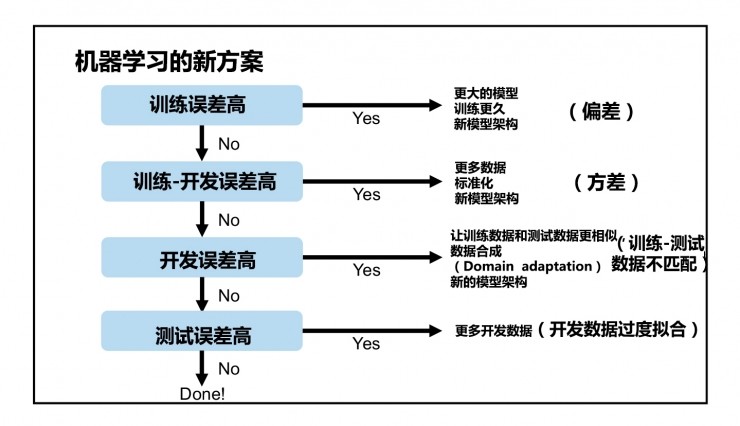
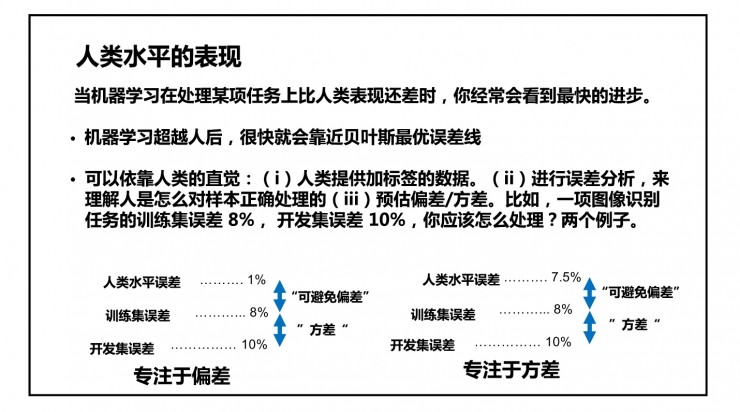
当机器学习在处理某项任务上比人类表现还差时,你经常会看到最快的进步。
机器学习超越人后,很快就会靠近贝叶斯最优误差线。
可以依靠人类的直觉:(i)人类提供加标签的数据。(ii)进行错误分析,来理解人是怎么对样本正确处理的(iii)预估偏差/方差。比如,一项图像识别任务的训练误差 8%, 开发误差 10%,你应该怎么处理?

六、人工智能产品管理

新的监督DL算法的存在,意味着对使用 DL开发应用的团队合作,我们在重新思考工作流程。产品经理能帮助 AI 团队,优先进行最出成果的机器学习任务。比如,对于汽车噪音、咖啡馆的谈话声、低带宽音频、带口音的语音,你是应该提高语音效果呢,还是改善延迟,缩小二进制,还是做别的什么?
今天的人工智能能做什么呢?这里给产品经理一些启发:
如果一个普通人完成一项智力任务只需不到一秒的思考时间,我们很可能现在,或者不远的将来,用 AI 把该任务自动化。
对于我们观察到的具体的、重复性的事件(比如用户点击广告;快递花费的时间),我们可以合理地预测下一个事件的结果(用户是否点击下一个此类广告)。

七、吴恩达新书推荐

。









 京公网安备 11010802041100号
京公网安备 11010802041100号