转自:https://juejin.cn/post/6844903857558913038
最近在看Apache pulsar这个被誉为下一代消息队列的相关的,我之前其实已经写过很多kafka,rocketmq相关的文章,本来以为消息队列的技术大体花样都差不多,但是当我看到了pulsar的确被他的一些设计给惊艳到了。这篇文章是我看pulsar的时候觉得不错的一篇英文文章,在网上找了一下译文,直接转载给大家看。
Exactly once is NOT exactly the same 分布式事件流处理正逐渐成为大数据领域中一个热门话题。著名的流处理引擎(Streaming Processing Engines, SPEs)包括Apache Storm、Apache Flink、Heron、Apache Kafka(Kafka Streams)以及Apache Spark(Spark Streaming)。流处理引擎中一个著名的且经常被广泛讨论的特征是它们的处理语义,而“exactly-once”是其中最受欢迎的,同时也有很多引擎声称它们提供“exactly-once”处理语义。
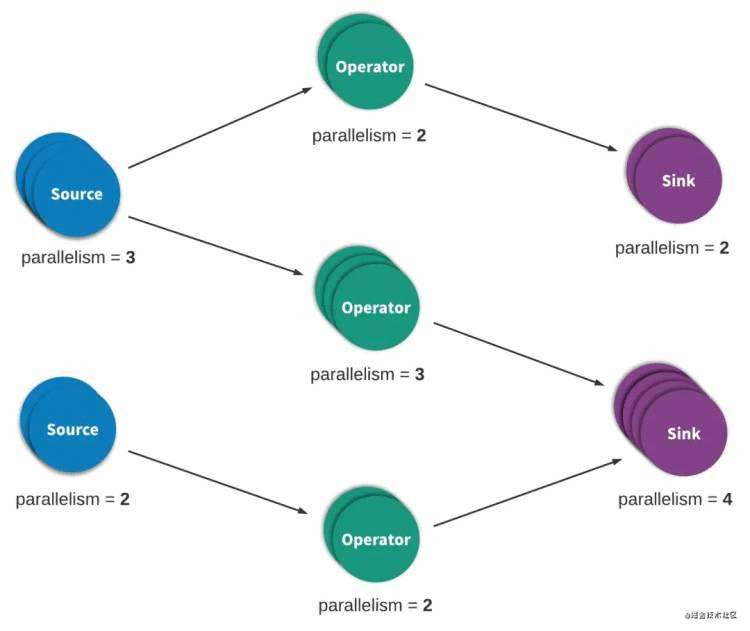
背景 流处理(streaming process),有时也被称为事件处理(event processing),可以被简洁地描述为对于一个无限的数据或事件序列的连续处理。一个流,或事件,处理应用可以或多或少地由一个有向图,通常是一个有向无环图(DAG),来表达。在这样一个图中,每条边表示一个数据或事件流,而每个顶点表示使用应用定义好的逻辑来处理来自相邻边的数据或事件的算子。其中有两种特殊的顶点,通常被称作sources与sinks。Sources消费外部数据/事件并将其注入到应用当中,而sinks通常收集由应用产生的结果。图1描述了一个流处理应用的例子。
A typical Heron processing topology
图1 一个典型的Heron处理拓扑
At-most-once 这实质上是一个“尽力而为”(best effort)的方法。数据或者事件被保证只会被应用中的所有算子最多处理一次。这就意味着对于流处理应用完全处理它之前丢失的数据,也不会有额外的重试或重传尝试。图2展示了一个相关的例子:
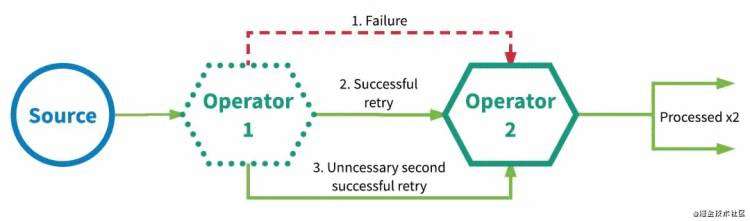
图2 At-most-once处理语义 At-least-once 数据或事件被保证会被应用图中的所有算子都至少处理一次。这通常意味着当事件在被应用完全处理之前就丢失的话,其会被从source开始重放(replayed)或重传(retransmitted)。由于事件会被重传,那么一个事件有时就会被处理超过一次,也就是所谓的at-least-once。图3展示了一个at-least-once的例子。在这一示例中,第一个算子第一次处理一个事件时失败,之后在重试时成功,并在结果证明没有必要的第二次重试时成功。
图3 At-least-once处理语义 Exactly-once 倘若发生各种故障,事件也会被确保只会被流应用中的所有算子“恰好”处理一次。拿来实现“exactly-once”的有两种受欢迎的典型机制:1. 分布式快照/状态检查点(checkpointing) 2. At-least-once的事件投递加上消息去重
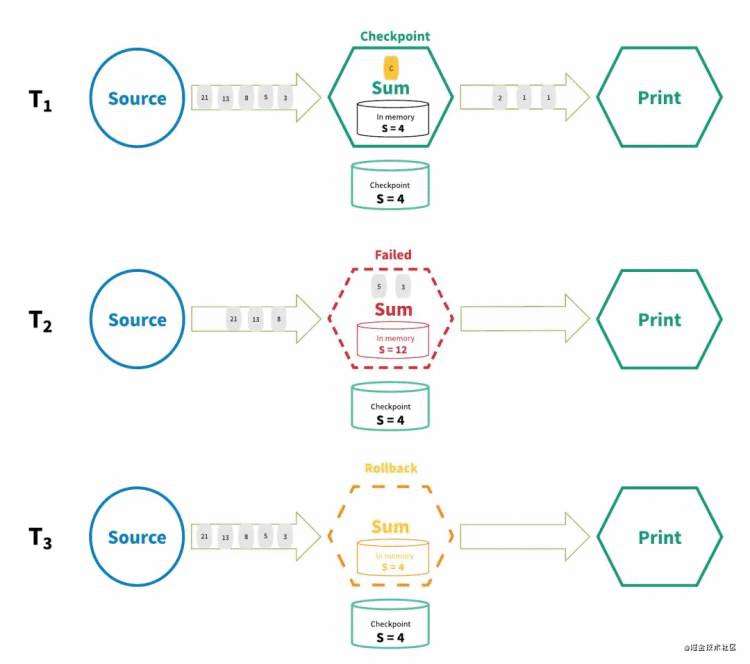
Distributed snapshot
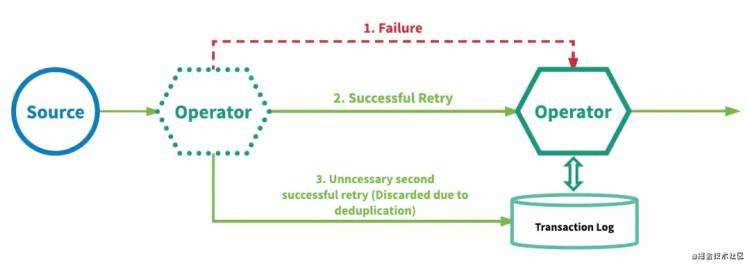
图4 分布式快照 图5 At-least-once结合去重 exactly-once确实是exactly-once吗? 现在让我们重新审视『精确一次』处理语义真正对最终用户的保证。『精确一次』这个术语在描述正好处理一次时会让人产生误导。
有些人可能认为『精确一次』描述了事件处理的保证,其中流中的每个事件只被处理一次。实际上,没有引擎能够保证正好只处理一次。在面对任意故障时,不可能保证每个算子中的用户定义逻辑在每个事件中只执行一次,因为用户代码被部分执行的可能性是永远存在的。
Map (Event event ) {"Event ID: " + event .getId()event
每个事件都有一个 GUID (全局惟一ID)。如果用户逻辑的精确执行一次得到保证,那么事件 ID 将只输出一次。但是,这是无法保证的,因为在用户定义的逻辑的执行过程中,随时都可能发生故障。引擎无法自行确定执行用户定义的处理逻辑的时间点。因此,不能保证任意用户定义的逻辑只执行一次。这也意味着,在用户定义的逻辑中实现的外部操作(如写数据库)也不能保证只执行一次。此类操作仍然需要以幂等的方式执行。
那么,当引擎声明『精确一次』处理语义时,它们能保证什么呢?如果不能保证用户逻辑只执行一次,那么什么逻辑只执行一次?当引擎声明『精确一次』处理语义时,它们实际上是在说,它们可以保证引擎管理的状态更新只提交一次到持久的后端存储。
上面描述的两种机制都使用持久的后端存储作为真实性的来源,可以保存每个算子的状态并自动向其提交更新。对于机制 1 (分布式快照 状态检查点),此持久后端状态用于保存流应用程序的全局一致状态检查点(每个算子的检查点状态)。对于机制 2 (至少一次事件传递加上重复数据删除),持久后端状态用于存储每个算子的状态以及每个算子的事务日志,该日志跟踪它已经完全处理的所有事件。
提交状态或对作为真实来源的持久后端应用更新可以被描述为恰好发生一次。然而,如上所述,计算状态的更新 更改,即处理在事件上执行任意用户定义逻辑的事件,如果发生故障,则可能不止一次地发生。换句话说,事件的处理可以发生多次,但是该处理的效果只在持久后端状态存储中反映一次。因此,我们认为有效地描述这些处理语义最好的术语是『有效一次』(effectively once)。
那么,当引擎声明『精确一次』处理语义时,它们能保证什么呢?如果不能保证用户逻辑只执行一次,那么什么逻辑只执行一次?当引擎声明『精确一次』处理语义时,它们实际上是在说,它们可以保证引擎管理的状态更新只提交一次到持久的后端存储
分布式快照 vs at-least-once 从语义的角度来看,分布式快照和至少一次事件传递以及重复数据删除机制都提供了相同的保证。然而,由于两种机制之间的实现差异,存在显着的性能差异。
机制 1(分布式快照 状态检查点)的性能开销是最小的,因为引擎实际上是往流应用程序中的所有算子一起发送常规事件和特殊事件,而状态检查点可以在后台异步执行。但是,对于大型流应用程序,故障可能会更频繁地发生,导致引擎需要暂停应用程序并回滚所有算子的状态,这反过来又会影响性能。流式应用程序越大,故障发生的可能性就越大,因此也越频繁,反过来,流式应用程序的性能受到的影响也就越大。然而,这种机制是非侵入性的,运行时需要的额外资源影响很小。
机制 2(至少一次事件传递加重复数据删除)可能需要更多资源,尤其是存储。使用此机制,引擎需要能够跟踪每个算子实例已完全处理的每个元组,以执行重复数据删除,以及为每个事件执行重复数据删除本身。这意味着需要跟踪大量的数据,尤其是在流应用程序很大或者有许多应用程序在运行的情况下。执行重复数据删除的每个算子上的每个事件都会产生性能开销。但是,使用这种机制,流应用程序的性能不太可能受到应用程序大小的影响。对于机制 1,如果任何算子发生故障,则需要发生全局暂停和状态回滚;对于机制 2,失败的影响更加局部性。当在算子中发生故障时,可能尚未完全处理的事件仅从上游源重放/重传。性能影响与流应用程序中发生故障的位置是隔离的,并且对流应用程序中其他算子的性能几乎没有影响。从性能角度来看,这两种机制的优缺点如下。
分布式快照 状态检查点的优缺点:
至少一次事件传递以及重复数据删除机制的优缺点:
虽然从理论上讲,分布式快照和至少一次事件传递加重复数据删除机制之间存在差异,但两者都可以简化为至少一次处理加幂等性。对于这两种机制,当发生故障时(至少实现一次),事件将被重放/重传,并且通过状态回滚或事件重复数据删除,算子在更新内部管理状态时本质上是幂等的。
总结 在这篇博客文章中,我希望能够让你相信『精确一次』这个词是非常具有误导性的。提供『精确一次』的处理语义实际上意味着流处理引擎管理的算子状态的不同更新只反映一次。『精确一次』并不能保证事件的处理,即任意用户定义逻辑的执行,只会发生一次。我们更喜欢用『有效一次』(effectively once)这个术语来表示这种保证,因为处理不一定保证只发生一次,但是对引擎管理的状态的影响只反映一次。两种流行的机制,分布式快照和重复数据删除,被用来实现精确/有效的一次性处理语义。这两种机制为消息处理和状态更新提供了相同的语义保证,但是在性能上存在差异。这篇文章并不是要让你相信任何一种机制都优于另一种,因为它们各有利弊。












 京公网安备 11010802041100号
京公网安备 11010802041100号