Hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算框架)+Yarn(资源协调框架)+Common模块
1、Hadoop HDFS:(Hadoop Distribute File System )一个高可靠、高吞吐量的分布式文件系统
比如:100T数据存储,“分而治之”
分:拆分–》数据切割,100T数据拆分为10G一个数据块由一个电脑节点存储这个数据块。
数据切割、制作副本、分散储存
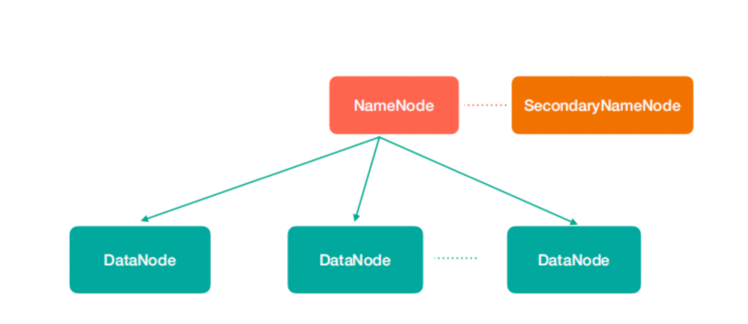
图中涉及到几个角色
NameNode(nn): 存储文件的元数据,比如文件名、文件目录结构、文件属性(生成时间、副
本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
SecondaryNameNode(2nn): 辅助NameNode更好的工作,用来监控HDFS状态的辅助后台
程序,每隔一段时间获取HDFS元数据快照。
DataNode(dn): 在本地文件系统存储文件块数据,以及块数据的校验。
注意:NN,2NN,DN这些既是角色名称,进程名称,代指电脑节点名称!!!
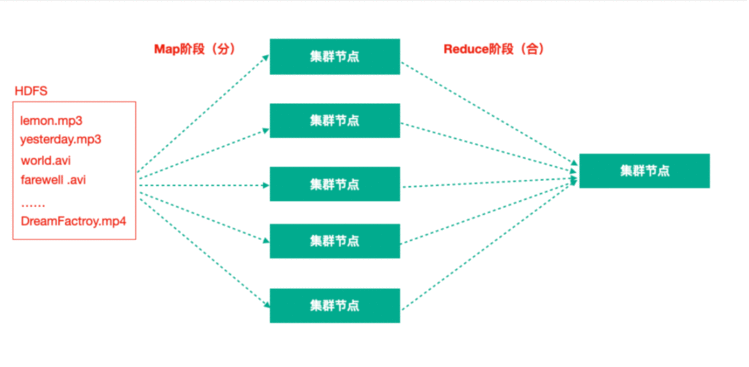
2、Hadoop MapReduce:一个分布式的离线并行计算框架
拆解任务、分散处理、汇整结果
MapReduce计算 = Map阶段 + Reduce阶段
Map阶段就是“分”的阶段,并行处理输入数据;
Reduce阶段就是“合”的阶段,对Map阶段结果进行汇总;
3、Hadoop YARN:作业调度与集群资源管理的框架
计算资源协调
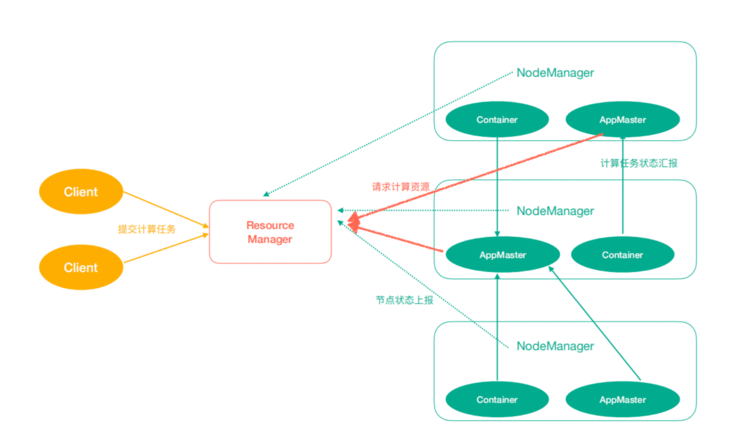
Yarn中有如下几个主要角色,同样,既是角色名、也是进程名,也指代所在计算机节点名称。
ResourceManager(rm): 处理客户端请求、启动/监控ApplicationMaster、监控
NodeManager、资源分配与调度。
NodeManager(nm): 单个节点上的资源管理、处理来自ResourceManager的命令、处理来自
ApplicationMaster的命令。
ApplicationMaster(am): 数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
Container: 对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
ResourceManager是老大,NodeManager是小弟,ApplicationMaster是计算任务专员。
4、Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)
1、HDFS 简介
HDFS (全称:Hadoop Distribute File System,Hadoop 分布式文件系统)是 Hadoop 核心组成,是分布式存储服务。
分布式文件系统横跨多台计算机,在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
HDFS是分布式文件系统中的一种。
2、HDFS的重要概念
HDFS 通过统一的命名空间目录树来定位文件; 另外,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色(分布式本质是拆分,各司其职)。
2.1 典型的 Master/Slave 架构
2.2 分块存储(block机制)
2.3 命名空间(NameSpace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动 或重命名文件。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被 Namenode 记录下来。
HDFS提供给客户单一个抽象目录树,访问形式:hdfs://namenode的hostname:port/test/inputhdfs://linux121:9000/test/input
2.4 NameNode元数据管理
我们把目录结构及文件分块位置信息叫做元数据。
NameNode的元数据记录每一个文件所对应的block信息(block的id,以及所在的DataNode节点的信息)
2.5 DataNode数据存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。
一个block会有多个DataNode来存储,DataNode会定时向NameNode来汇报自己持有的block信息。
2.6 副本机制
2.7 一次写入,多次读出
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的随机修改。 (支持追加写入, 不只支持随机更新)
正因为如此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用(修改不方便,延迟大,网络开销大,成本太高)
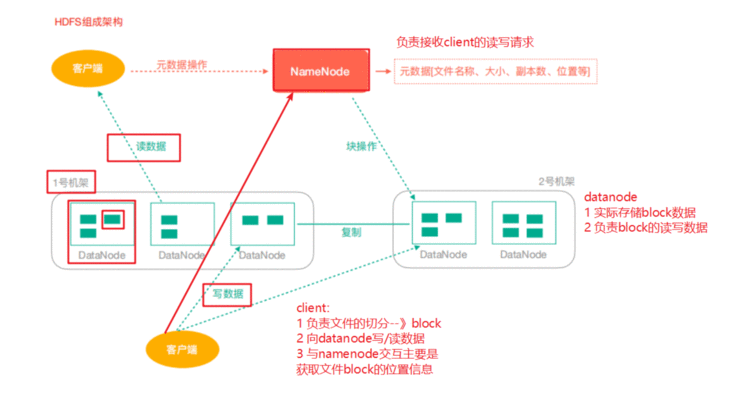
3、HDFS 架构
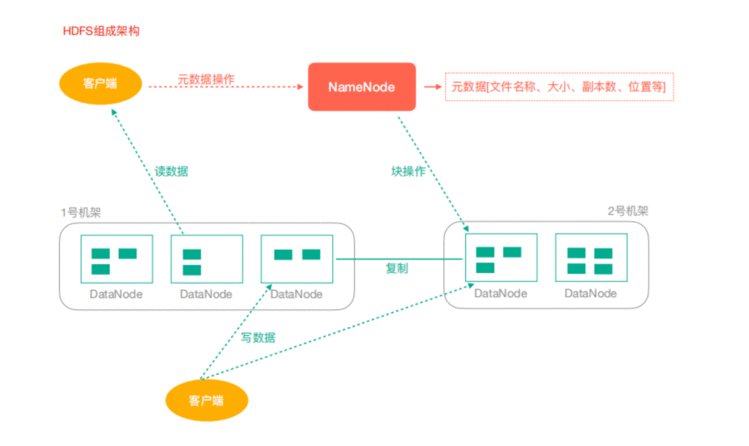
3.1 NameNode(nn): Hdfs集群的管理者,Master
3.2 DataNode:NameNode下达命令,DataNode执行实际操作,Slave节点。
3.3 Client:客户端
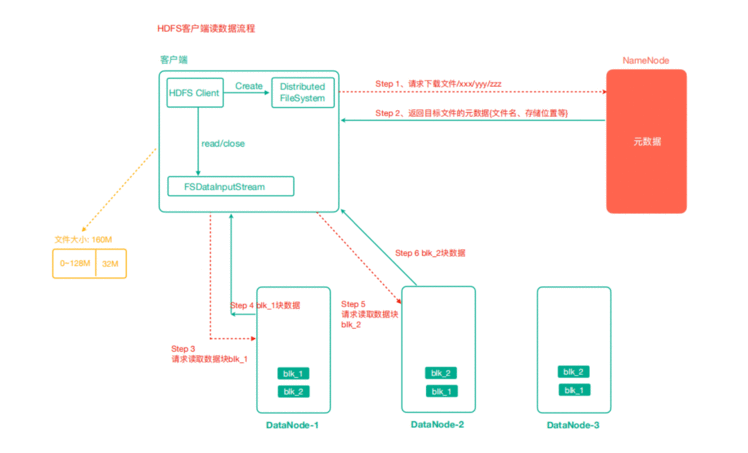
4、HDFS读写解析
4.1 HDFS读数据流程
4.2 HDFS写数据流程
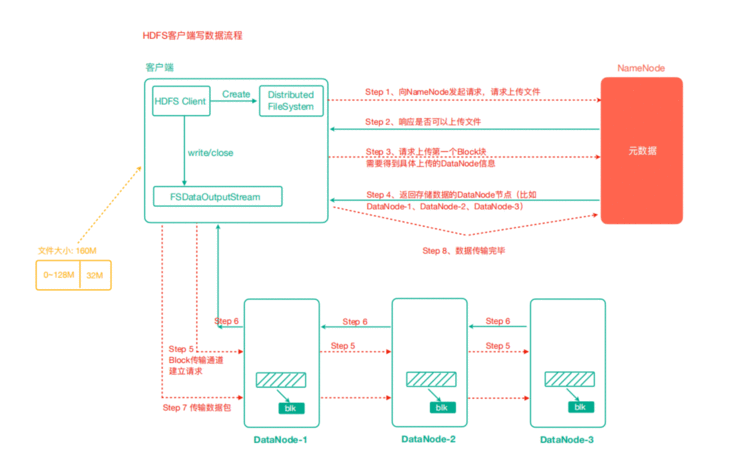
4.3 验证Packet代码
@Test
public void testUploadPacket() throws IOException {// 1.准备读取本地文件的输入流final FileInputStream in = new FileInputStream(new File("d:/riemann.txt"));// 2.准备好写出数据到hdfs的输出流final FSDataOutputStream out = fs.create(new Path("/riemann.txt"), new Progressable() {public void progress() {// 这个progress方法就是每传输64KB(packet)就会执行一次,System.out.println("&");}});// 3.实现流拷贝IOUtils.copyBytes(in, out, configuration); // 默认关闭流选项是true,所以会自动关闭// 4.关流 可以再次关闭也可以不关了
}
5、HDFS元数据管理机制
问题1:NameNode如何管理和存储元数据?
计算机中存储数据两种:内存或者是磁盘
元数据存储磁盘:存储磁盘无法面对客户端对元数据信息的任意的快速低延迟的响应,但是安全性高。
元数据存储内存:元数据存放内存,可以高效的查询以及快速响应客户端的查询请求,数据保存在内 存,如果断点,内存中的数据全部丢失。
解决方案:内存+磁盘; NameNode内存+FsImage的文件(磁盘)
新问题:磁盘和内存中元数据如何划分?
两个数据一模一样,还是两个数据合并到一起才是一份完整的数据呢?
一模一样:client如果对元数据进行增删改操作,需要保证两个数据的一致性。FsImage文件操作起来 效率也不高。
两个合并=完整数据:NameNode引入了一个edits文件(日志文件:只能追加写入)edits文件记录的 是client的增删改操作,
不再选择让NameNode把数据dump出来形成FsImage文件(这种操作是比较消耗资源)。
元数据管理流程图
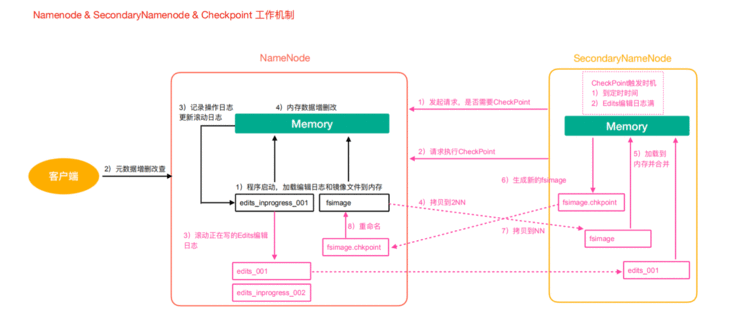
5.1 第一阶段:NameNode启动
5.2 第二阶段:Secondary NameNode工作
1、MapReduce思想
MapReduce思想在生活中处处可见。我们或多或少都曾接触过这种思想。MapReduce的思想核心是分 而治之。
充分利用了并行处理的优势。
即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
MapReduce任务过程是分为两个处理阶段:
再次理解MapReduce的思想
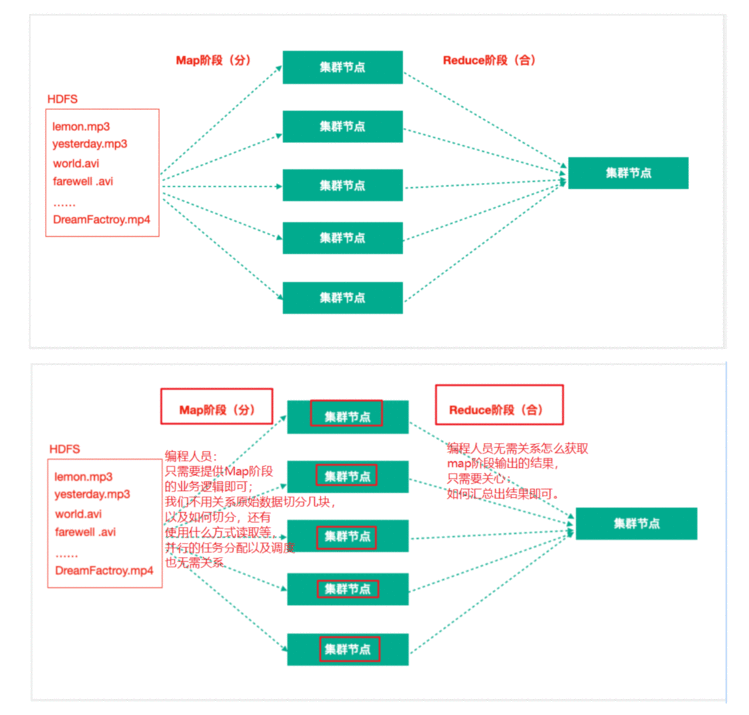
2、MapReduce原理分析
2.1 MapTask运行机制详解
MapTask流程
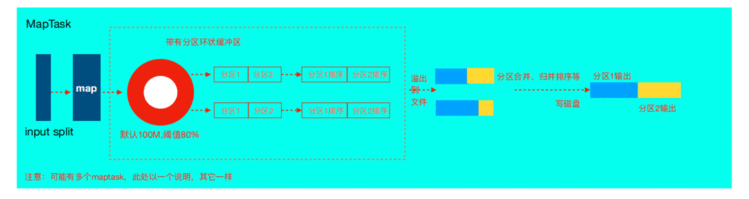
详细步骤:
至此map整个阶段结束!!
MapTask的一些配置

官方参考地址
https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
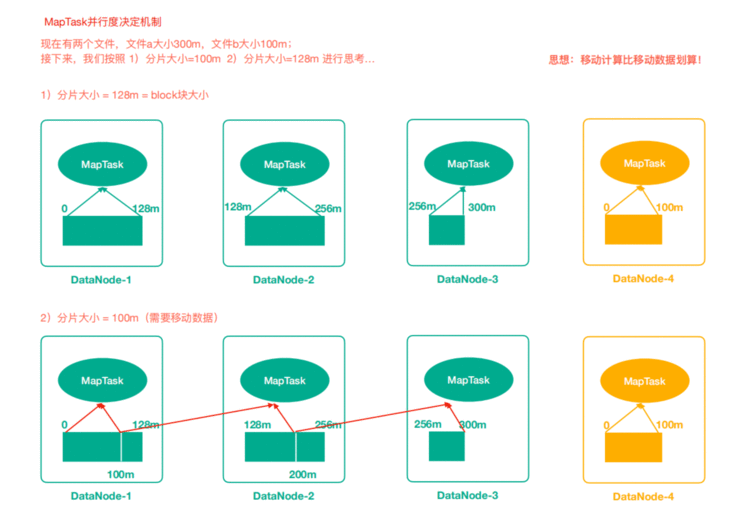
2.2 MapTask的并行度
MapTask并行度思考
MapTask的并行度决定Map阶段的任务处理并发度,从而影响到整个Job的处理速度。
MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。
切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
2.2.1 切片机制源码阅读
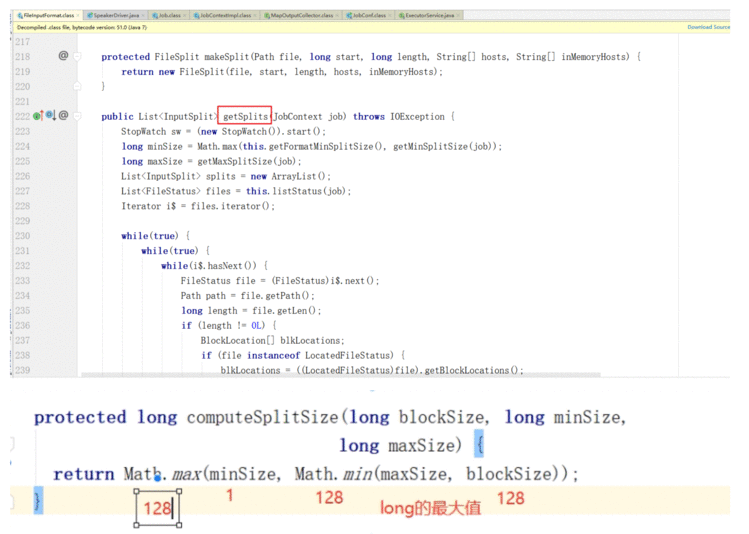
默认就是128M;
MapTask并行度是不是越多越好呢?
答案不是,如果一个文件仅仅比128M大一点点也被当成一个split来对待,而不是多个split.
MR框架在并行运算的同时也会消耗更多资源,并行度越高资源消耗也越高,假设129M文件分为两个分 片,一个是128M,一个是1M;
对于1M的切片的Maptask来说,太浪费资源。
129M的文件在Hdfs存储的时候会不会切成两块?
2.3 ReduceTask 工作机制
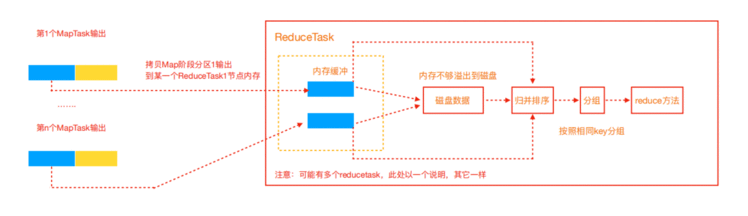
Reduce大致分为copy、sort、reduce三个阶段,重点在前两个阶段。copy阶段包含一个 eventFetcher来获取已完成的map列表,由Fetcher线程去copy数据,在此过程中会启动两个merge线 程,分别为inMemoryMerger和onDiskMerger,分别将内存中的数据merge到磁盘和将磁盘中的数据 进行merge。待数据copy完成之后,copy阶段就完成了,开始进行sort阶段,sort阶段主要是执行 finalMerge操作,纯粹的sort阶段,完成之后就是reduce阶段,调用用户定义的reduce函数进行处理。
详细步骤
2.4 ReduceTask并行度
ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定
不同,ReduceTask数量的决定是可以直接手动设置:
// 默认值是1,手动设置为4
job.setNumReduceTasks(4);
注意事项
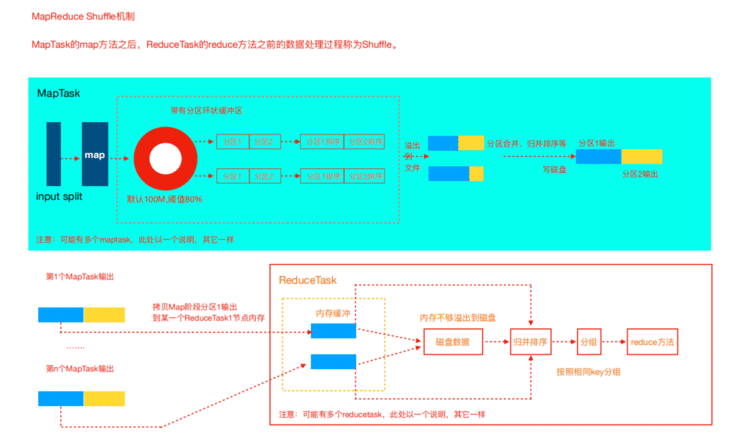
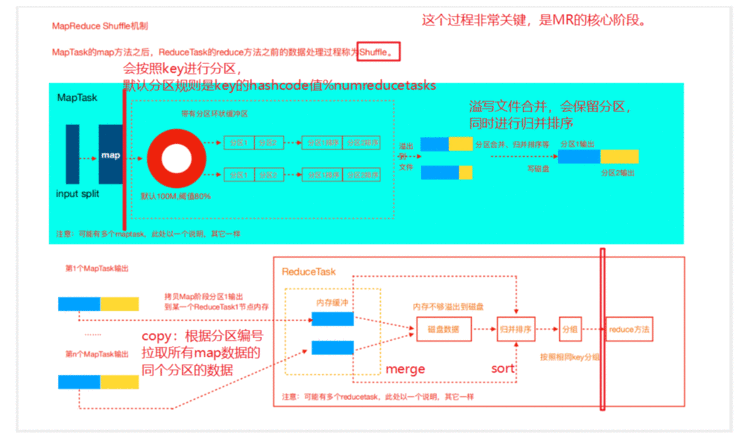
2.5 Shuffle机制
map阶段处理的数据如何传递给reduce阶段,是MapReduce框架中最关键的一个流程,这个流程就叫
shuffle。
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,分组,combine,合并等过程)
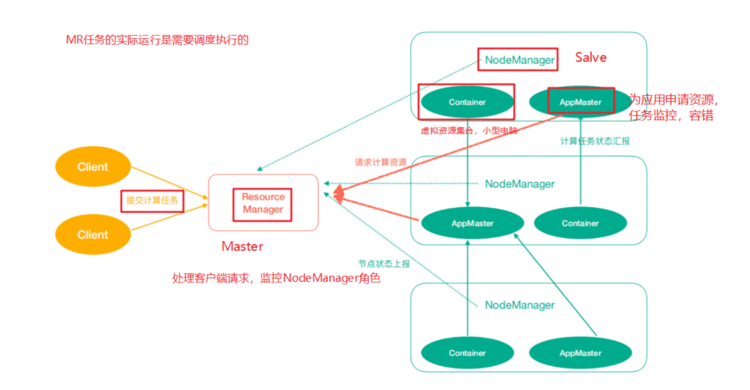
1、Yarn架构
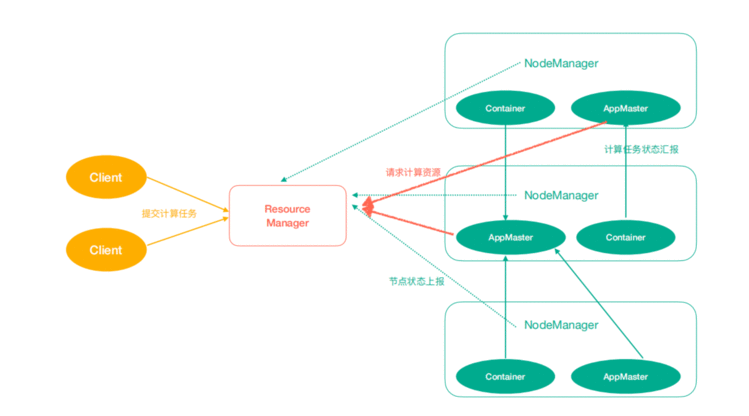
ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资 源分配与调度;
NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自 ApplicationMaster的命令;
ApplicationMaster(am):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运
行相关的信息。
2、Yarn任务提交(工作机制)
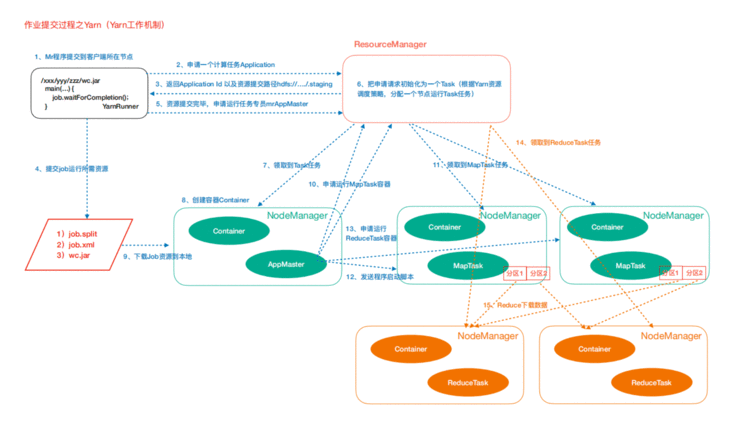
作业提交过程之YARN
3、 Yarn调度策略
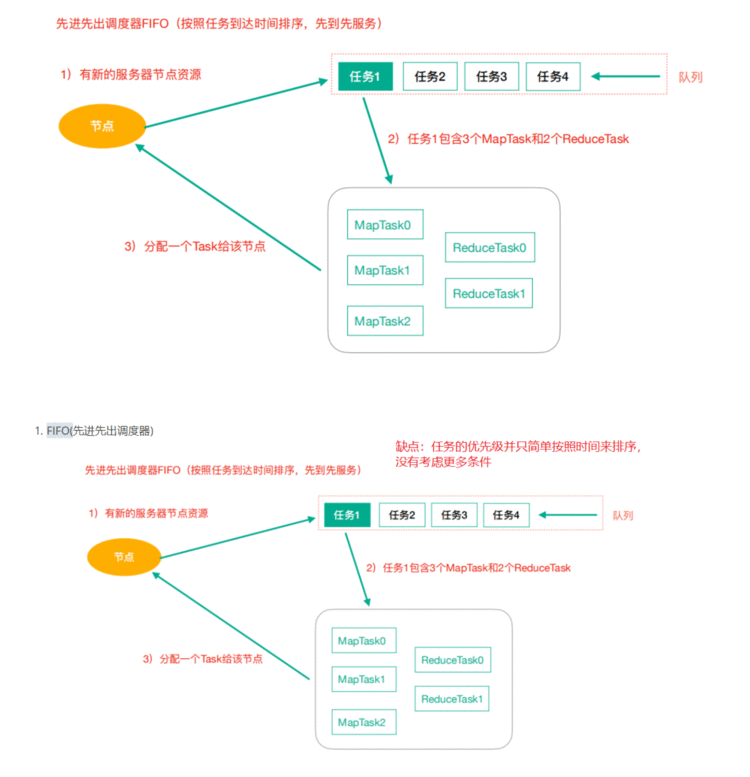
Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.9.2默认的资源调度器是Capacity Scheduler。
3.1 FIFO(先进先出调度器)
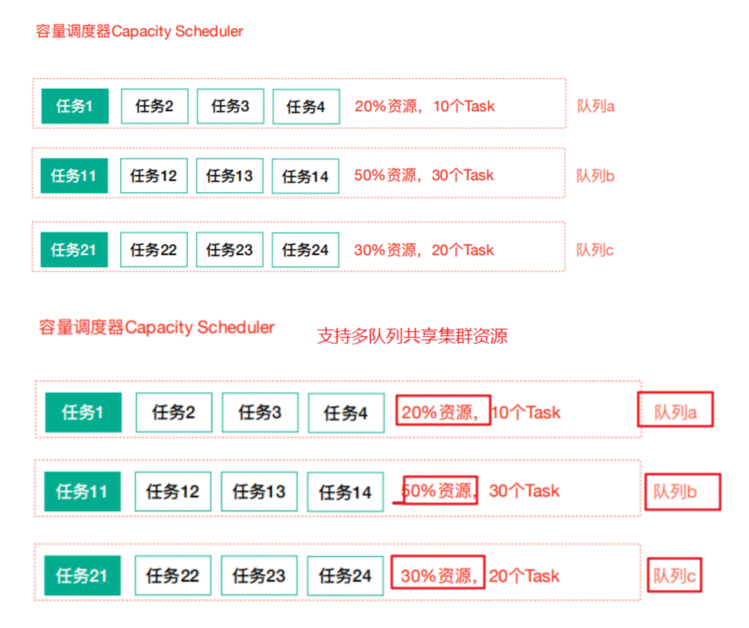
3.2 容量调度器(Capacity Scheduler 默认的调度器)
Apache Hadoop默认使用的调度策略。Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集 群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内 部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部, 资源的调度是采用的是先进先出(FIFO)策略。
3.3 Fair Scheduler(公平调度器,CDH版本的hadoop默认使用的调度器)
Fair调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。公 平调度在也可以在多个队列间工作。举个例子,假设有两个用户A和B,他们分别拥有一个队列。 当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运 行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它 job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之 一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。
3.4 Yarn多租户资源隔离配置
Yarn集群资源设置为A,B两个队列,
3.5 选择使用Fair Scheduler调度策略
3.5.1 yarn-site.xml
<property><name>yarn.resourcemanager.scheduler.classname><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSch edulervalue><description>In case you do not want to use the default schedulerdescription>
property>
3.5.2 创建fair-scheduler.xml文件
在Hadoop安装目录/etc/hadoop创建该文件
<allocations><defaultQueueSchedulingPolicy>fairdefaultQueueSchedulingPolicy><queue name&#61;"root" ><queue name&#61;"default"><aclAdministerApps>*aclAdministerApps><aclSubmitApps>*aclSubmitApps><maxResources>9216 mb,4 vcoresmaxResources><maxRunningApps>100maxRunningApps><minResources>1024 mb,1vcoresminResources><minSharePreemptionTimeout>1000minSharePreemptionTimeout><schedulingPolicy>fairschedulingPolicy><weight>7weight>queue><queue name&#61;"queue1"><aclAdministerApps>*aclAdministerApps><aclSubmitApps>*aclSubmitApps><maxResources>4096 mb,4vcoresmaxResources><maxRunningApps>5maxRunningApps><minResources>1024 mb, 1vcoresminResources><minSharePreemptionTimeout>1000minSharePreemptionTimeout><schedulingPolicy>fairschedulingPolicy><weight>3weight>queue>queue><queuePlacementPolicy><rule create&#61;"false" name&#61;"specified"/><rule create&#61;"true" name&#61;"default"/>queuePlacementPolicy>
allocations>
3.5.3 界面验证
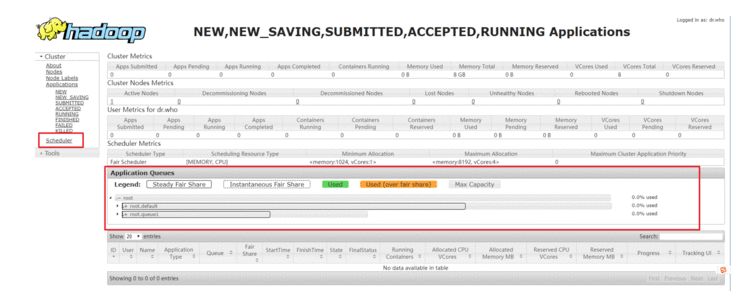










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有