作者:吃羊的肉 | 来源:互联网 | 2023-10-12 10:13
在学习黑马程序员出品的机器学习视频做的代码笔记。
代码中直接调用jieba第三方库进行分词,还可再做改进,关于英文分词的文章可以看这个英文文本分词改进
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def countvec():
"""
对文本进行特征值化
:return:None
"""
cv = CountVectorizer()
data = cv.fit_transform(["life is short, i like python", "life is too long, i dislike python"])
print(cv.get_feature_names())
print(data.toarray())
return None
def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某种事物,你就不会真正了解它。了解事物真正含义的秘诀取决于如何将其与我们所了解的事物相联系。")
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def hanzivec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
cv = CountVectorizer()
data = cv.fit_transform([c1, c2, c3])
print(cv.get_feature_names())
print(data.toarray())
return None
if __name__ == "__main__":
countvec()
hanzivec()
运行结果示意图

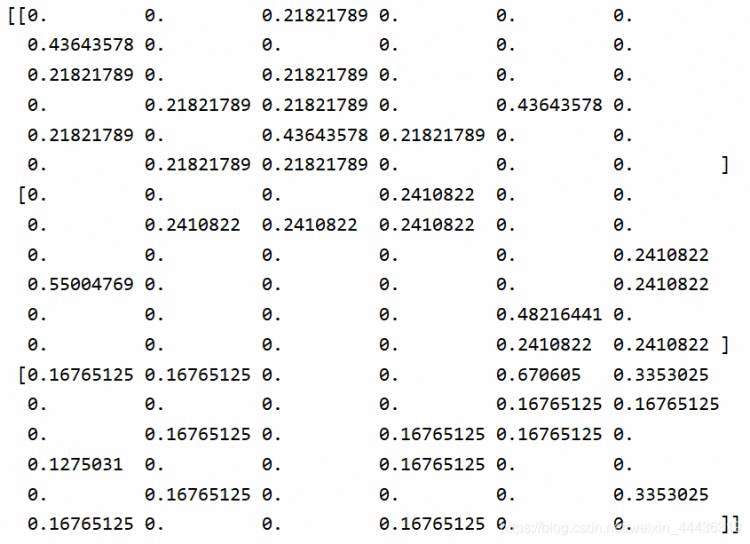
词的占比
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import jieba
def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某种事物,你就不会真正了解它。了解事物真正含义的秘诀取决于如何将其与我们所了解的事物相联系。")
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def tfidvec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
tf = TfidfVectorizer()
data = tf.fit_transform([c1, c2, c3])
print(tf.get_feature_names())
print(data.toarray())
return None
if __name__ == "__main__":
tfidvec()







 京公网安备 11010802041100号
京公网安备 11010802041100号