# 个人认为,这两个应该是同一个问题。
首先给大家推荐一个比较直观地搞懂L1和L2正则化的思考,有视频有图像,手动赞!
https://zhuanlan.zhihu.com/p/25707761
当然也推荐看看https://www.cnblogs.com/jclian91/p/9824310.html
回到问题,为什么L1正则化会有稀疏性?先盗个图。
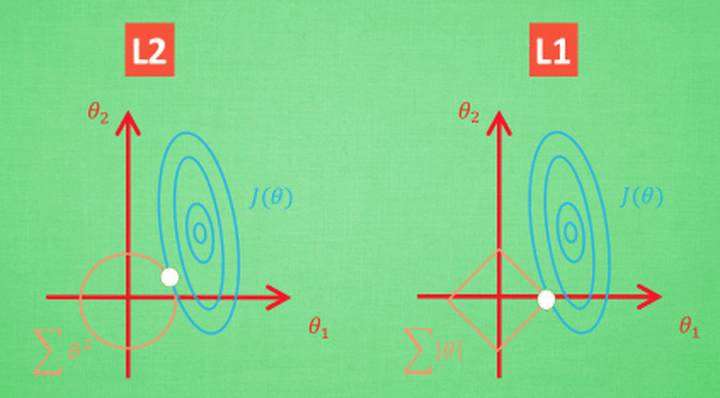
看右边那个图,可以发现L1正则化的黄色部分,其第一象限的斜率是固定的。要使得J(θ)在坐标轴之外的地方和L1正则化的框框相交,只有在J(θ)的长轴的斜率是-1的时候(为了方便说明,把J(θ)图像看做一个椭圆,可能只有两个参数的时候就是一个椭圆)。
不难发现,J(θ)的长轴的斜率是-1的情况是很少的,所以极大概率情况下他们的交点会存在于坐标轴上。对应有图也就是只有θ1发生做了作用。
说明:图中的情况虽然是为了说明,但并非特殊情况,其实黄色线条和蓝色线条相对位置绝大多是时候都是类似的。1、排除初始化为0的情况外,θ1和θ2不可能都为0;2、上面的那一段,长轴斜率是-1的概率很小。
在高维特征时,总之就是会出现很多正交来正交去的情况。可能出现上述链接中的例子:假设模型有100个系数,但是仅仅只有其中的10个是非零的,这实际上是说“其余的90个系数在预测目标值时都是无用的”。这10个特征就是我们所需要选择的特征。







![python的交互模式怎么输出名文汉字[python常见问题]](https://img1.php1.cn/3cd4a/24cea/978/9f39a0b333a15215.gif)



 京公网安备 11010802041100号
京公网安备 11010802041100号