点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
原文:https://medium.com/@urvashilluniya/why-data-normalization-is-necessary-for-machine-learning-models-681b65a05029
数据归一化常用于机器学习的预处理阶段,当数据集的特征间具有不同的值范围时,数据归一化是非常有必要的,数据归一化的目的是使特征具有相同的度量尺度。
比如数据集包含了两个特征,年龄(x1)和收入(x2)。年龄范围为0~100岁之间,收入范围为0~20000及以上,收入大约是年龄的1000倍。因此收入和年龄具有不同的范围,当对该数据构建多元线性回归模型时,收入对结果影响远远大于年龄的值,但是这和实际情况是不相符的,因为忽视了年龄对结果的影响。
为了进一步解释,我们构造两个神经网络模型:一个不使用归一化数据,另一个使用归一化数据,比较这两个模型的结果,并将展示归一化对模型准确性的影响。
原始数据集的前几行:
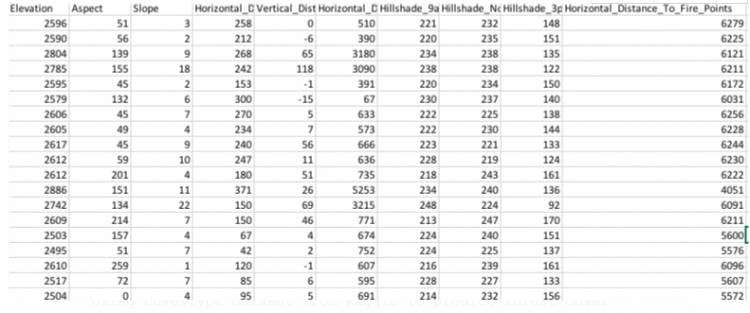
使用非归一化的原始数据集构建神经网络模型:
'''Using covertype dataset from kaggle to predict forest cover type'''
#Import pandas, tensorflow and keras
import pandas as pd
from sklearn.cross_validation import train_test_split
import tensorflow as tf
from tensorflow.python.data import Dataset
import keras
from keras.utils import to_categorical
from keras import models
from keras import layers
#Read the data from csv file
df = pd.read_csv('covtype.csv')
#Select predictors
x = df[df.columns[:54]]
#Target variable
y = df.Cover_Type
#Split data into train and test
x_train, x_test, y_train, y_test = train_test_split(x, y , train_size = 0.7, random_state = 90)
'''As y variable is multi class categorical variable, hence using softmax as activation function and sparse-categorical cross entropy as loss function.'''
model = keras.Sequential([keras.layers.Dense(64, activation=tf.nn.relu,input_shape=(x_train.shape[1],)),keras.layers.Dense(64, activation=tf.nn.relu),keras.layers.Dense(8, activation= 'softmax')])model.compile(optimizer=tf.train.AdamOptimizer(),loss='sparse_categorical_crossentropy',metrics=['accuracy'])
history1 = model.fit(x_train, y_train,epochs= 26, batch_size = 60,validation_data = (x_test, y_test))
输出结果为:
Output:
Epoch 1/26 406708/406708 [==============================]
- 19s 47us/step - loss: 8.2614 - acc: 0.4874 - val_loss: 8.2531 - val_acc: 0.4880
Epoch 2/26 406708/406708 [==============================]
- 18s 45us/step - loss: 8.2614 - acc: 0.4874 - val_loss: 8.2531 - val_acc: 0.4880
...............
Epoch 26/26 406708/406708 [==============================]
- 17s 42us/step - loss: 8.2614 - acc: 0.4874 - val_loss: 8.2531 - val_acc: 0.4880
模型的验证准确率仅仅为48.0%。
我们通过归一化数据集构建神经网络模型,通过对数据集去均值化以及将它缩放到单位方差来实现归一化。
数据集归一化代码:
from sklearn import preprocessingdf = pd.read_csv('covtype.csv')
x = df[df.columns[:55]]
y = df.Cover_Typex_train, x_test, y_train, y_test = train_test_split(x, y , train_size = 0.7, random_state = 90)#Select numerical columns which needs to be normalized
train_norm = x_train[x_train.columns[0:10]]
test_norm = x_test[x_test.columns[0:10]]# Normalize Training Data
std_scale = preprocessing.StandardScaler().fit(train_norm)
x_train_norm = std_scale.transform(train_norm)#Converting numpy array to dataframe
training_norm_col = pd.DataFrame(x_train_norm, index=train_norm.index, columns=train_norm.columns)
x_train.update(training_norm_col)
print (x_train.head())# Normalize Testing Data by using mean and SD of training set
x_test_norm = std_scale.transform(test_norm)
testing_norm_col = pd.DataFrame(x_test_norm, index=test_norm.index, columns=test_norm.columns)
x_test.update(testing_norm_col)
print (x_train.head())
归一化数据集的前5行数据:

使用归一化数据集构建神经网络模型:
#Build neural network model with normalized data
model = keras.Sequential([keras.layers.Dense(64, activation=tf.nn.relu,input_shape=(x_train.shape[1],)),keras.layers.Dense(64, activation=tf.nn.relu),keras.layers.Dense(8, activation= 'softmax')])model.compile(optimizer=tf.train.AdamOptimizer(),loss='sparse_categorical_crossentropy',metrics=['accuracy'])
history2 = model.fit(x_train, y_train,epochs= 26, batch_size = 60,
输出结果为:
#Output:
Train on 464809 samples, validate on 116203 samples
Epoch 1/26 464809/464809 [==============================]
- 16s 34us/step - loss: 0.5433 - acc: 0.7675 - val_loss: 0.4701 - val_acc: 0.8022
Epoch 2/26 464809/464809 [==============================]
- 16s 34us/step - loss: 0.4436 - acc: 0.8113 - val_loss: 0.4410 - val_acc: 0.8124 Epoch 3/26
....................
Epoch 26/26 464809/464809 [==============================]
- 16s 34us/step - loss: 0.2703 - acc: 0.8907 - val_loss: 0.2773 - val_acc: 0.8893
模型验证集的准确率达到了88.9%,远比非归一化数据集构建的模型要好。
用图比较两个模型:
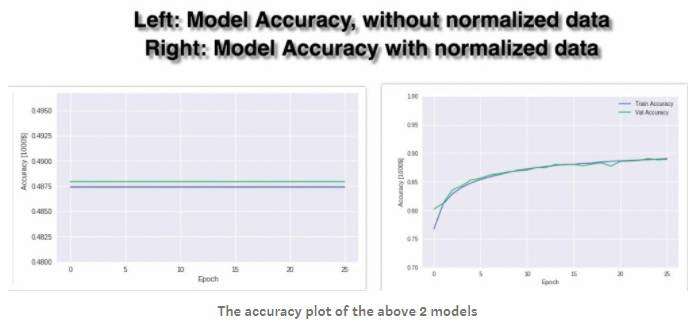
结果:由上面图标可知,模型1(左1)由很低的验证准确率(48%),当迭代次数增加时,模型的训练准确率和验证准确率均没有提高,模型2(右1)的训练准确率和验证准确率随着迭代次数的增加均有一定程度的提高。
原因分析:若特征间具有不同的值范围时,因此梯度更新时,会来回震荡,经过较长的时间才能达到局部最优值或全局最优值。为了解决该模型问题,我们需要归一化数据,我们确保不同的特征具有相同的值范围,这样梯度下降可以很快的收敛。从右1的图表可知,准确率随着迭代次数的增加而提高,当迭代次数为26时,准确率达到了88.93%。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python+OpenCV视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:Pytorch常用函数手册
在「小白学视觉」公众号后台回复:pytorch常用函数手册,即可下载含有200余个Pytorch常用函数的使用方式,帮助快速入门深度学习。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~


![Python函数的高级用法[python基础]](https://img1.php1.cn/3cdc5/324f/339/3af2ae9e74cbfcbe.jpeg)



 京公网安备 11010802041100号
京公网安备 11010802041100号