时下,我们正处于一个日新月异的时代,而优秀应用的响应时间往往需要被控制在0.1秒内。这也意味着,如果可接受网络通信时间为50毫秒,那么开发者必须在剩余的50毫秒内处理数据并进行响应。要实现这一点毫无疑问会需求毫秒级的数据库响应时间,在同时支撑上万个请求的场景中更是如此,而这样的需求当下只有少数几个灵活度极高、功能齐全的数据库才能满足。
在大数据处理情景中,洞见必须被快速收集并做出决策,而在没有复杂优化或折中的情况下,内存数据库可以在数秒内完成以往传统数据库数小时或者数分钟的工作。尽管如此,当下在内存数据库领域仍然存在诸多流言,大量人仍然认为内存数据库不可靠性、不一致并且伴随着昂贵的开销。然而最重要的是,还有人认为只要把数据库放到内存中就可以获得所需的性能。
答案显然是否定的。即使当下大部分内存数据库都使用非常高效的语言编写,比如 C 和 C++,但是它们仍然无法得到所需的响应需求,这主要基于以下几点原因:
1. 在不同数据库中,处理命令的复杂性是不同的。在高性能数据库中,处理命令会在最小复杂度下执行。最直接的影响就是就是,在数据集不断增大的情况下,你可能需要一直优化查询时间。
2. 查询效率同样不同。有些时候,数据库会把全部加载进内存的数据当做单一的 BLOB(类似 memcached 的缓存机制),这显然是没有效率的——数据库应该具备分散存储和查询值的能力,以及有效地节约网络和内存开销,从而显著地降低应用程序处理时间。
3. 单线程和多线程架构的权衡。
多线程会尽可能的利用计算能力,无需数据库用户做任何处理,但是这个解决方案同样需要做大量的内部管理和同步,从而消耗大量的计算资源。在多线程模式下,锁开销可能会大幅度降低数据库性能。
单线程使用了一个非常简单的执行模型,在这个解决方案中不存在锁的问题,同时也只会耗费少许的计算性能,但毫无疑问的是,计算资源的管理将从数据库移交给用户。理想的解决方案肯定是让用户尽可能少地做资源管理,因为数据库管理本来就是个轻度资源密集型工作。
4. 零共享 vs. 共享 vs. 共享一切。共享会影响到系统的扩展性。在数据库体积不断增长的同时,性能也必须时刻满足实例的需求。零共享模型让所有实体都以独立单元的形式存在,从而避免了处理暴增后的通信开销,实现线性扩展能力。
5. 通过避免网络方面任务和减少 TCP 协议开销, 零延时分布式代理等内置加速组件可以显著地提升数据库性能。在某些情况下,代理也可能与数据库通信,以确定其是否作为主机上服务远程客户端的另一个本地客户端进程。
如果吞吐量和延时是主要目标,那么机构很显然需要选择一个可以实现毫秒级延时并最小化服务器需求的数据库。
大多数 NoSQL 数据库(不只是内存数据库)在提交数据到磁盘或者副本之前都为客户端提供了 acknowledgements (ack)。因此,这里很可能会造成数据不一致的情况。
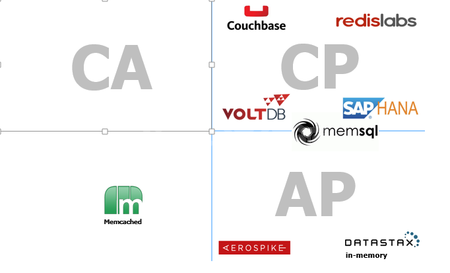
CAP 定理标明任何分布式计算机系统都不能同时具备一致性、可用性和分区容错性。不同的数据库会选择不同的类型,具体情形如下:选择 CP 模型表示开发者不用去关心一致性,但是在网络分割事件中写命令则是不允许的。如果选择 AP 模型则意味着数据库对读写一直可用,但是开发者在写应用程序代码时就需要考虑一致性问题,而不是期望数据库去完成这个操作。因此,请根据使用场景来选择合适的数据库模型。
扩展共有两个途径。首先通过给托管数据库的服务器纵向扩展,比如增加更多的 CPU 和内存;其次,通过向内存集群中添加更多的主机实现横向扩展。在许多数据库中,你可以在同一个节点上运行同一个数据集的多个分片,因此可以通过更有效率的计算资源利用来延缓扩展需求。同样,这里也可以将多个服务器的内存整合起来成为一个共享内存池,从而突破单机内存大小限制。现下,很多内存数据库同时允许这两种方法的扩展,通过动态的增加分配给数据库的核心和内存节点数量来最大化应用程序的响应能力。
任何需要快速提升吞吐量的应用都面临着相同的问题:「一定等级的吞吐量究竟需要花多少钱」。举个例子,在1500万 OPS 情景下,运行在单 Amazon EC2 实例上的内存数据库会比非内存数据库便宜,但是如果使用数百台服务器达到同样的效果结果可能就会截然相反。
如果数据集规模是 TB 级别,内存的花费很显然会成为问题,然而当下已经有使用闪存扩展内存的技术存在,从而降低花费。但需要注意的是,使用闪存来扩展内存势必会影响到系统性能,因此这里理想的技术是控制闪存和内存的比例以达到一个理想的性价比。
综上所述,根据实际场景来选择合适的数据库技术将会大幅度提高资源利用效率。同时,新型数据库出现已有很长一段时间,因此抛弃不必要的成见才能让工作事半功倍。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 