elasticsearch 是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域
日志可视化:项目在运行时会产生海量的日志,日志可以方便我们定位BUG。而ELK可以将日志可视化进行展示,从而方便了找出BUG.
实时监控:项目运行过程中的状态也是数据,cup、内存、访问情况等等。

Lucene是一个JAVA语言的搜索引擎类库,是Apache公司的顶级项目,由1999年开发。官网地址https://lucene.apache.rog/
类库:就是一个jar包
Lucene的优势:
Lucene的缺点:
相比lucene,elasticsearch具备的优点是:
elasticsearch:开源的分布式搜索引擎
什么是正向索引:
基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条。
什么是倒排索引:
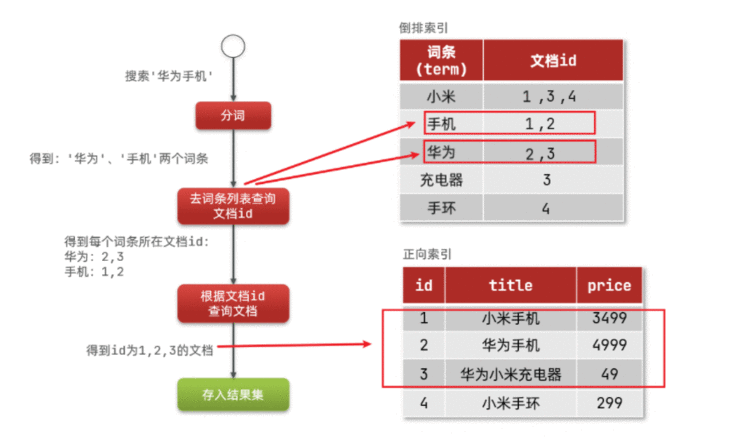
对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档。
倒排索引是基于传统数据库正向索引对比得出的:倒排索引。
例如:
mysql的正向索引:基于id创建索引,形成B+树,根据id进行检索的速度非常快。
如果是搜索的不是id,而是一个词语,一段话。如果正向搜索进行局部内容检索,通过模糊查询,效率很低。
ES的倒排索引:在创建的时候,会形成一个新的表格,有两个字段一个是词条,一个文档id。
文档(document):每条数据就是一个文档。
词条(term):文档按照语义分成的词语。【具有唯一性】
那么倒排文档在存储时,会先把文档内容分成词条进行存储。例如小米手机。分成:词条是:小米、手机。文档id:都是1

词条term字段是不会重复的,因为是唯一的,就可以创建索引,数据较少可以使用hash法,也可以使用B+树,为词条创建唯一索引。
例如搜索:华为手机。
第一步:会先将“华为手机”内容进行分词,从而得到“华为”和“手机”这样的词条。
第二步:拿着这两个词条,去倒排索引中,进行查询。
第三步:就能查到相应的词条所对应的文档id。在找出关联度最高的文档,进行排序。
第四步:根据文档id,查询文档。由于是拿着具体id来进行正向索引,索引可以快速得到文档了。
第五步:将结果,放到结果集当中。
一共经历了两次检索:
一次是根据词条去词条列表找文档id。
根据文档id找文档
索然是两次检索,但是每次都是根据索引进行查询。效率是非常的高。

例如:

数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束.

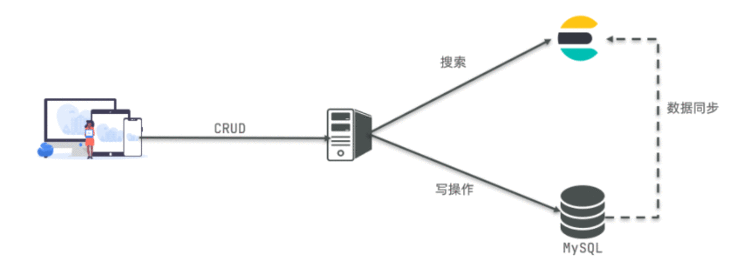
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
//启动:
systemctl start docker
//检查是否启动成功:
docker -v
//查看docker的镜像:
docker images
//查看启动后的容器:
docker ps
//删除容器:
docker stop es
docker rm es
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
这里我们采用elasticsearch的7.12.1版本的镜像,这个镜像体积非常大,接近1G。不建议大家自己pull。
建议将下载好的安装包.tar文件,将其上传到虚拟机中,然后运行命令加载即可:
# 导入数据
docker load -i es.tar
同理还有kibana的tar包也需要这样做。
运行docker命令,部署单点es:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
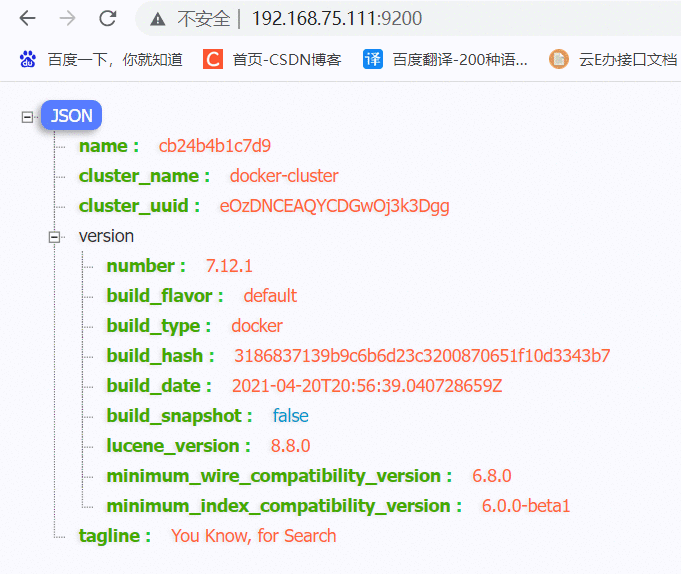
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net :加入一个名为es-net的网络中-p 9200:9200:端口映射配置在浏览器中输入:http://192.168.150.101:9200 即可看到elasticsearch的响应结果:
docker load -i kibana.tar
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置此时,在浏览器输入地址访问:http://192.168.150.101:5601,即可看到结果
ES在创建倒排索引时,需要对文档内容进行分词。
搜索时,需要对内容输入,进行分词
# 进入容器内部
docker exec -it elasticsearch /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit
#重启容器
docker restart elasticsearch
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
显示结果:
[{"CreatedAt": "2022-05-06T10:06:34+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]
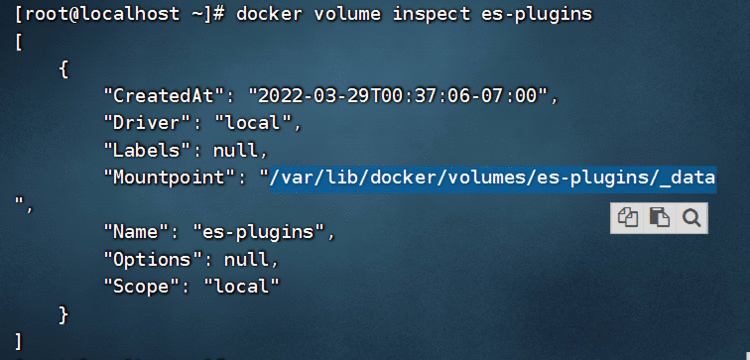
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data这个目录中。
下面我们需要把课前资料中的ik分词器解压缩,重命名为ik
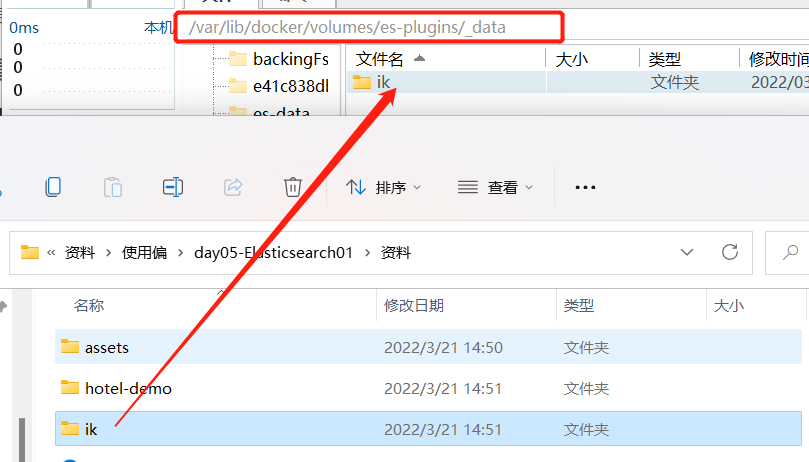
也就是/var/lib/docker/volumes/es-plugins/_data:
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es
IK分词器包含两种模式:
ik_smart:最少切分
ik_max_word:最细切分
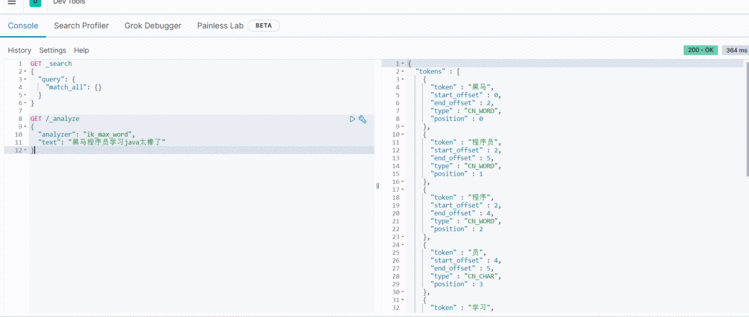
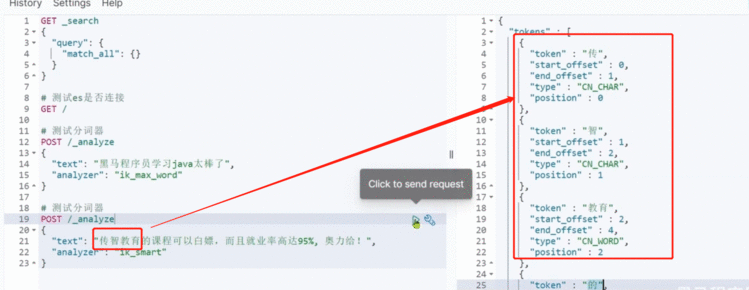
GET /_analyze
{"analyzer": "ik_max_word","text": "黑马程序员学习java太棒了"
}
结果:
{"tokens" : [{"token" : "黑马","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "程序员","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 1},{"token" : "程序","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 2},{"token" : "员","start_offset" : 4,"end_offset" : 5,"type" : "CN_CHAR","position" : 3},{"token" : "学习","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 4},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "ENGLISH","position" : 5},{"token" : "太棒了","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 6},{"token" : "太棒","start_offset" : 11,"end_offset" : 13,"type" : "CN_WORD","position" : 7},{"token" : "了","start_offset" : 13,"end_offset" : 14,"type" : "CN_CHAR","position" : 8}]
}
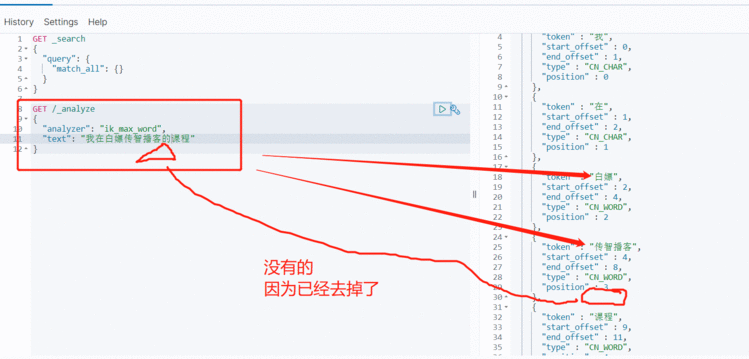
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“传智播客” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
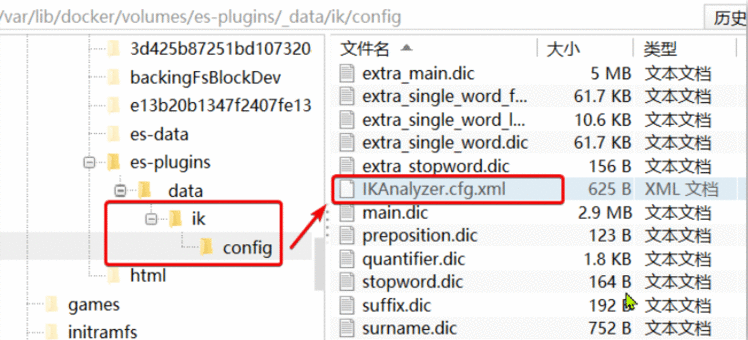
2)在IKAnalyzer.cfg.xml配置文件内容添加:
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置comment><entry key&#61;"ext_dict">ext.dicentry><entry key&#61;"ext_stopwords">stopword.dicentry>
properties>
3&#xff09;新建一个 ext.dic&#xff0c;可以参考config目录下复制一个配置文件进行修改
传智播客
奥力给
4&#xff09;重启elasticsearch
docker restart es# 查看 日志
docker logs -f elasticsearch
分词器的作用是什么&#xff1f;
IK分词器有几种模式&#xff1f;
IK分词器如何拓展词条&#xff1f;如何停用词条&#xff1f;
索引库就类似数据库表&#xff0c;mapping映射就类似表的结构。
我们要向es中存储数据&#xff0c;必须先创建“库”和“表”。
mapping是对索引库中文档的约束&#xff0c;常见的mapping属性包括&#xff1a;
例如下面的json文档&#xff1a;
{"age": 21,"weight": 52.1,"isMarried": false,"info": "黑马程序员Java讲师","email": "zy&#64;itcast.cn","score": [99.1, 99.5, 98.9],"name": {"firstName": "云","lastName": "赵"}
}
对应的每个字段映射&#xff08;mapping&#xff09;&#xff1a;
这里我们统一使用Kibana编写DSL的方式来演示。
格式&#xff1a;
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
PUT /heima
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"email":{"type": "keyword","index": "falsae"},"name":{"properties": {"firstName": {"type": "keyword"}}},// ... 略}}
}
基本语法&#xff1a;
请求方式&#xff1a;GET
请求路径&#xff1a;/索引库名
请求参数&#xff1a;无
格式&#xff1a;
GET /索引库名
示例&#xff1a;

倒排索引结构虽然不复杂&#xff0c;但是一旦数据结构改变&#xff08;比如改变了分词器&#xff09;&#xff0c;就需要重新创建倒排索引&#xff0c;这简直是灾难。因此索引库一旦创建&#xff0c;无法修改mapping。
虽然无法修改mapping中已有的字段&#xff0c;但是却允许添加新的字段到mapping中&#xff0c;因为不会对倒排索引产生影响。
语法说明&#xff1a;
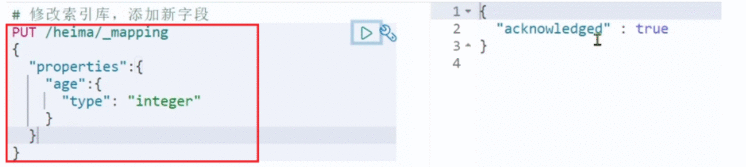
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
示例&#xff1a;
语法&#xff1a;
请求方式&#xff1a;DELETE
请求路径&#xff1a;/索引库名
请求参数&#xff1a;无
格式&#xff1a;
DELETE /索引库名
在kibana中测试&#xff1a; 
索引库操作有哪些&#xff1f;
语法&#xff1a;
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}
示例&#xff1a;
POST /heima/_doc/1
{"info": "黑马程序员Java讲师","email": "zy&#64;itcast.cn","name": {"firstName": "云","lastName": "赵"}
}
响应&#xff1a;
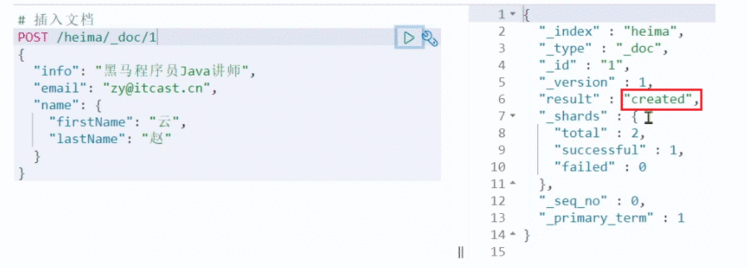
根据rest风格&#xff0c;新增是post&#xff0c;查询应该是get&#xff0c;不过查询一般都需要条件&#xff0c;这里我们把文档id带上。
语法&#xff1a;
GET /{索引库名称}/_doc/{id}
通过kibana查看数据&#xff1a;
GET /heima/_doc/1
查看结果&#xff1a;
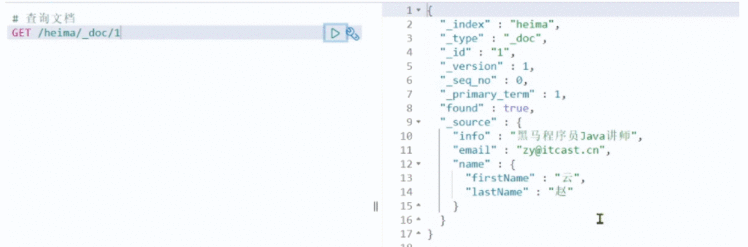
删除使用DELETE请求&#xff0c;同样&#xff0c;需要根据id进行删除&#xff1a;
语法&#xff1a;
DELETE /{索引库名}/_doc/id值
示例&#xff1a;
# 根据id删除数据
DELETE /heima/_doc/1
结果&#xff1a;
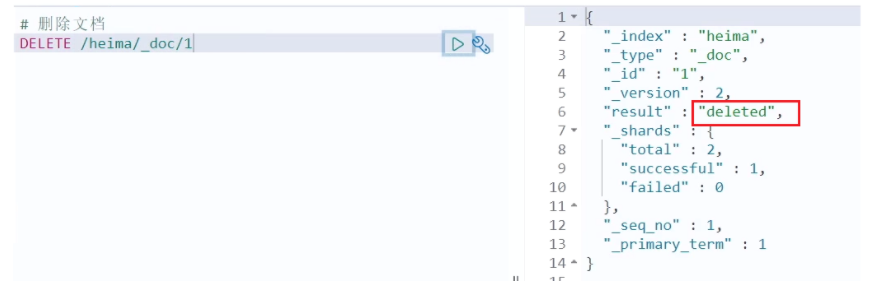
修改有两种方式&#xff1a;
全量修改是覆盖原来的文档&#xff0c;其本质是&#xff1a;
注意&#xff1a;如果根据id删除时&#xff0c;id不存在&#xff0c;第二步的新增也会执行&#xff0c;也就从修改变成了新增操作了。
语法&#xff1a;
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}
示例&#xff1a;
PUT /heima/_doc/1
{"info": "黑马程序员高级Java讲师","email": "zy&#64;itcast.cn","name": {"firstName": "云","lastName": "赵"}
}
增量修改是只修改指定id匹配的文档中的部分字段。
语法&#xff1a;
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}
示例&#xff1a;
POST /heima/_update/1
{"doc": {"email": "ZhaoYun&#64;itcast.cn"}
}
文档操作有哪些&#xff1f;




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有