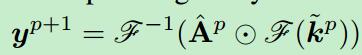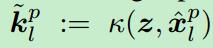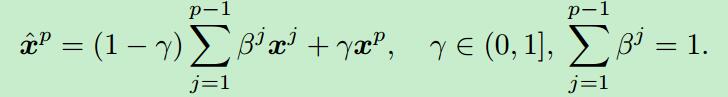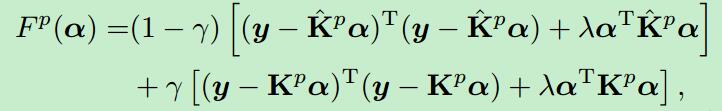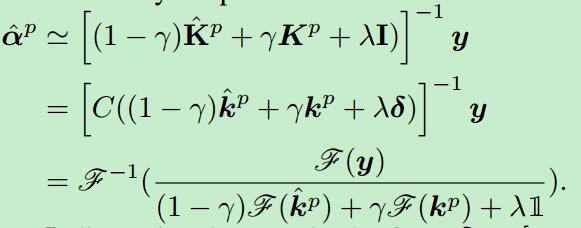文章主要关注是在视觉跟踪领域中的模板更新的问题,至于计算方面,也是利用的相关滤波保证较高的FPS,它提到,一般的更新方式有一个策略,参见KCF的模板更新公式,这当中有一个重要的参数,表示的是在跟踪的适应性和稳定性之间做的一个平衡,这样会导致一个问题,即对于那些我们得到的比较好的样本(每帧之间目标和形变都比较小),经过长时间的跟踪时候,在模型中逐渐失去效用,因为它的更新是指数级的,在大约100帧之后,基本没有用了,大概也就4秒的样子,对于长时间跟踪来说,这是一个问题。于是作者提出“可靠记忆”这种“聚类”方法。他认为,在平滑的运动中物体外形实际上的形变很小,那么外观上提供的特征是相似的,基于这一点,作者认为这几帧图像可以当做是我们的“reliable memories”,我们在识别下一帧的时候,用的公式是
其中,y(p+1)就是相应图(response map),
z是当前帧的输入图像,x(l)是学习到的外观。而样本更新中的x(p+1)的公式是
等式左边的就是依据过去的样本和当前的样本进行加权求和形成新的模型,又定义了一个损失函数
对这个公式中的a求偏导,使之为0,得到
它把样本分成好多个子集,每个子集中的样本是高度相关的,不同子集的样本的相差很大,
怎么做的?
有两个特征池,一个是对于正样本的,一个是对于记忆的,,每一个记忆包含一系列的样本和一个系数,一个记忆当中的样本数如果越多就越可靠,也越不会被累计的漂移误差所影响,每来新的一帧,首先估计目标的位置,然后利用这个心的样本来更新我们的外观模型和前面的那个系数,,然后计算每一个样本前面的系数并归一化,






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有