作者:丨火云邪神丨 | 来源:互联网 | 2023-09-25 20:02

论文地址:http://arxiv.org/abs/2202.07800
项目地址:https://github.com/youweiliang/evit
在这项工作中,作者在 ViT 模型的前馈过程中重新组织图像标记,在训练期间将其集成到 ViT 中。由相应的类令牌注意力引导识别 MHSA 和 FFN(即前馈网络)模块之间的注意力图像令牌,然后,通过保留注意图像标记和融合非注意图像标记来重组图像标记,以加快后续的 MHSA 和 FFN 计算。
在相同数量的输入图像标记下,该方法减少了 MHSA 和 FFN 计算以实现高效推理。例如,在 ImageNet 分类任务中,DeiT-S的推理速度提高了 50%,而识别准确率仅下降了 0.3%。另外,在保持相同的计算成本的情况下,该方法使 ViT 能够将更多的图像标记作为识别精度提高的输入(更高分辨率的图像),在与普通 DeiT-S 相同的计算成本的情况下,将 DeiT-S 的 ImageNet 分类识别精度提高了 1%,同时也没有引入更多的参数。
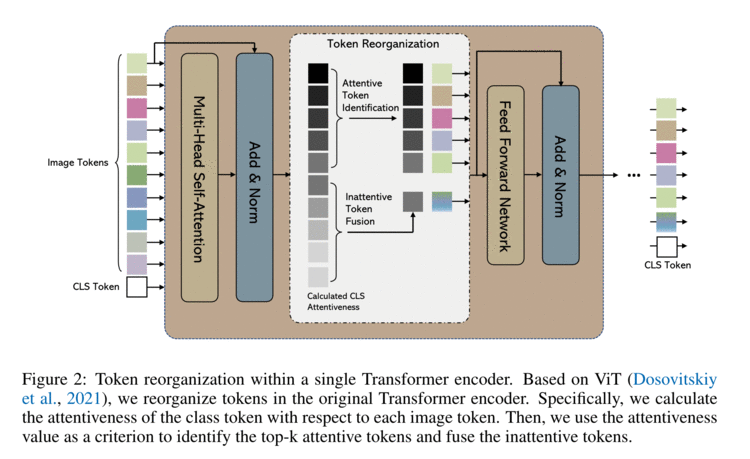
注意标记识别(Attentive Token Identification)
通过计算每个token的所有Heads的平均注意力值作为该token的注意力值(如下列公式),之后识别出k个注意力值最大的tokens作为Attentive Tokens直接保留至下一阶段,而其他的inattentive tokens则被融合为一个新的token。

非注意标记融合(Inattentive Token Fusion)
尽管背景标记的信息量较少并且可以被丢弃而不会显着影响 ViT 模型的性能,但仍然可能有助于预测结果。另外,一些图像的目标对象可能具有占据图像的大部分区域。因此,当选择固定数量的令牌保留在 ViT 编码器中时,可能会删除一些包含有图像信息的令牌会对图像识别性能产生负面影响。
融合 inattentive tokens 来补充 attentive tokens(如图 2 所示)有利于保留由 inattentive tokens 提供的部分信息。
具体来说,非注意标记融合是一种对 inattentive tokens的加权平均操作(如下列公式)。

融合后的非注意标记被附加到保留的注意标记后发送到后续层。与 ViT 的计算量相比,非注意标记融合的计算成本可以忽略不计。
个人总结
这篇文章是2022年的一篇文章,但是感觉整个机制十分地简单粗暴,就是计算注意力分数然后取top-k的token,再把剩余token融合成1个token。根据k的大小不同,可以节省不同比例的计算量。图像的信息冗余性本身就比较大,因此这种方式如果k取比较合适的值,应当可以取得文章中的效果。










 京公网安备 11010802041100号
京公网安备 11010802041100号