作者:ex7776647 | 来源:互联网 | 2023-08-29 08:35
上一篇文章介绍了图和图数据库的一些基本概念,本篇将介绍一下目前比较流程的图数据库Titan的概念及架构.
什么是Titan
Titan是一个可以灵活扩展的分布式图数据库,它通过一个多机集群来存储和查询上千亿的点和边信息。Titan也是一个事务型数据库, 他可以支持多上千个用户同时并发的执行复杂的图遍历。
Titan特征
作为一个优秀的图数据库,Titan有如下一些区别与其他Graph Database的特征
支持数据以及用户的弹性线性增长
用于性能和容错的数据分发和复制
多数据中心高可用和热备份机制
支持ACID和最终一致性
支持多种类型的底层存储
Apache Cassandra
Apache HBase
Oracle BerkeleyDB
通过与大数据平台集成,支持全球图形数据分析,数据报告和数据ETL
Apache Spark
Apache Giraph
Apache Hadoop
通过以下方式支持地理位置,数值范围和全文搜索
ElasticSearch
Solr
Lucene
本地集成TinkerPop 图技术栈
Gremlin graph query language
Gremlin graph server
Gremlin applications
支持Apache2开源协议
Titan与CAP
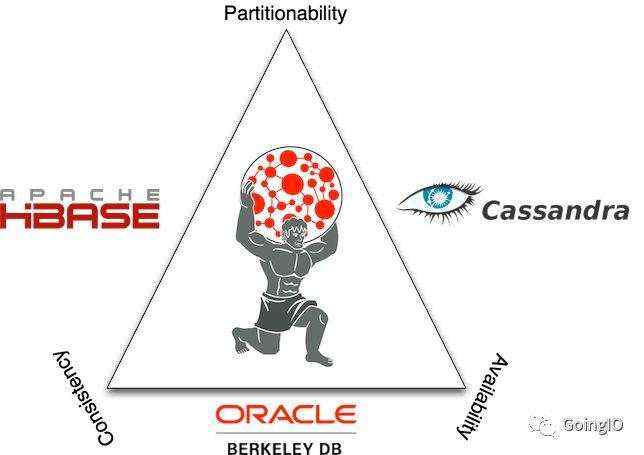
作为一个数据库, CAP理论是必须要考虑的。Titan通过与Hbase, Cassandra以及Oracle Berkeley DB结合,其CAP权衡如上图展示。 Berkeley DB并不是分布式数据库,可以满足高可用及高一致性,但是无法做到分区容错,所以只用在测试环境。
Titan 架构
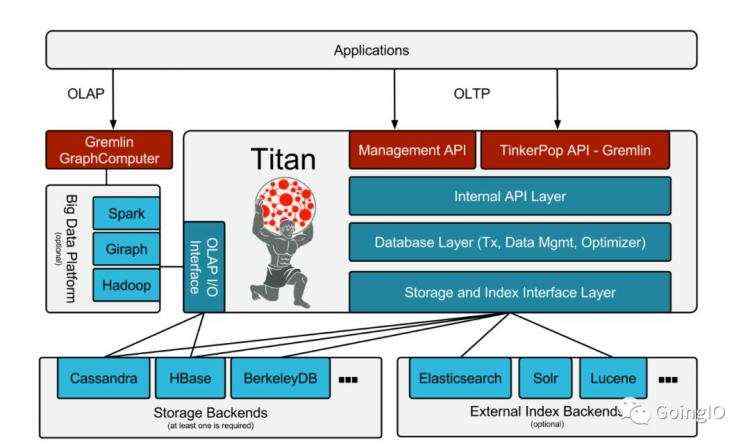
前面我们也提到过,任务一个图数据库,都包含俩个重要的部分, 一个是图存储引擎,一个是图搜索引擎。Titan作为一个图数据库引擎,主要功能集中在图序列化,图数据模型以及高效的图搜索,Titan利用hadoop等大数据框架来完成图的分析及批量图处理, 同时, Titan为数据持久性,数据索引和客户端访问实现了强大的模块化接口。








 京公网安备 11010802041100号
京公网安备 11010802041100号