
作者 | 赵志、曾庆隆、顾梦奇、王强、赵发
出品 | CSDN(ID:CSDNnews)
2019 年 3 月 25 日,苹果发布了 Swift 5.0 版本,宣布了 ABI 稳定,并且Swift runtime 和标准库已经植入系统中,而且苹果新出文档都用 Swift,Sample Code 也是 Swift,可以看出 Swift 是苹果扶持与研发的重点方向。
目前国内外各大公司都在相继试水,只要关注 Swift 在国内 iOS 生态圈现状,你就会发现,Swift 在国内 App 应用的比重逐渐升高。对于新 App 来说,可以直接用纯 Swift 进行开发,而对于老 App 来说,绝大部分以前都是用 OC 开发的,因此 Swift/OC 混编是一个必然面临的问题。

CSDN 付费下载自视觉中国

Swift 和 OC 混编开发
关于 Swift 和 OC 间如何混编,业内也已经有很多相关文章详细讲解,简单来说 OC/Swift 调用 Swift,最终通过 Swift Module 进行,而 Swift 调用 OC 时,则是通过 Clang Module,当然也可以通过 Clang Module 进行 OC 对 OC 的调用。58同城于 2020 年正式上线首个 Swift/OC(Objective-C,以下简称 OC)项目,与此同时,也在全公司范围内开展了一个多部门协作项目——混天项目,主要目标:
一是提供混编的基础设施建设,如提供通过的 Module 化方案;
二是扩展各工具链的混编能力,如对无用类检测工具 WBBlades(https://github.com/wuba/WBBlades)进行 Swift 能力的扩展;
三是对已有的基础库进行 Module 化和 Swift 适配;
四是将混编开发在各 App 和各业务线中推广和落地。
我们在 Module 化实践中发现,实际数据与苹果官方 Module 编译时间数据不一致,于是我们通过 Clang 源码和数据相结合的方式对 Clang Module 进行了深入研究,找到了耗时的原因。由于 Swift/OC 混编下需要 Module 化的支持,同时借鉴业内 HeaderMap 方案让 OC 调用 OC 时避开 Module 化调用,将编译时间优化了约 35%,较好地解决了在 Module 化下的编译时间问题。

Clang Module 在 2012 LLVM Developers Meeting 上第一次被提出,主要用来解决 C 语言预处理的各种问题。Modules 试图通过隔离特定库的接口并且编译一次生成高效的序列化文件来避免 C 预处理器重复解析 Header 的问题。在探究 Clang Module 之前,我们先了解一下预处理的前世今生。
一个源代码文件到经过编译输出为目标文件主要分为下面几个阶段:

源文件在经过 Clang 前端包含:词法分析(Lexical analysis) 、语法分析(Syntactic analysis) 、语义分析(Semantic analysis)。最后输出与平台无关的 IR(LLVM IR generator)进而交给后端进行优化生成汇编输出目标文件。
词法分析(Lexical analysis)作为前端的第一个步骤负责处理源代码的文本输入,具体步骤就是将语言结构拆分为一组单词和记号(token),跳过注释,空格等无意义的字符,并将一些保留关键字转义为定义好的类型。词法分析过程中遇到源代码 “#“ 的字符,且该字符在源代码行的起始位置,则认为它是一个预处理指令,会调用预处理器(Preprocessor)处理后续。在开发中引入外部文件的 include/import 指令,定义宏 define 等指令均是在预处理阶段交由预处理器进行处理。Clang Module 机制的引入带来的改变着重于解决常规预处理阶段的问题,那么跟随我们一起来重点探究一下其中的区别和实现原理吧!
Clang Module 机制引入之前,在日常开发中,如果需要在源代码中引入外部的一些定义或者声明,常见的做法就是使用 #import 指令来使用外部的 API。那么这些使用的方式在预处理阶段是怎么处理的呢?
针对编译器遇到 #import
或者 #import ”header.h” 这种导入方式时候,# 开头在词法分析阶段会触发预处理(Preprocessor)。而对于 Clang 的预处理器 import 与 include 指令都属于它的关键词。预处理器在处理 import Directive 时候主要工作为通过导入的 header 名称去查找文件的磁盘所在路径,然后进入该文件创建新的词法分析器对导入的头文件进行词法分析。
如下所示:编译器在遇到 #import 或者 #include 指令时,触发预处理机制查询头文件的路径,进入头文件对头文件的内容进行解析的流程。
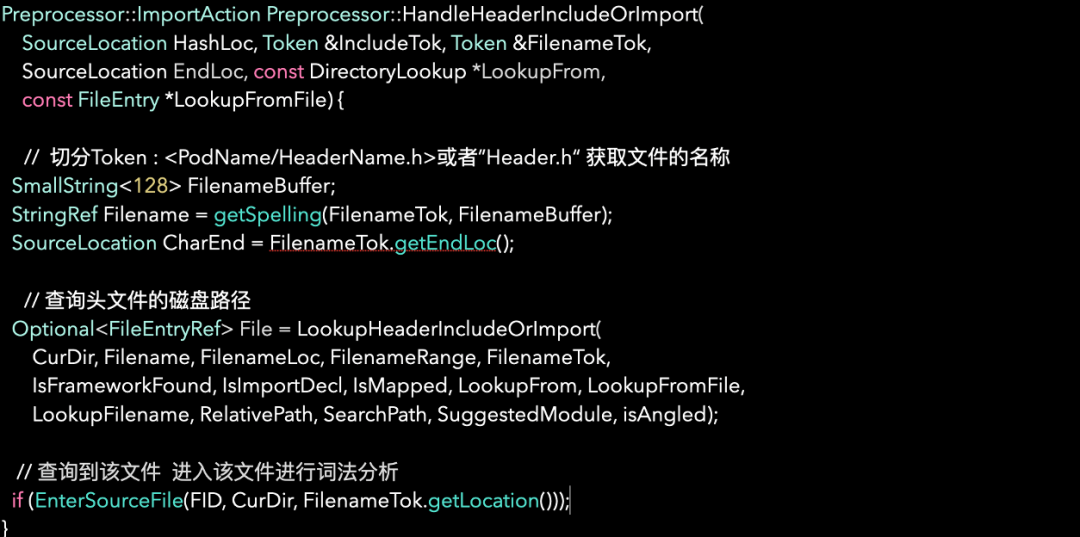
以单个文件编译过程为维度举例:在针对一个文件编译输出目标文件的过程中,可能会引入多个外界的头文件,而被引入多个外界头文件也有可能存在引入外界头文件。这样的情况就导致虽然只是在编译单个文件,但是预处理器会对引入的头文件进行层层展开。这也是很多人称 #import 与 include 是一种特殊“复制”效果的原因。
那么在这种预处理器的机制在工程中编译中会存在什么问题呢?苹果官方在 2012 的 WWDC 视频上同样给了我们解答:Header Fragility (健壮性)和 Inherently Non-Scalable (不可扩展性)。
来看下面一段代码,在 PodBTestObj 类的文件中定义一个 ClassName 字符串的宏,然后在导入 PoBClass1.h 头文件,在 PoBClass1.h 的头文件中同样定义一个结构体名为 ClassName,这里与我们在 PodBTestObj 类中定义的宏同名。预处理的特殊的“复制”机制,在预处理阶段会发生下图所见的结果:

这样的问题相信在日常开发中并不罕见,而为了解决这种重名的问题,我们常规的手法只能通过增加前缀或者提前约定规则等方式来解决。
视频中同时指出这种机制在应对大型工程编译过程中的所带来的消耗问题。假设有 N 个源文件的工程,那么每个源文件引用 M 个头文件,由于预处理的这种机制,我们在针对处理每个源文件的编译过程中会对引入的 M 个头文件进行展开,经历一遍遍的词法分析-语法分析-语义分析的过程。那么你能想象一下针对系统头文件的引入在预处理阶段将会是一个多么庞大的开销!

那么针对 C 语言预处理器存在的问题,苹果有哪些方案可以优化这些存在的问题呢?
PCH(Precompile Prefix Header File)文件,也就是预编译头文件,其文件里的内容能被项目中的其他所有源文件访问。日常开发中,通常放一些通用的宏和头文件,方便编写代码,提高效率。
关于 PCH 的概述,苹果是这样定义的:
which uses a serialized representation of Clang’s internal data structures, encoded with the LLVM bitstream format.
(使用 Clang 内部数据结构序列化表示,采用的 LLVM 字节流表示)。
它的设计理念当项目中几乎每个源文件中都包含一组通用的头文件时,将该组头文件写入 PCH 文件中。在编译项目中的流程中,每个源文件的处理都会首先去加载 PCH 文件的内容,所以一旦 PCH 编译完成,后续源文件在处理引入的外部文件时候会复用 PCH 编译后的内容,从而加快编译速度。PCH 文件中存放我们所需要的外部头文件的信息(包括不局限于声明、定义等)。它以特殊二进制形式进行存储,而在每个源代码编译处理外部头文件信息时候,不需要每次进行头文件的展开和“复制”重复操作。而只需要“懒加载”预编译好的 PCH 内容即可。
存储内容方面它存放着序列化的 AST 文件。AST 文件本身包含 Clang 的抽象语法树和支持数据结构的序列化表示,它们使用与 LLVM’s bitcode file format. 相同的压缩位流进行存储。关于 AST File 文件的存储结构你可以在官方文档有详细的了解。
它作为苹果一种优化方案被提出,但是实际的工程中源代码的引用关系是很复杂的,所以找出一组几乎所有源文件都包含的头文件基本不可能,同时对于代码更新维护更是一个挑战。其次在被包含头文件改动下,因为 PCH 会被所有源文件引入,会带来代码“污染”的问题。同时一旦 PCH 文件发生改动,会导致大面积的源代码重编造成编译时间的浪费。
上述我们简单回顾了一些 C 语言预处理的机制以及为解决编译消耗引入 PCH 的方案,但是在一定程度上 PCH 方案也存在很大的缺陷。因此在 2012 LLVM Developer’s Meeting 首次提出了 Modules 的概念。
那么 Module 到底是什么呢?

Module 简单来说可以认为它是对一个组件的抽象描述,包含组件的接口和实现。Module 机制推出主要用来解决上述所阐述的预处理问题,想要探究 Clang Module 的实现,首先需要去开启 Module。那么针对 iOS 工程怎么开启 Module 呢? 只需要打开编译选项中:

对!你没看错,仅仅需要在 Xcode 的编译选项中修改配置即可。
而在代码的使用上几乎可以不用修改代码,开启 Module 之后,通过引用头文件的方式可以继续沿用 #import
方式。当然对于开发者也可以采用新的方式 @import ModuleName.SubModuleName,以及 @import ModuleName这几种方式。更为详细的信息和使用方法可以在苹果的官方文档中查看。
上文提到过基于 C 语言预处理器提供的 #include 机制提供的访问外界库 API 的方式存在的伸缩性和健壮性的问题。Modules 提供了更为健壮,更高效的语义模型来替换之前 textual preprocessor 改进对库的 API 访问方式。
苹果官方文档中针对 Module 的解读有以下几个优势:
扩展性:每个 Module 只会编译一次,将 Module 导入 Translantion unit 的时间是恒定的。对于库 API 的访问只会解析一次,将 #include 的机制下的由 M x N 编译问题简化为 M + N。
健壮性:每个 Module 作为一个独立的实体,具备一个一致的预处理环境。不需要去添加下划线,或者前缀等方式解决命名的问题。每个库不会影响另外一个库的编译方式。
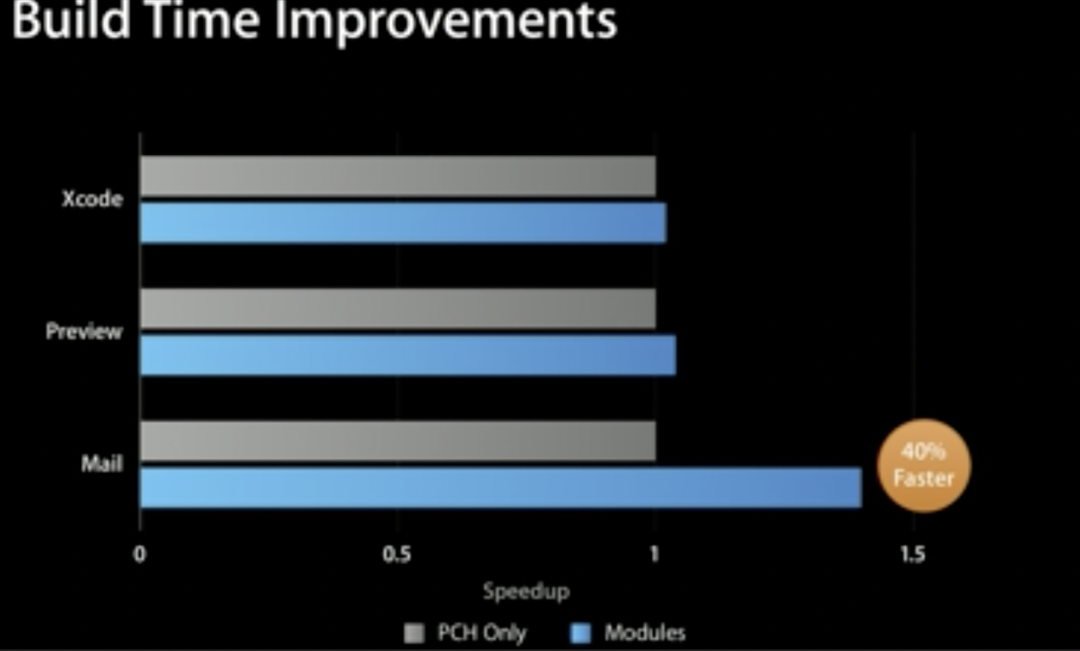
我们翻阅了苹果 WWDC 2013 的 Advances in Objective-C 视频,视频中针对编译时间性能方面进行了 PCH 和 Module 编译速度的数据分析。苹果给出的结论是小项目中 Module 比 PCH 能提升 40% 的编译时间,并且随着工程规模的不断增大,如增大到 Xcode 级别,Module 的编译速度也会比 PCH 稍快。PCH 也是为了加速编译而存在的,由此也可以间接得出结论,Module的编译速度要比没有 PCH 的情况下,是更快的,如在 Mail 下,应该提升 40% 以上。
对 Clang Module 机制建立一定的认知上,我们着手进行了 Clang Module 在 58同城 App 上的 Module 化改造。

组件 Module 化
在多 pod 的项目中,通过以下几种方式可以将各 pod 进行 Module 化:
Podfile 中添加 use_modular_headers! 对所有的 pod 进行 Module 化;
Podfile 中通过 modular_headers 对每个 pod 单独进行 Module 化,如对 PodC 进行 Module 化,pod 'PodC', :path => '../PodC',:modular_headers => true;
在 pod 所对应的 .podspecs 中的 xcconfig 中 sg 配置 DEFINES_MODULE,如 s.xccOnfig= {'DEFINES_MODULE' => 'YES'}。
此外,为了能让其它组件能通过 module 方式引用 Module 化的组件,还需要设置它们之前的依赖关系。
在58同城中,维护了一个全局的依赖配置文件 dependency.json,这个文件通过自动化工具进行维护,各组件 pod 的 .podspecs 从 dependency.json 中动态读取自己依赖的其它组件,并生成相应的 dependency 关系。
通常在 Swift/OC 混编工程中会自动或手动在当前pod添加加一个桥接文件,如 PodC-Bridging-Header.h,配置当前 pod 中 Swift 需要引用的 OC 文件,形式如下所示。

这样可以达到编译的目的,但是由于依赖的组件都是在桥接文件中统一配置,对于每个 Swift 文件依赖了哪些 pod 组件,实际上并不清楚,而且 Swift 中每次修改新增一个 OC 文件的引用,都需要在桥接文件中进行修改,并且如果是减少对某个 OC 文件的引用,也不好确定是否要在桥接文件中进行删除,因为还需要判断其它 Swift 文件中是否有引用。
Swift 文件中可以通过 module 的方式去引用 OC 文件,因此,如果所依赖 OC 文件的 pod 都 Module 化后,可以通过 import module 的方式进行引用,每个 Swift 文件各自维护对外部 pod 的依赖,从而将 XXX-Bridging-Header.h 文件删除,也减少了对桥接文件的维护成本。
万事具备,只差编译!
结合苹果官方给出了性能数据,我们预测 Module 化后的编译速度是要比非 Module 情况更快,那不妨就编译试试,接下来在 58同城中分别在 module 和非 module 场景下进行编译。
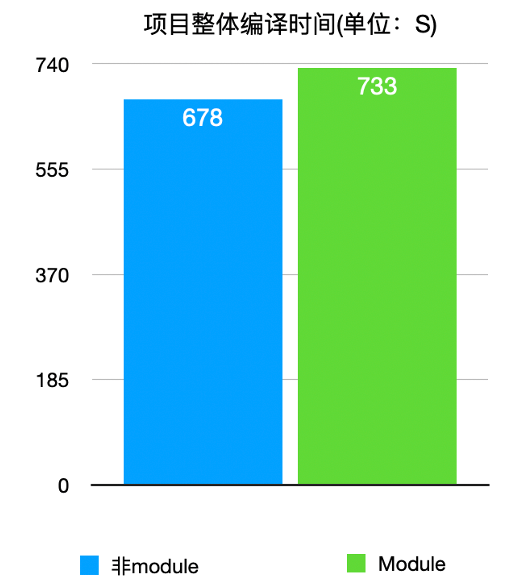
通过编译数据,我们看到的结果发生了逆转,Module 化之后的时间竟然比非 Module 情况下长约 8%,这跟刚才我们看到的苹果官方数据不符,有点乱了。需要说明的是这份数据是 58同城全业务线在 M1 机器上运行出来的,并且把资源复制的环节从配置中删除了,即不包含资源复制时间,是纯代码编译时间,并且在非 M1 机器上也运行了进行对比,除了时间长些,结论基本也是 module 化之后时间长 10% 左右。
在面对实际测试结果 Module 化之后的编译耗时更长的情况下,我们从更深层次上进行对 Clang Module 原理进行了探究。

Clang Module 机制的引入主要是为了解决预处理器的各种问题,那么工程在开启 Module 之后,工程上会有哪些变化呢?同时在编译过程中编译器工作流程与之前又有哪些不同呢?
以基于 cocoapods 作为组件化管理工具为例,开启 Module 之后工程上带来最直观的改变是pod组件下 Support Files 目录新增几个文件:podxxx.moduleMap , podxxx-umbrella.h。

Clang 官方文档指出如果要支持 Module,必须提供一个 ModuleMap 文件用来描述从头文件到模块逻辑结构的映射关系。ModuleMap 文件的书写使用 Module Map Language。通过示例可以发现它定义了 Module 的名字,umbrella header 包含了其目录下的所有头文件。module * 该通配符的作用是为每个头文件创建一个 subModule。
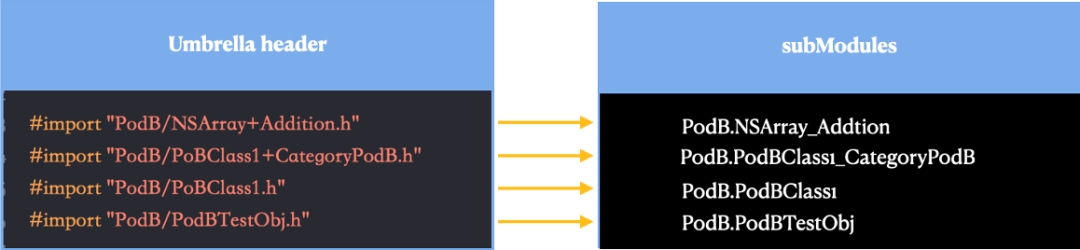
简单来说,我们可以认为 ModuleMap 文件为编译器提供了构建 Clang Module 的一张地图。它描述了我们要构建的 Module 的名称以及 Module 结构中要暴露供外界访问的 API。为编译器构建 Module 提供必要条件。
除了上述开启 Module 的组件会新增 ModuleMap 与 Umbrella 文件之外。在使用开启 Module 的组件时候也有一些改变,使用 Module 组件的 target 中 BuildSetting 中 Other C Flag 中会增加 -fmodule-map-file 的参数。

苹果官方文章中对该参数的解释为:
Load the given module map file if a header from its directory or one of its subdirectories is loaded.
(当我们加载一个头文件属于 ModuleMap 的目录或者子目录则去加载 ModuleMap File)。
了解完 ModuleMap 与 Umbrella 文件和新增的参数之后,我们决定深入去跟踪一下这些文件与参数的在编译期间的使用。
上文提到过在词法分析阶段以“#”开头的预处理指令,我们对针对 HeaderName 文件进行真实路径查找,并对要导入的文件进行同样的词法,语法,语义等操作。在开启 Module 化之后,头文件查找流程与之前有什么区别呢?在不修改代码的基础上编译器又是怎么识别为语义化模型导入(Module import)呢?
如下图所示:在初始化预处理之前,会针对 buildsetting 中设置的 Header Search path,Framework Search Path 等编译参数解析赋值给 SearchDirs。
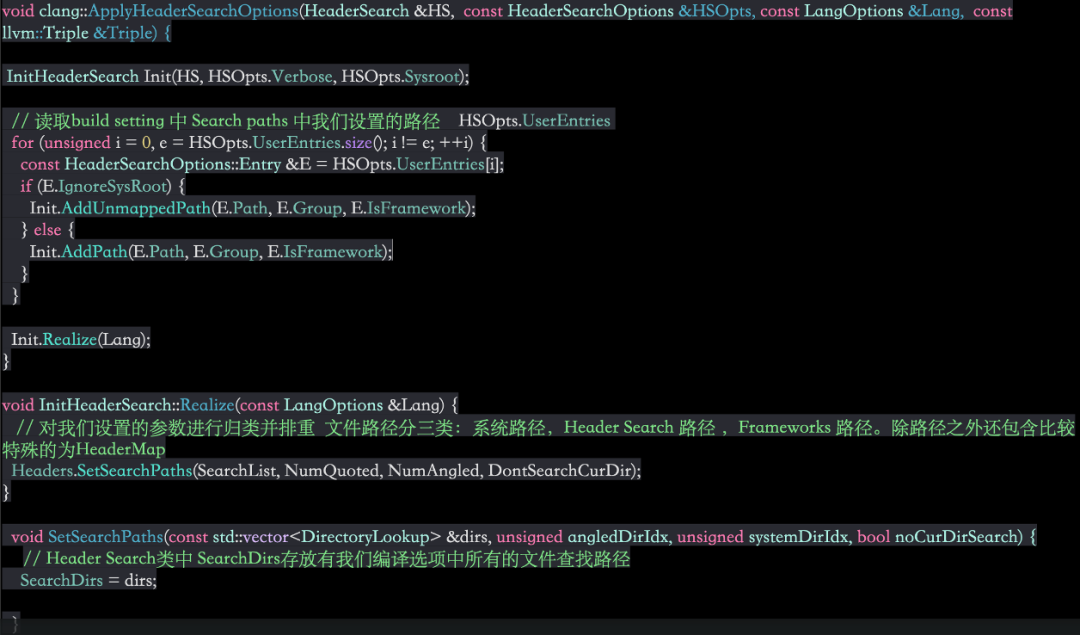
在 Clang 的源码中 Header Search 类负责具体头文件的查找工作,Header Search 类中持有的 SearchDirs 存放着当前编译文件所需要的头文件搜索路径。其中对于一个头文件的搜索分三种情况:hmap, Header Search Path 以及 Frameworks search path。而 SearchDirs 的赋值发生在编译实体(CompilerInstance)初始化预处理器时,而这些参数的来源则是在 Xcode 工程 Buildsetting 中的相关编译参数。
编译器在查询头文件具体磁盘路径的过程中,会通过 Header.h 或者 PodName/Header.h 与 SearchDirs 集合中的路径拼接判断该路径下是否存在我们要查找的头文件。当前循环的 SearchDirs 对应的元素中根据类型:(Header Search Path,Frameworks,HeaderMap)进行相应的查询流程。

上文提到过针对开启 Module 的组件不需要额外的修改头文件导入的代码,编译器自动识别我们的头文件导入是否属于 Module,而判断 Header 导入是否属于 Module import 就发生在查找头文件路径中。上述代码我们会注意到针对 Framework 与常规的目录查找中,会透传一个参数 SuggestedModule。
我们进一步向下跟踪 SuggestModule 的赋值过程,在查找到头文件的磁盘路径之后,编译器会进行该文件目录或者父级目录路径作为 Key 去 UmbrellaDirs 查找该头文件的是否有对应的 Module 存在。如果能查询到则赋值 SuggestModule(ModuleMap::KnownHader(Module *,NormalHeader) )。下图为查询并赋值 SuggestModule 的流程。

相信你看到上面的源码,你又会出现新的疑惑。UmbrellaDirs 是什么?前面提到过使用开启 Module 组件的 Target 中会新增 -fmodule-map-file 的参数,编译器在解析编译参数时加载 MoudleMapFile,读取使用 Module Map Language 书写的 ModuleMap 文件,解析文件的内容。

编译器在编译工程源代码时候通过 -fmodule-map-file 参数读取我们要使用的 Module,并把 ModuleMap 文件所在的路径作为 key,我们要使用的 Module 作为 Value,赋值给 UmbrellaDirs。预处理器在解析外界引入的头文件时候,会判断头文件路径下或者头文件路径父级目录是否存在 ModuleMap 文件,如果存在则 SuggestModule 有值。头文件查找的流程至此结束。
SuggestModule 的值是编译器决定使用 Module Import 还是“文本导入” 的关键因素。预处理器处理头文件导入,会去查找头文件在磁盘上的绝对路径,如果 SuggestModule 有值,编译器会调用 ModuleLoader 加载需要的 Module,而不开启 Module 的组件头文件,编译器则会进入该文件进行新的词法分析等流程。

至此,相信读到这里大家对 ModuleMap、Umbrella 文件以及 -fmodule-map-path 有了一定的认知。而且我们也跟踪了为什么编译器可以做到不修改代码的“智能”的帮助代码在 # import 和 Module Import 之间切换。
与非 module 不同,我们来继续追踪一下 LoadModule 的后续发生了什么?ModuleLoader 进行指定的 Module 的加载,而这里的 LoadModule 正是 Module 机制的差异之处。
Module 的编译与加载是在第一次遇到 ModuleImport 类型的 importAction 时候进行缓存查找和加载,Module 的编译依赖 moduleMap 文件的存在,也是编译器编译 Module 的读取文件的入口,编译器在查找过程中命中不了缓存,则会在开启新的 compilerInstance,并具备新的预处理上下文,处理该 Module 下的头文件。产生抽象语法树然后以二进制形式持久化保存到后缀为 .pcm 的文件中(有关 pcm 文件后文有详细讲解),遇到需要 Module 导入的地方反序列化 PCM 文件中的 AST 内容,将需要的 Type 定义,声明等节点加载到当前的翻译单元中。
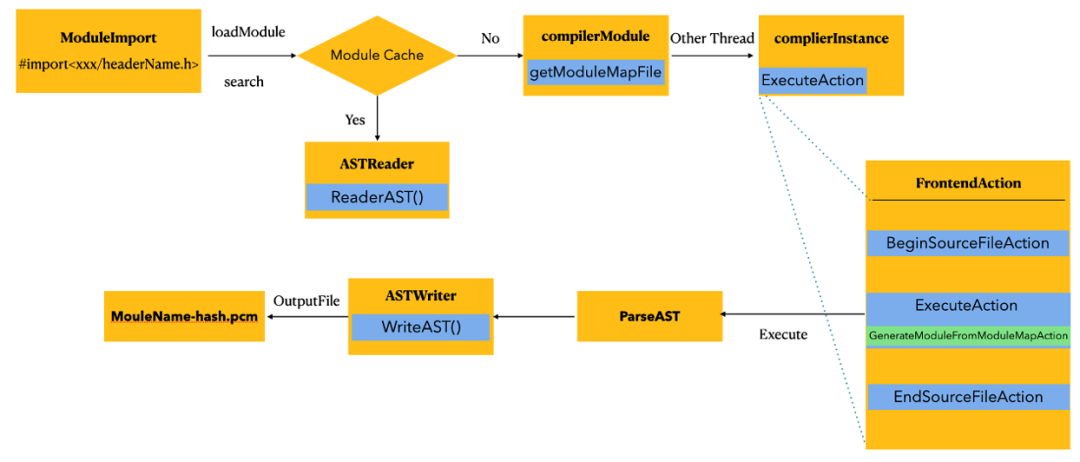
Module 持有对 Module 构建中每个头文件的引用,如果其中任何一个头文件发生变化,或者 Module 依赖的任何 Module 发生变化,则该 Module 会自动重新编译,该过程不需要开发人员干预。
Clang Module 机制的引入,不仅仅从之前的“文本复制”到语义化模型导入的转变。它的设计理念同时也着重在复用机制,做到一次编译写入缓存 PCM 文件在此后其他的编译实体中复用缓存。关于 Module 都是编译和缓存探究的验证,我们可以在 build log 中通过 -fmodules-cache-path 来查看获取到 Module 缓存路径(eg:/Users/xxx/Library/Developer/Xcode/DerivedData/ModuleCache.noindex/ )。当前如果你想自定义缓存路径可以通过添加 -fmodules-cache-path 指定缓存路径。
我们知道针对组件化工程,我们每个 pod 库都可能存在复杂的依赖关系,以某工程示例:
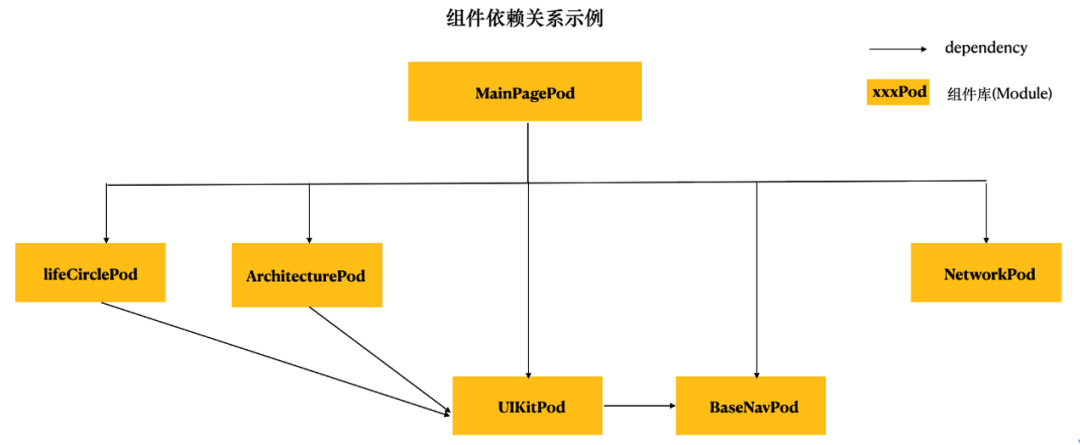
在多组件工程中,我们会发现不同的组件之间会存在相同的依赖情况。针对复杂的 Module 依赖的场景,通过 Clang源码发现,在编译 Module-lifeCirclePod(上述示例)时候,而 lifeCirclePod 依赖于 Module-UIKitPod。在编译 Module-lifeCirclePod 遇到需要 Module-UIKitPod 导入时,那么此时则会挂起该编译实体的线程,开辟新的线程进行 Module-UIKitPod 的编译。
当 Module-UIKitPod 编译完成时候才会恢复 lifeCirclePod 的任务。而开启 Module 之后每个组件都会作为一个 Module 编译并缓存,而当 MainPagePod 后续编译过程中遇到 Module-UIKitPodModule 的导入时,复用机制就可以触发。编译器可以通过读取 pcm 文件,反序列化 AST 文件直接使用。编译器不用每次重复的去解析外界头文件内容。
上述基本对 Module 的本质及其复用机制有一定的了解,是不是无脑开启 Moudle 就可以了呢?
其实不然!
我们在实践中发现(以基于 cocoapods 管理为例)在 fmodules-cache-path 的路径下存在很多份的 pcm 缓存文件,针对同一个工程就会发现存在多个下面的现象:

可以发现在工程的一次编译下,会出现多个目录出现同一个 module 的缓存情况(eg:lifeCirclePod-1EBT2E5N8K8FN.pcm)。之前讲过 Module 机制是一次编译后续复用的吗?实际情况好像与我们的理论冲突!这就要求我们去深入探究 Module 复用的机制。
追寻 Clang 的源码发现编译器进行预处理器 Preprocessor 的创建时,会根据自身工程的参数来设定 Module 缓存的路径。

我们将影响 Module 缓存的产生的 hash 目录的主要受编译参数分为下面几大类:

在实际的工程中,常常不同 pod 间的 build settting 不同,导致在编译过程中会生成不同的 hash 目录,从而缓存查找时候会出现查找不到 pcm 缓存而重复生成 Module 缓存的现象。这也解释了我们上面发现不同的缓存 hash 目录下会出现相同名字的 pcm 缓存。了解 Module 缓存的因素可以有助于在复杂的工程场景中,提高 Module 的复用率减少 Module Complier 的时间。
Tips:除了上述的缓存 hash 目录外,我们会发现在目录下存在以 ModuleName-hashxxxxxx.pcm 的命名,那么缓存文件的命名方式我们发现是 ModuleName+hash 值的方式,hash 值的生成来自 ModuleMap 文件的路径,所以保持工程路径的一致性也是 Module 复用的关键因素。
上文提到了一个很重要的文件 PCM,那么 PCM 文件作为 Module 的缓存存放,它的内容又是怎么样的呢?
提到 PCM 文件,我们第一时间很容易联想到 PCH。PCH 文件的应用大家应该都很熟悉,根据苹果在介绍 PCH 的官方文档中结构如下:
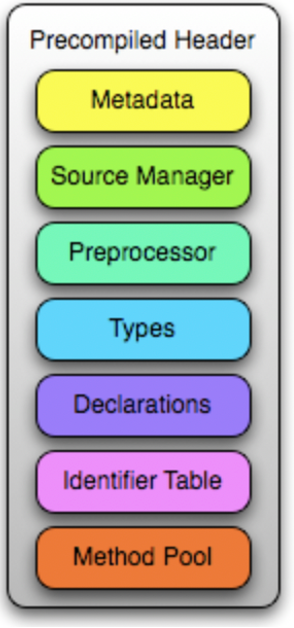
PCH 中存放着不同的模块,每个模块都包含 Clang 内部数据的序列化表示。采用 LLVM’s bitstream format 的方式存储。其中 Metadata 块主要用于验证 AST 文件的使用;SourceManager 块它是前端 SourceManager 类的序列化,它主要用来维护 SourceLocation 到源文件或者宏实例化的实际行/列的映射关系;Types: 包含 TranslationUnit 引用的所有类型的序列化数据,在 Clang 类型节点中,每个节点都有对应的类型;Declarations: 包含 TranslationUnit 引用的所有声明的序列化表示;Identifier Table: 它包含一个 hash Table,该表记录了 ASTfile 中每个标识符到标识符信息的序列化表示;Method Pool: 它与 Identifier Table 类似,也是 Hash Table,提供了 OC 中方法选择器和具体类方法和实例方方法的映射。Module 实现机制与 PCH 相同,也是序列化的 AST 文件,我们可以通过 llvm-bcanalyzer 把 pcm 文件的内容 dump 出来。
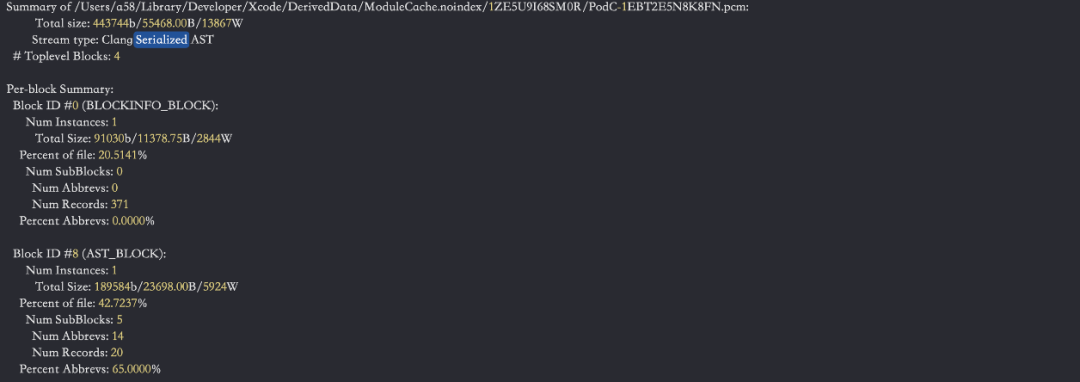
Module 的编译是在独立的线程,独立的编译实体过程,与我们输出目标文件对应的前端 action 不同,它所对应的FrontAction为GenerateModuleAction。Module 的机制思想主要是提供一种语义化的模块导入方式。所以 PCM 的缓存内容同样会经过词法,语法,语义分析的过程,PCM 文件中的 AST 模块的序列化保存是在发现在语义分析之后。
它利用了 Clang AST 基类中的 ASTConsumer 类,该类提供了若干可以 override 的方法,用来接收 AST 解析过程中的回调,当编译单元TranslationUnit的AST完整解析后,我们可以通过调用 HandleTranslationUnit 在获取到完整抽象语法树上的所有节点。PCM 文件的写入由 ASTWriter 类提供 API,这些具体的流程我们可以在 ASTWriter 类中具体跟踪。在该过程中主要分为 ControlBlock 信息的写入,该步骤包含 Metadata, InputFiles,Header search path 等信息的记录。这些 PCM 的具体内容 dump 出来如下图:
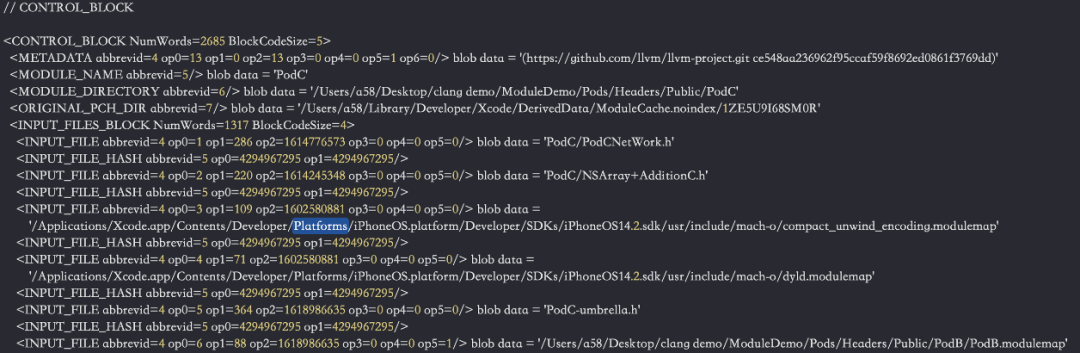
其中 Types,Declarations 等信息的写入流程发生在 ASTBlock 阶段。由于在处理处理 ModuleMap 文件的编译流程中会对 umbrella.h 中所暴露的头文件进行预处理,词法,语法,语义分析等流程。我们在使用 WriteAST() 写入时,会将当前编译实体的 Sema 类(该类是 build AST 和语义分析的实现类)传递过来。Sema 持有当前的 ASTContext,ASTContext 则可以用于访问当前抽象语法树上的所有 Nodes(例如 types,decls)等信息。
如果所示:ASTWriter 将已经解析无误的 Module 信息,包括 AST 等内容写入 Module 的缓存文件 PCM 中。

我们在源码跟踪过程中可以发现会将AST节点信息等写入PCM中的ASTBlock中,我们可以通过打印获取到节点的类型和节点的名称:
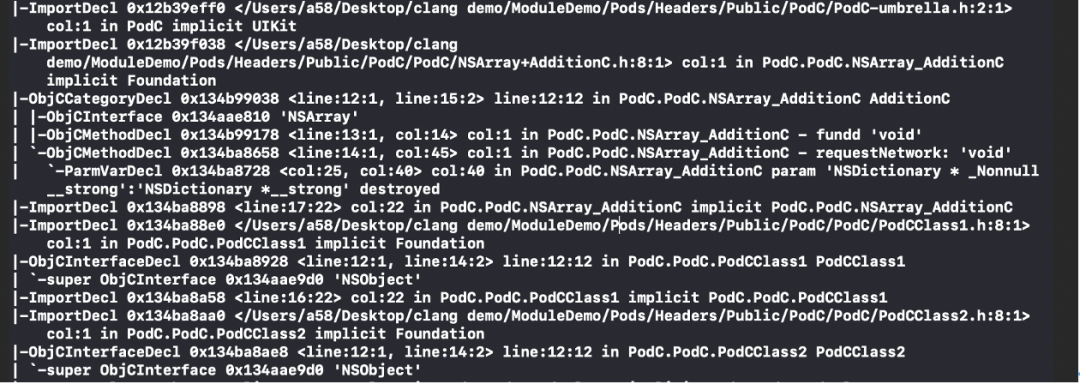
通过上面源码等流程相信你掌握了以下:
ModuleMap 文件用来描述从头文件到模块逻辑结构的映射关系,Umbrella 或者Umbrella Header 描述了子Module的概念;
Module 的构建是“独立”进行的,Module 间存在依赖时,优先编译完成被依赖的Module;
Clang 提供了 Module 的新用法(@import ModuleName),但是针对就项目无需改造,Clang 在预处理时期提供了 Module 与非 Module 的转换;
Module 提供了复用的机制,它将暴露外界的 API 以 ASTFile 格式存储,在代码未发生变化时,直接读取缓存。而在代码变动时,Xcode 会在合适的时机对 Module 进行更新,开发者无需额外干预。

鉴于在58同城工程上实施的编译数据时间的加长的背景,我们在深入探究 Module 构建,复用等机制后,我们针对整个编译流程做了详细的编译阶段的插桩。
Clang 9.0 合并了一个非常有用的功能 -ftime-trace,该功能允许以友好的格式生成时间跟踪分析数据,clang中预先插入了一些点标记,如每个文件的编译时间ExecuteCompiler、前端编译时间Frontend、module加载时间Module Load、后端处理时间Backend等。接下来通过-ftime-trace查看各编译阶段的打点时间。操作比较简单,只需要在Other C Flags中添加-ftime-trace即可。

编译完成后clang会在编译目录下,为每个源文件自动生成一个json文件,文件名和源码文件相同。

每个json文件中大概会有ExecuteCompiler、Frontend、Source、Module Load、Backend等打点数据,也有Total ExecuteCompiler、Total Frontend、Total Source、Total Module Load、Total Backend这样的数据,后者是前者的一个汇总,这是clang自带的,也可以在clang中去扩展。通过chrome://tracing/可以很方便查看单个json文件的耗时分布,如下。

-ftime-trace设置后主要时间段说明:
Total ExecuteCompiler:文件编译总时间;
Total Frontend:前端编译时间,如在clang中编译时间;
Total Source:头文件处理时间,如处理import;
Total Module Load:Module的加载时间,如在Source的处理过程中,判断当前import的是一个module,则会执行此操作,如import系统库;
Total Module Compile:Module的编译时间,如第一次加载自定义的源码Module,会对Module进行编译,生成AST缓存起来;
Total Backend:编译器后端处理时间。
这些时间段都是Clang中已有的打点,从前面的chrome://tracing/图也能看出来是有一些包含关系的,如:
ExecuteCompiler 包含Frontend和Backend;
Frontend包含Source;
Source中包含Module Load(前提是如当前.m中import了A/XX.h,而A没有module化,但XX.h中import了B/YY.h,B是Module化的,如果A是module化的,Module Load不包含在Source中);
Module Load包含Module Compile。
先选取单个文件进行分析,将其拖到chrome://tracing/中,可看到如下数据。
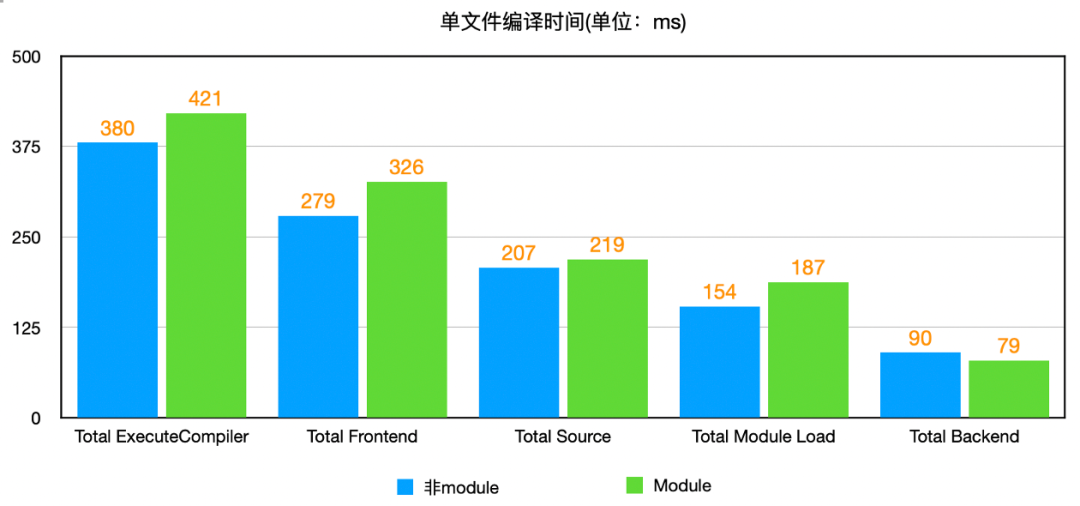
从图上可看出,Total Frontend占总编译时间在都在70%以上,module编译中Total Frontend时间比非module明显要长,而Total Source占Total Frontend时间的70%左右,而Total Module Load是Total Source中最耗时的操作。结果中Total Module Load阶段,module明显是要比非module耗时更长。
上面是从单个文件进行分析,并不能代表整体项目的编译情况,因此,我们做了一个自动化工具,将所有.json文件中的对应时间进行统计汇总,得出整体各个时间段的汇总数据,如下。说明一下,我们统计的Total ExecuteCompiler指每个文件的编译时间总和,相当于在单核下编译时间,而前面显示的实际整体的编译时间少很多,是因为我们实际是在多核下编译。
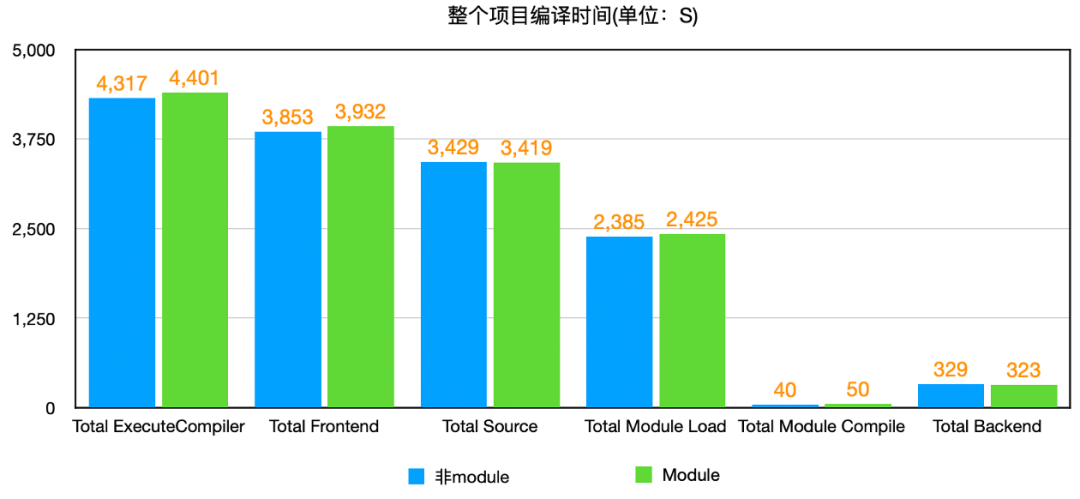
从整体分析图上可看出,Total Frontend时间均占总编译时间Total ExecuteCompiler的80%以上,而Total Frontend中时间Total Source的总时间占80%以上,而在Total Source中Total Module Load时间占70%左右。总时间Total ExecuteCompiler和前端Total Frontend依然是module下更长,而在Total Frontend中Total Module Load的时长在module下明显比非module下长很多,跟上面单文件分析的结论基本一致。这里需要注意的是,Total ExecuteCompiler时间比前面统计的总时间长很多,是因为项目是在多核下编译,而Total ExecuteCompiler统计的是所有文件编译时间总和,而前面统计的时间是多文件并行编译下的时间,其它各段时间同理。
在Total Module Load中会执行Module的编译,但从上图我们可以看到其实Total Module Compile时间很短,都不超过50S,因此还需要进一步分析Total Module Load的耗时操作。为此我们根据clang中的处理流程,在clang中Module Load处理代码中扩展两个打点:
Module ReadAST:验证Module缓存并反序列化Module cache PCM文件的时长;
Module WaitForLock:一个线程在ModuleCompiler期间,其他线程需要挂起等待的时长。
并在头文件查找扩展打点:
Lookup HeaderFile :预处理阶段查找导入头文件的磁盘路径时间。
将Clang源码修改后编译生成自定义的Clang,替换XCode中的Clang分别在module和非module下再次进行编译,得出如下数据:
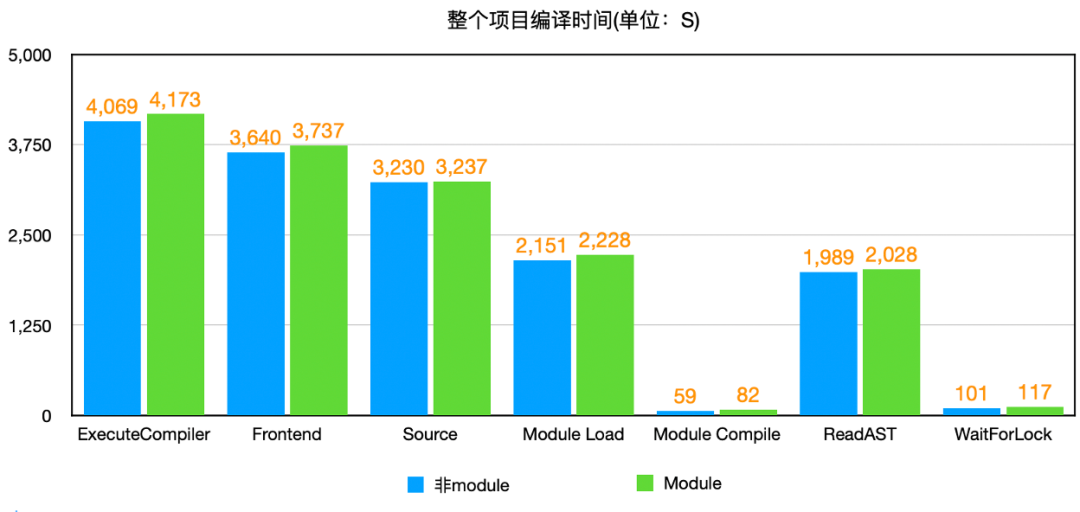
从图中可以看出,Module Load阶段中Module ReadAST时间占比近70%,此次编译module比非module下时间长约3%,而Module ReadAST段module比非module下时间长约2%,整个Module Load阶段module下比非module下长约4%。
因此,我们可以得出,相比非module,module化编译更为耗时,而主要耗时在验证Module缓存并反序列化操作。那么问题来了,有什么办法可以在module开启的情况下进行编译时间优化呢?

从上面的数据分析我们知道,如果底层组件进行 Module 化,并且上层组件通过module方式进行引用的话,会更耗时。但是为了支持 Swift/OC 混编,如 Swift 调用 OC,需要对组件进行 Module 化。因此,我们需要在 Module 化的基础上优化编译时间,如果上层组件不通过 Module 方式调用其它 Module 化的组件,而采用非 Module 化方式进行引用,理论上是能避免上述module化操作的耗时。
为了进一步优化混编下的编译时间,我们参考苹果 WWDC 2018 的 header search path 中 headermap 查找方案,主要思路是通过 hmap 的方式来替换header search path 下的文件搜索,来减少编译耗时,为描述方便,我们称为hmap方案,目前业内美团对 hmap 有应用,并且有 50% 的优化效果。58同城也对 headermap 方案进行了研究并进行了落地,理想的实现方案就是做一个 cocoapods 插件,在插件中做了以下几件事:
HooksManager注册cocoapods的post_install钩子;
通过header_mappings_by_file_accessor遍历所有头文件和header_dir,由header_dir/header.h和header.h为key,以头文件搜索路径为value,组装成一个Hash
再修改各pod中.xcconfig文件的HEADER_SEARCH_PATHS值,仅指向生成的hmap文件,删除原来添加的搜索目录;
修改各pod的USE_HEADERMAP值,关闭对默认的hmap文件的访问。
58对应的插件名为cocoapods-wbhmap,插件完成后,在Podfile中通过plugin 'cocoapods-wbhmap'接入。
以下是58同城分别在非 Module、Module 化和优化后的 hmap 三种场景下编译时间数据,这里的 hmap 是在各组件 Module 化的基础上使用的。

首先说明一下,这里的整体编译时间数据上跟前面不一致,是因为重新编译了,每次编译时间略有不同,但不影响我们分析。从整体时间来看 Module 下的编译时间比非 Module 下略长,而 hmap 比非 Module 下优化了 32% 左右,比 Module 下优化了 33% 左右,可以看出 hmap 的优化效果是很显著的。
接下来分析一下编译各阶段的时间,是不跟我们预想的一致,我们预想的是 Total Lookup HeaderFile 和 hmap 在 Module Load 阶段加载的 Module基本是系统库,应当时间上差不多,而由于hmap节省了在众多目录下文件搜索的时间,应当在Total Lookup HeaderFile有较大差别。

从分段数据来看,三种编译方式的 Total ExecuteCompiler 跟上述整体时间比例接近,但是 Total Lookup HeaderFile 时间都较小,自然没多大差别,而 Total Module Load 差别较大,非 Module 和 Module 下比 hmap 大 61% 左右,跟我们预想的不一致。观察数据可以看到,Module Load 中大部分时间是在 Module ReadAST 阶段,因而我们继续研究 Module ReadAST 中的处理操作。
针对 ReadAST 阶段再次细分打点计时,发现在 ReadAST 阶段去读取缓存时候,会对缓存 PCM 文件的 ControlBlock 块信息进行解析,该内容包含了当前 Module 缓存引用外界其他 ASTFile 的记录。而加载外界 ASTFile 的 PCM 缓存时候,会针对该 ModuleName 进行验证确保我们不会加载一个 non-Module 的 ASTFile 作为一个 Module。它通过查询是否存在 ModuleMap 文件来描述 Module 对应当前要查询的 ModuleName。
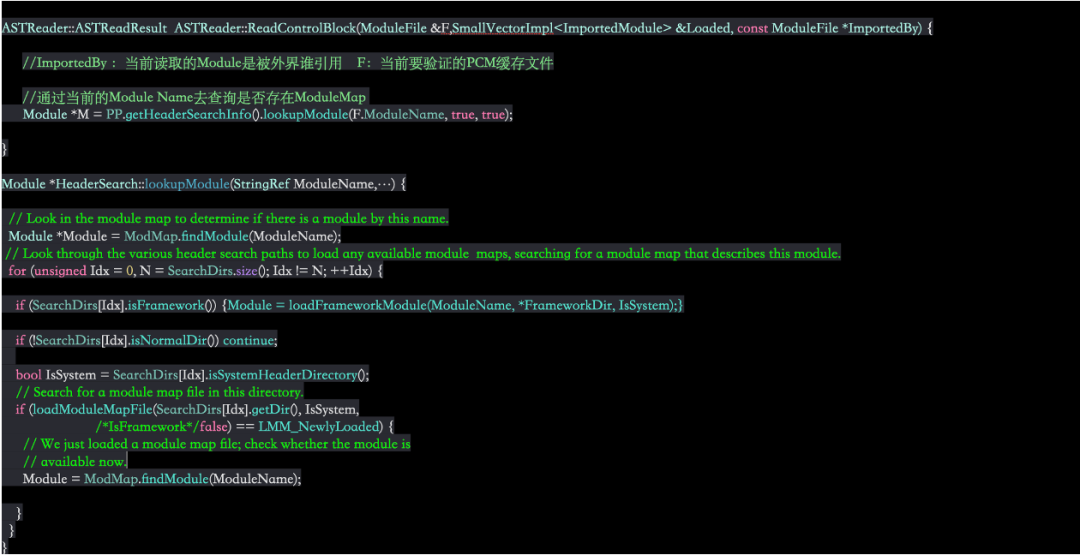
我们将重点聚焦在这个阶段,因为我们 hmap 方案最直接的优化之处在减少了 Header Search Path 的参数路径,将预处理期间的头文件查找转换为 key-value 查找,从而减少了在 Header Search Path 众多 pod 的目录中(如private、public)的搜索时间,源码中 SearchDirs 即为这些目录,Header Search Path 中目录越多,SearchDirs 中元素更多,要遍历的目录就更多,无用的搜索时间就越长,通过单个文件进行调试发现这里消耗的时间约有 70%,而系统库的查找在这里耗时较长,因为按照编译器搜索的顺序,系统库目录的是排在 Header Search Path 后的,经过一顿徒劳的搜索之后才到系统库目录搜索,效率较低。
我们猜想前面非 Module 和 hmap 在 Module Load 时间差较大的原因应当就在此,因此在 ReadAST 阶段的 HeaderSearch::lookupModule 方法内打个点 Lookup Module,即 Module ReadAST 包含 Lookup Module,重新编译进行数据统计如下:
这里只统计非 Module 和 hmap,整体编译时间如下:

从数据可以看出,再次编译 hmap 下的编译时间比非 Module 方式同样是优化了 35% 左右。再看分段数据,如下:
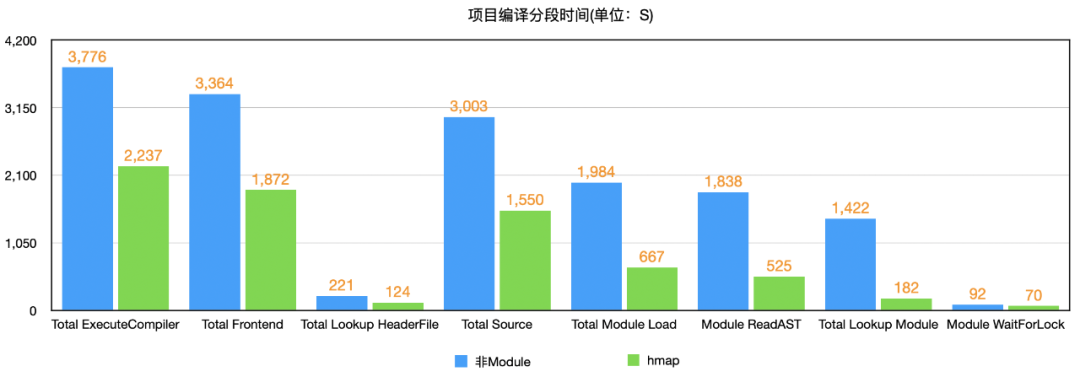
从占比分析,非 Module 方式下 Total Lookup Module 时间占 Total Module ReadAST 时间的 77%,并占 Total Module Load 时间的 72%,而在 hmap 方式中,Total Lookup Module 时间占 Total Module ReadAST 时间的 35%,并占 Total Module Load 时间的 27%,远小于非 Module 方式下的占比。
从数值分析,非 Module 方式下 Total Lookup Module 时间为 1422 秒,而 hmap 方式下时间仅为 182 秒,相差 7 倍多。
上面数据也进一步验证了我们对于 hmap 编译时间优化原因的猜想。到这里我们就从数据和原理上对 hmap 方案的编译优化做了一个完整的分析。

由于 Swift/OC 混编项目的需要,58同城对组件进行了 Module 化,并且尝试让所有组件通过 Module 方式进行头文件引用。但我们发现编译时间却比非 Module 情况下更长,这也与苹果官方在 WWDC2013 中的 Module 性能分析结果不符。
然后在寻求编译时间的优化方案时,发现在 WWDC2018 中有提到 hmap 机制,并借鉴业内的一些宝贵经验,采用了 hmap 方案对编译时间进行优化。Module 方案虽无法降低编译耗时,但对比之前混编的桥接方式,可增强项目向 Swift 迁移过程中混编组件的可维护性。通过 hmap 方案对编译时间进行优化,同城最终编译时间比 Module 化之前优化了约 35%,对于其它 App 的 Module 化也是有较好的借鉴意义。

☞阿里将投入1000亿元助力共同富裕;Siri偷听用户对话被起诉 ;Linux Lite 5.6最终版正式发布|极客头条
☞骗子开始“卷”良心?黑客竟将 33.6 万美元的骗款全数退还!
☞对标苹果 M1,谷歌自研 ARM 芯片或将于 2023 年发布?






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 