当单表数据量过大的时候,关系性数据库会出现性能瓶颈,这时候我们就可以用NoSql,比如Hbase就是一个不错的解决方案。接下来是用Spring整合Hbase的实际案例,且在最后会给出整合中可能会出现的问题,以及解决方案。这里我是用本地Windows的IDEA,与局域网的伪分布Hbase集群做的连接,其中Hbase集群包括的组件有:Jdk1.8、Hadoop2.7.6、ZooKeeper3.4.10、Hbase2.0.1,因为这里只是开发环境,所以做一个伪分布的就好,之后部署的时候再按生产环境要求来即可

这里要导入Hbase连接所需要包,需要找和你Hbase版本一致的包
org.apache.hbase hbase-client 2.0.1
我是用的配置文件连接方法,这个配置文件你在hbase的安装目录下的conf目录就可以找到,然后你直接把它复制到项目的resources目录下就好,当然你也可以用application.properties配置文件外加注入和代码的方式代替这个配置文件
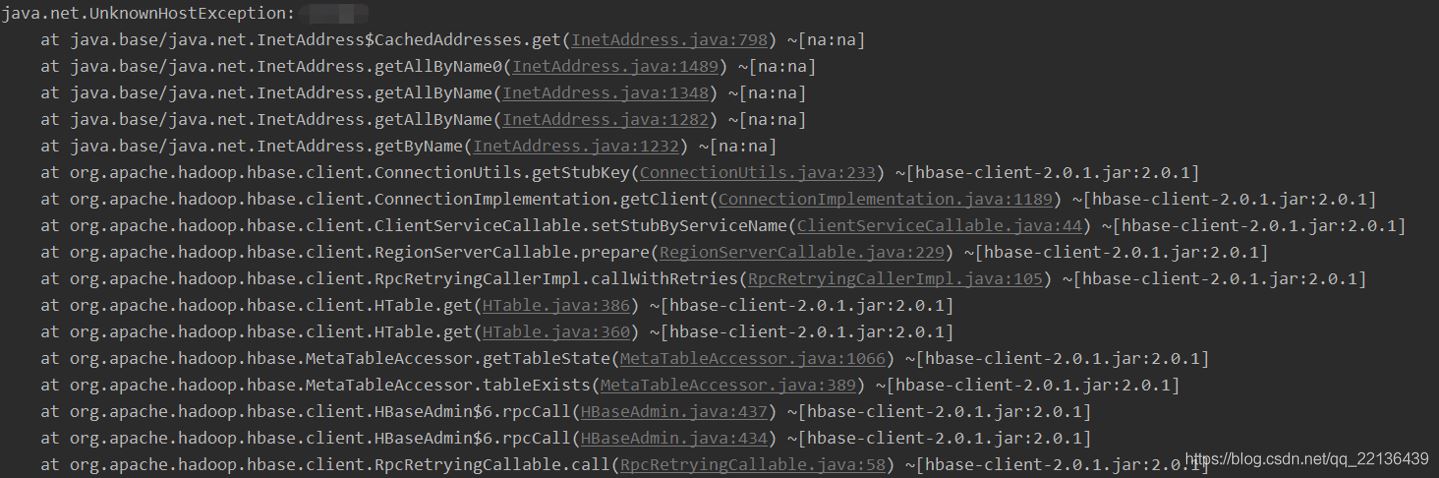
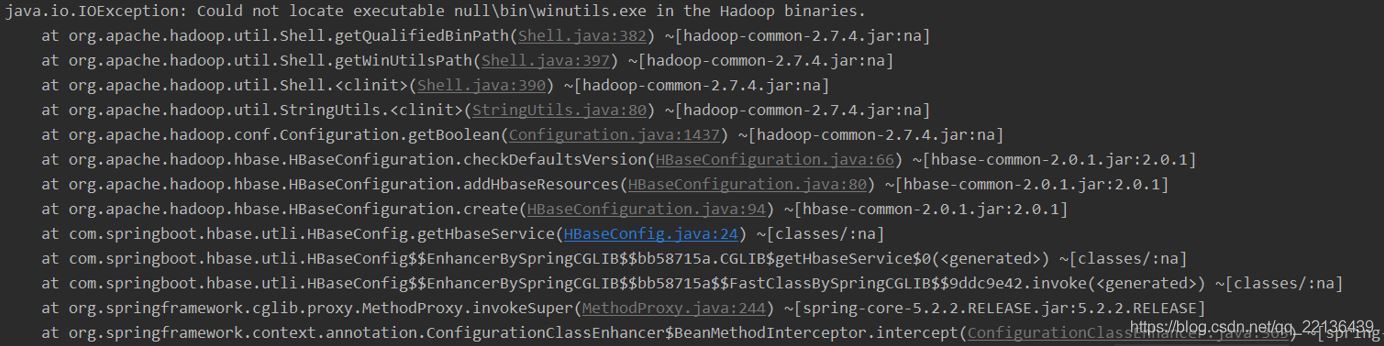
这里因为只需连接Hbase就没连接Hadoop,如果要连接Hadoop,Windows下还要下载winutils.exe工具,后面会介绍
@Configuration
public class HBaseConfig {
@Bean
public HBaseService getHbaseService() {
//设置临时的hadoop环境变量,之后程序会去这个目录下的\bin目录下找winutils.exe工具,windows连接hadoop时会用到
//System.setProperty("hadoop.home.dir", "D:\\Program Files\\Hadoop");
//执行此步时,会去resources目录下找相应的配置文件,例如hbase-site.xml
org.apache.hadoop.conf.Configuration cOnf= HBaseConfiguration.create();
return new HBaseService(conf);
}
}
这是做连接后的一些操作可以参考之后自己写一下
public class HBaseService {
private Logger log = LoggerFactory.getLogger(HBaseService.class);
/**
* 管理员可以做表以及数据的增删改查功能
*/
private Admin admin = null;
private Connection cOnnection= null;
public HBaseService(Configuration conf) {
try {
cOnnection= ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
log.error("获取HBase连接失败!");
}
}
/**
* 创建表 create 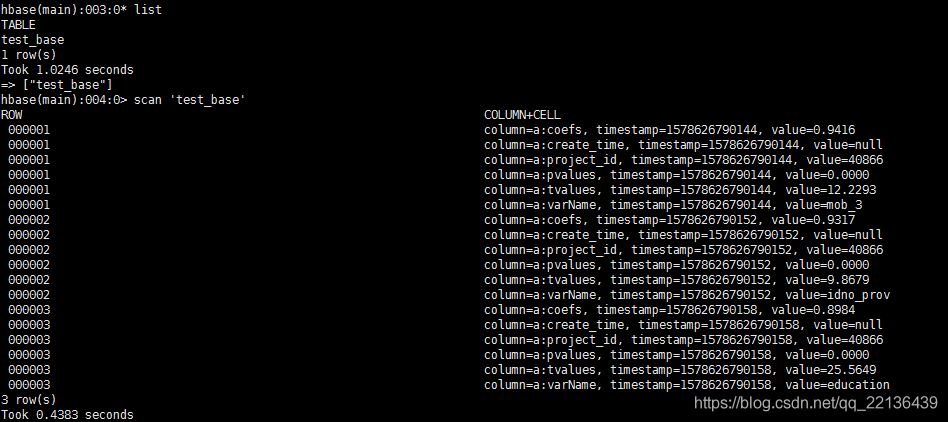











 京公网安备 11010802041100号
京公网安备 11010802041100号