简介
CART与C4.5类似,是决策树算法的一种。此外,常见的决策树算法还有ID3,这三者的不同之处在于特征的划分:
ID3:特征划分基于信息增益
C4.5:特征划分基于信息增益比
CART:特征划分基于基尼指数
基本思想
CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。
CART算法由以下两步组成:
决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;
决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时损失函数最小作为剪枝的标准。
CART决策树的生成就是递归地构建二叉决策树的过程。CART决策树既可以用于分类也可以用于回归。本文我们仅讨论用于分类的CART。对分类树而言,CART用Gini系数最小化准则来进行特征选择,生成二叉树。 CART生成算法如下:
输入:训练数据集D,停止计算的条件:
输出:CART决策树。
根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树:
设结点的训练数据集为D,计算现有特征对该数据集的Gini系数。此时,对每一个特征A,对其可能取的每个值a,根据样本点对A=a的测试为“是”或 “否”将D分割成D1和D2两部分,计算A=a时的Gini系数。
在所有可能的特征A以及它们所有可能的切分点a中,选择Gini系数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
对两个子结点递归地调用步骤l~2,直至满足停止条件。
生成CART决策树。
算法停止计算的条件是结点中的样本个数小于预定阈值,或样本集的Gini系数小于预定阈值(样本基本属于同一类),或者没有更多特征。
代码
代码已在github上实现(调用sklearn),这里也贴出来
测试数据集为MNIST数据集,获取地址为train.csv
运行结果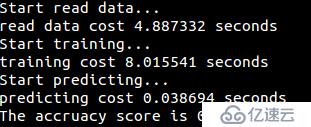
为了帮助大家让学习变得轻松、高效,给大家免费分享一大批资料,帮助大家在成为大数据工程师,乃至架构师的路上披荆斩棘。在这里给大家推荐一个大数据学习交流圈:658558542 欢迎大家进×××流讨论,学习交流,共同进步。
当真正开始学习的时候难免不知道从哪入手,导致效率低下影响继续学习的信心。
但最重要的是不知道哪些技术需要重点掌握,学习时频繁踩坑,最终浪费大量时间,所以有有效资源还是很有必要的。
最后祝福所有遇到瓶疾且不知道怎么办的大数据程序员们,祝福大家在往后的工作与面试中一切顺利。











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有