术语备注:
1、OLTP。这是on-line transaction processing的简写。翻译成联机事务处理。就是在线交易的业务数据。这方面的数据库是关系型数据库。
2、OLAP。On-Line Analytical Processing 翻译成联机分析处理。通俗理解,就是做数据统计、分析的平台。顺应这个需求产生了数据仓库的概念。
3、数据仓库。只是一个概念,数据的仓库。搭建数据仓库的技术方案可以是关系型数据库,也可以是列存储。为了通俗理解,可以把数据仓库和OLAP看作一个东西。
4、商业智能BI。本质还是依赖于数据仓库做支持的,没有数据存储,没有大量数据,无法统计、无法分析。
怎么来理解或区分数据库和数据仓库的关系?
业界经常说的术语是OLTP,这是on-line transaction processing的简写。联机事务处理。
OLAP是On-Line Analytical Processing 翻译成联机分析处理。
从名字来看,可以看出一个侧重事务处理。一个侧重分析处理。事务处理,就是交易数据。如订单、商品等数据的增删查改。分析处理,要对这些数据分析出统计结果。分析处理,就要使用数据仓库来存储数据了,要与业务数据库分开,而数据来自于业务数据库。
联机交易处理使用的是交易型数据库,即行式存储关系型数据库如oracle、sqlserver、mysql。
联机分析处理使用的是分析型数据库,即列式关系型数据库hbase、hive、clickhouse等。
数据仓库只是一个概念,至于用什么数据库,随自己。对数据的分析处理,得到统计结果,归到数据仓库里面去,以提供在线查询。
数据库中的建模一般遵循三范式,而数据仓库的建模有特定的方式,一般采用维度建模。
为什么数据仓库喜欢使用列式关系型储数据库?
数据仓库使用的技术方案,有很多种。可以使用关系型数据库mysql,目前,业界一般使用列存储。
为什么不用mysql等行存储关系数据库来做数据仓库? 而一般使用列存储数据库, 是考虑到数据仓库的以下特点:
1、数据仓库的数据来源多个系统。可能是文件、可能是其他关系型数据库中的交易数据。
2、需要多个维度建立数据统计模型。
3、存储数据量。历史的,存档的,归纳的,计算的数据。
4、需要访问大量的记录才能统计出结果。如果统计性能上不能很慢,无法出统计结果。就满足不了分析统计的需求。
涉及到复杂的聚合统计查询,这类系统就比较难以处理了,比如要查询某一些类型的用户过去三个月购买最多的商品,因为同一时间需要查询大量数据,OLTP(关系数据库) 系统并不擅长处理这类需求。
5、更新数据很少。都是添加数据、查询数据。于是对查询速度要求高。
列式型关系数据库,使用上与mysql一样,都是sql语句操作,也是关系表设计。唯独底层存储原理不一样。下面解释。
对比行存储和列存储
下面来看网上找的一张图,对比行存储和列存储
行存储的一行数据(此行的所有数据)都在一起,紧接着就是第二行数据,依次下去。
列存储不同的是,一列的所有数据都放在一起了。
从上图可以很清楚地看到,行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。所以它们就有了如下这些优缺点:
| | 行式存储 | 列式存储 |
| 优点 | Ø 数据被保存在一起 Ø INSERT/UPDATE容易 | Ø 查询时只有涉及到的列会被读取 Ø 投影(projection)很高效 Ø 任何列都能作为索引 |
| 缺点 | Ø 选择(Selection)时即使只涉及某几列,所有数据也都会被读取 | Ø 选择完成时,被选择的列要重新组装 Ø INSERT/UPDATE比较麻烦 |
注:关系型数据库理论回顾 - 选择(Selection)和投影(Projection)
列存储在做join联合的时候,效率更高。
在列存储中,下面查询语句:select customers,material from table where customers="miler" and material="refrigerator"
一列的所有数据都在一块,所以每一列都是一个索引。对一列数据压缩也很方便,变成数字存储了。存储空间变小,存储空间变小,操作速度就更快。
关键步骤如下:
1. 去字典表里找到字符串对应数字(只进行一次字符串比较)。
2. 用数字去列表里匹配,匹配上的位置设为1。
3. 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
4. 使用这个下标组装出最终的结果集。
下面笔者整理了业界常来搭建数据仓库的数据库
在数据仓库领域的收费列数据库
1、惠普公司的Vertica
2、oracle公司Oracle Warehouse Builder的
3、sybase公司的Sybase IQ/SAPIQ
4、mysql公司出的Infobright。
5、Greenplum公司的Greenplum
互联网公司自主研发的
1、华为的Carbondata
2、百度研发给内部使用的palo。
3、腾讯Hermes
4、Druid:广告分析,互联网广告系统监控、度量和网络监控。开源免费。
5、俄罗斯的yandex公司为自己内部统计需要研发的clickhouse。yandex为俄罗斯的"百度"、"百度统计"业务。2016年6月份才开源发布出来。这个文档全,对php语言支持好。性能不弱于百度的palo。
| 数据库名称 | 所属公司 | 是否商业收费 | 优点 | 缺点 | 说明 | 列式存储(非行存储) |
| Oracle Warehouse Builder(OWB) | oracle | 商业收费 | 未知 | 未知 | 未知 | 未知 |
| Sybase IQ/SAPIQ | SAP | 商业收费 | | | SAP公司收购数据库公司SYbase的产品。Sybase IQ拥有列式存储、网格架构、专利的数据压缩、先进的查询优化器。电信和金融行业的客户较多 | 是 |
| Vertica | 惠普公司 | 商业收费 | 未知 | 未知 | | |
| hbase | Apache的Hadoop项目的子项目 | 开源免费 | 很适合统计多维度数据。目前看资料,乐视的视频云涉及到视频多维度统计从redis、mysql迁到hbase,响应需求更快。Facebook用在很多业务中。 | 1、搭建和维护HBase是很繁琐的,引入很多学习成本,遇到问题还要排查。2、Php操作hbase,需要安装一facebook的服务thrift,这个服务安装没成功。一个中间服务,不够简单。 | hbase与google的表格存储数据库bigtable是同一种东西。列存储。hbase是模仿bigtable产生的。 | 是 |
| hive | | 开源免费 | | 1、查询速度比较慢。2、基于MapReduce来处理数据。需要理解mapreduce,会写这种。目前来看不好上手 | | 否,只是一中架构。 |
| palo | 百度 | 开源免费 | 用在百度统计以及百度其他应用。 | 网上的使用资料比较少。要使用直接使用百度云提供的付费服务。百度云目前提供了付费服务 https://cloud.baidu.com/product/palo.html | | 列存储 |
| clickhouse | 俄罗斯的Yandex | 开源免费 | 查询速度快,SQL语句操作。 | 1、文档齐全。有官网。支持php、.net等各类语言,官网直接提供了各类语言的库。2、速度很快。经过Yandex公司自身的实践考验。俄罗斯的nginx也是久经考验。 | 此公司类似于中国的 百度和百度统计业务。为应对自身内部需要而开发 | 列存储 |
| Infobright | MySql公司 | 开源免费,有商业版和社区版 | | 1、社区版不支持更改数据。只能载入数据。2、社区版只能支持10多个并发查询 3、世面上用的人少。 | | 列存储 |
| Greenplum | Greenplum | 商业收费 | | | 基于关系数据库PostgreSQL做存储 | 列存储 |
| Druid | | 免费 | | | | 列存储 |
从上表中总结几个开源免费的:
典型列存储代表:
一、hbase
php操作hbase需要另外安装facebook开发的异构语言服务thrift。这点麻烦。我试验过。目前乐视云的视频统计从redis转到了hbase。
二、百度的palo(用在百度统计以及百度其他应用)。网上的使用资料比较少。要使用直接使用百度云提供的付费服务。百度云目前提供了付费服务
https://cloud.baidu.com/product/palo.html
三、俄罗斯的clickhouse。clickhouse比palo的性能要更强。
属于Yandex,此公司类似于俄罗斯的百度和百度统计。为了应对自身同统计需要而开发。目前已经开放出来使用。
对各种语言的支持要更好,php、python、.net等操作数据库的客户端库,在官网直接提供了。
clickhouse文档比较全,这是官网:https://clickhouse.yandex/docs/en/interfaces/third-party_client_libraries.html
国内介绍文档:https://zhuanlan.zhihu.com/p/22165241#tipjar
笔者推荐使用clickhouse。对比几个,对比目前可选的,从对上手程度、免费、对php的支持三个角度分析,只有这个最合适了
为什么不能使用Mongodb来做数据仓库?
设计初衷不同
SQL与NoSQL最大的不同之一就是不支持JOIN,在传统的数据库中,SQL JOIN子句允许你使用普通的字段,在两个或者是更多表中的组合表中的每行数据。
面向文档的数据库,例如MongoDB,被设计用来存储非结构化的数据,理想情况下,这些数据是在数据集合中是相互没有关联的。一个集合,可以看作mysql中的一个表。
虽然mongodb是支持关联查询,但是非常弱。使用关联查询性能马上就下来不少了。它本身的定位不是关系型数据库。
数据仓库的特点,它存在多个维度,关系比较复杂,必须使用关系型数据库来建立数据模型。而关系型数据库,目前基于行存储的关系型数据库mysql,在数据量大的时候,需要分表等操作,存在性能问题,所以业界使用基于列存储的关系数据库来做数据仓库。
故数据仓库这种比较复杂的逻辑关系处理,不要使用mongodb。
对clickhouse的研究情况
对列式数据库clickhouse,目前部署环境还顺利。发现对php操作数据库的支持、界面管理数据库的工具,官网都有直接提供。真是专门为花不起钱买商业数据库、又想技术维护门槛低的创业公司,准备的数据仓库软件,是另一个“MySQL”。
源码是c++写的。
此数据库,百度能搜索到的资料并不多,都是看官网英文。
原因是:数据仓库一般上规模的公司才会去使用;而一旦涉及,他们要么自己研发列式数据库,要么是购买商业列数据库解决方案。如华为Carbondata 、腾讯Hermes、沈阳延云YDB。惠普公司的Vertica数据库,Facebook购买是这个数据库做用户行为分析。
我之前在表格中列出了一些列数据库。要么是商业收费的,要么是上手不容易,要么功能限制太多。所以既要免费,又要功能和性能满足,可选的很少。
目前实际测验看,这个数据库确实是另一个“mysql”,适合创业公司特点:
1、免费却不输于商业数据仓库。网上别人公开的测验数据看,性能不比惠普公司等提供的商业列式存储数据库差。与百度自己研发列数据库palo,也进行过性能对比,各有千秋,不输。
2、好上手,维护成本低。对php支持良好。界面管理工具也全。
3、扩展方便。支持分布式和数据复制。
4、经过俄罗斯最大的搜索引擎公司yandex,内部场景运行后开源出来的。由于是2016年6月才开源出来,故国内公司使用不多,毕竟已经使用了商业数据仓库的,迁移要权衡。
俄罗斯人做东西挺给力,给了个著名的nginx的,风靡超过apache。
下面给试验数据
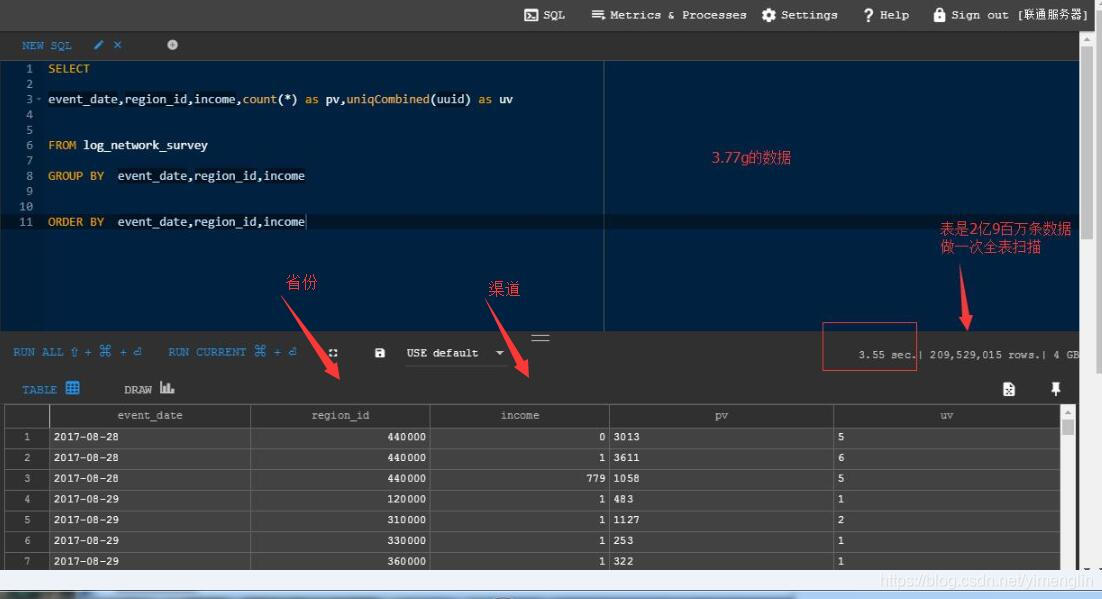
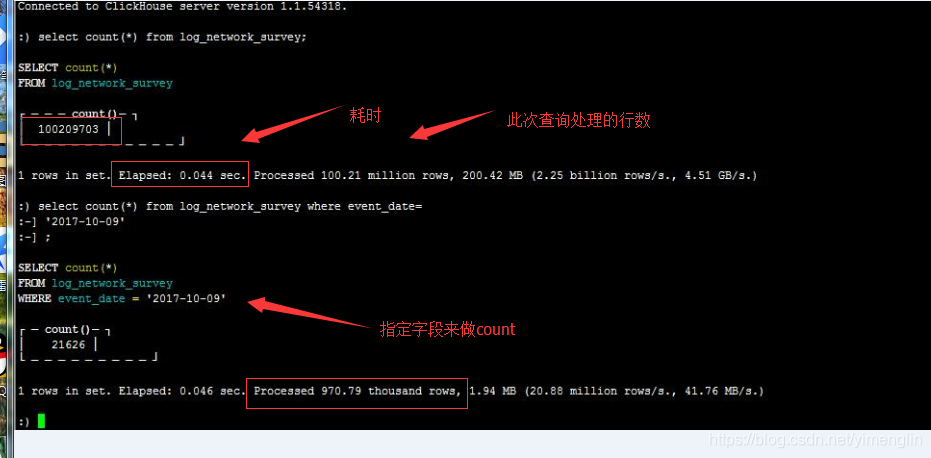
count速度是很快的,一亿条数据,
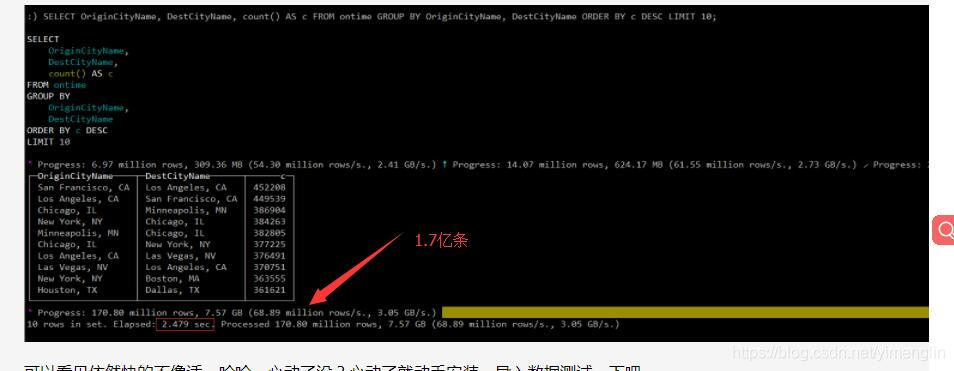
导入的官网提供的航空数据1.7亿条数据测验










 京公网安备 11010802041100号
京公网安备 11010802041100号