作者:陈可不能哭 | 来源:互联网 | 2023-08-24 04:35
nature作为科学界最顶级的期刊之一,其期刊封面审美也一直很在线,兼具科学和艺术的美感
为了方便快速获取nature系列封面,这里用python requests模块进行自动化请求并使用BeautifulSoup模块进行html解析
import requests
from bs4 import BeautifulSoup
import ospath = 'C:\\Users\\User\\Desktop\\nature 封面\\nature 正刊'
if not os.path.exists(path):os.makedirs(path)print("新建文件夹 nature正刊")
start_volume = 501
end_volume = 500
nature_url='https://www.nature.com/nature/volumes/'
kv = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
while start_volume >= end_volume:try:volume_url = nature_url + str(start_volume)volume_response = requests.get(url=volume_url, headers=kv, timeout=120)except Exception:print(str(start_volume) + "请求异常")with open(path + "\\异常.txt", 'at') as txt:txt.write(str(start_volume) + "请求异常\n")continuevolume_response.encoding = 'utf-8'volume_soup = BeautifulSoup(volume_response.text, 'html.parser')ul_tag = volume_soup.find_all('ul',class_='ma0 clean-list grid-auto-fill grid-auto-fill-w220 very-small-column medium-row-gap')img_list = ul_tag[0].find_all("img")issue_number = 0for img_tag in img_list:issue_number += 1filename = path + '\\' + str(start_volume) + '_' + str(issue_number) + '.png'if os.path.exists(filename):print(filename + "已经存在")continueprint("Loading...........................")img_url = 'https:' + img_tag.get("src").replace("w200", "w1000")try:img_response = requests.get(img_url, timeout=240, headers=kv)except Exception:print(start_volume, issue_number, '???????????异常????????')with open(path + "\\异常.txt", 'at') as txt:txt.write(str(start_volume) + '_' + str(issue_number) + "请求异常\n")continuewith open(filename, 'wb') as imgfile:imgfile.write(img_response.content)print("成功下载图片:" + str(start_volume) + '_' + str(issue_number))start_volume -= 1
运行结果:
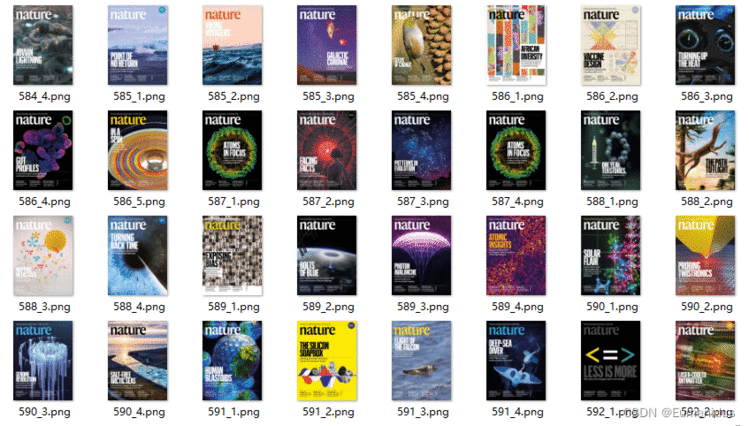
以上部分代码可以自动下载nature和nature genetics的封面,这两个期刊的网站结构跟其他子刊略有不同,其他子刊可以用以下代码来进行爬虫:
import requests
from bs4 import BeautifulSoup
import osother_journals = {'nature biomedical engineering': 'natbiomedeng','nature methods': 'nmeth','nature astronomy': 'natastron','nature medicine': 'nm','nature protocols': 'nprot','nature microbiology': 'nmicrobiol','nature cell biology': 'ncb','nature nanotechnology': 'nnano','nature immunology': 'ni','nature energy': 'nenergy','nature materials': 'nmat','nature cancer': 'natcancer','nature neuroscience': 'neuro','nature machine intelligence': 'natmachintell','nature metabolism': 'natmetab','nature food': 'natfood','nature ecology & evolution': "natecolevol","nature stuctural & molecular biology":"nsmb","nature physics":"nphys","nature human behavior":"nathumbehav","nature chemical biology":"nchembio"
}nature_journal = {'nature plants': 'nplants','nature biotechnology': 'nbt'
}
folder_Name = "nature 封面"
kv = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}def makefile(path):folder = os.path.exists(path)if not folder:os.makedirs(path)print("Make file -- " + path + " -- successfully!")else:raise AssertionError
def getCover(url, journal, year, filepath, startyear&#61;2022, endyear&#61;2022):if not (endyear <&#61; year <&#61; startyear):returntry:issue_response &#61; requests.get("https://www.nature.com" &#43; url,timeout&#61;120,headers&#61;kv)except Exception:print(journal &#43; " " &#43; str(year) &#43; " Error")returnissue_response.encoding &#61; &#39;gbk&#39;if &#39;Page not found&#39; in issue_response.text:print(journal &#43; " Page not found")returnissue_soup &#61; BeautifulSoup(issue_response.text, &#39;html.parser&#39;)cover_image &#61; issue_soup.find_all("img", class_&#61;&#39;image-constraint pt10&#39;)for image in cover_image:image_url &#61; image.get("src")print("Start loading img.............................")image_url &#61; image_url.replace("w200", "w1000")if (image_url[-2] &#61;&#61; &#39;/&#39;):month &#61; "0" &#43; image_url[-1]else:month &#61; image_url[-2:]image_name &#61; nature_journal[journal] &#43; "_" &#43; str(year) &#43; "_" &#43; month &#43; ".png"if os.path.exists(filepath &#43; journal &#43; "\\" &#43; image_name):print(image_url &#43; " 已经存在")continueprint(image_url)try:image_response &#61; requests.get("http:" &#43; image_url,timeout&#61;240,headers&#61;kv)except Exception:print("获取图片异常:" &#43; image_name)continuewith open(filepath &#43; journal &#43; "\\" &#43; image_name,&#39;wb&#39;) as downloaded_img:downloaded_img.write(image_response.content)def main():try:path &#61; os.getcwd() &#43; &#39;\\&#39;makefile(path &#43; folder_Name)except Exception:print("文件夹 --nature 封面-- 已经存在")path &#61; path &#43; folder_Name &#43; "\\"for journal in nature_journal:try:makefile(path &#43; journal)except AssertionError:print("File -- " &#43; path &#43; " -- has already exist!")try:volume_response &#61; requests.get("https://www.nature.com/" &#43;nature_journal[journal] &#43;"/volumes",timeout&#61;120,headers&#61;kv)except Exception:print(journal &#43; " 异常")continuevolume_response.encoding &#61; &#39;gbk&#39;volume_soup &#61; BeautifulSoup(volume_response.text, &#39;html.parser&#39;)volume_list &#61; volume_soup.find_all(&#39;ul&#39;,class_&#61;&#39;clean-list ma0 clean-list grid-auto-fill medium-row-gap background-white&#39;)number_of_volume &#61; 0for volume_child in volume_list[0].children:if volume_child &#61;&#61; &#39;\n&#39;:continueissue_url &#61; volume_child.find_all("a")[0].get("href")print(issue_url)print(2020 - number_of_volume)getCover(issue_url,journal,year&#61;(2020 - number_of_volume),filepath&#61;path,startyear&#61;2022, endyear&#61;2022)number_of_volume &#43;&#61; 1if __name__ &#61;&#61; "__main__":main()print("Finish Everything!")
运行结果&#xff1a;












 京公网安备 11010802041100号
京公网安备 11010802041100号