作者:手机用户2502925983 | 来源:互联网 | 2023-08-25 14:32
随机森林一般不受统计假设、预处理负担、处理缺失值的影响,因此被认为是最实用解决方案的重要起点!Jeremy声称随机森林不适合时间序列数据!通过这篇文章,我们将探索解决随机森林外推问
随机森林一般不受统计假设、预处理负担和缺失值的影响,因此被认为是最实用解决方案的重要出发点!
在杰瑞米霍华德教授讲授的fast.ai机器学习入门课程中,介绍了随机森林中的外推问题。Jeremy声称随机森林不适合时间序列数据!通过这篇文章,我们将探索解决随机森林外推问题的技巧。
然而,我刚刚开始使用谷歌商店预测或出租车费预测等Kaggle竞赛开始使用时间序列数据。令我惊讶的是,我在随机森林中遇到了一个缺点。随机森林不能很好地拟合时间序列分析中经常遇到的增减趋势,比如季节性!
让我用一个例子来说明推断。
让我们为此创建一个复合数据集。(注意:当问题卡住时,创建一个复合数据集,自己尝试!-杰里米的建议)。
x=np.linspace(0,1,num=50)
x是我们的输入,它线性分布在0和1之间,是一个大小为50的向量。
我们的因变量‘y’是‘x’的线性函数,带有一些随机噪声以增加方差。随机噪声在一定程度上模仿了真实世界的场景。
y=x np.random.uniform(-0.2,0.2,x.shape)
让我们画出x和y。
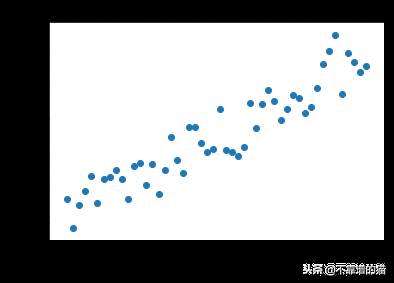
很明显,“X”和“Y”之间存在线性关系,并且呈上升趋势。
这可能与实际用例中的增长趋势——非常相似,例如10月、11月和12月的销售增长,或者2019年的世界人口增长等。
杰里米声称,用这样的数据拟合随机森林不会给我们带来好的结果。然后,让我们试试随机森林,看看会发生什么!
X_train,X_val=x[:40],x[40:]
y_train,y_val=y[:40],y[40:]
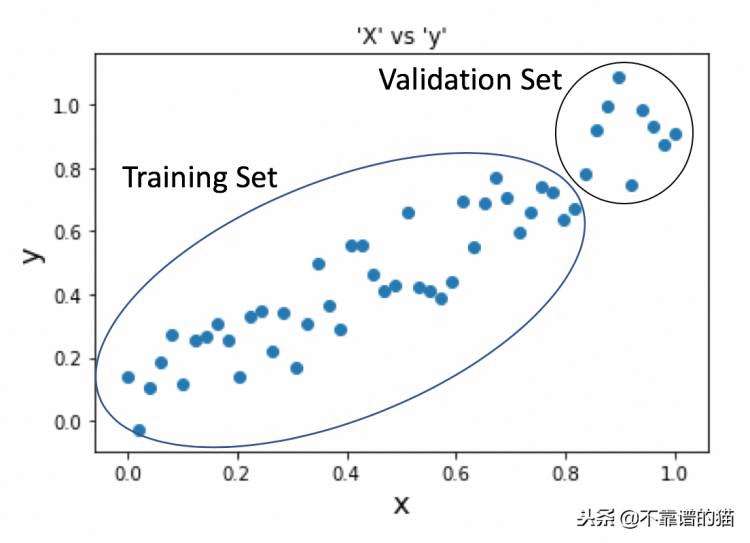
我们将把我们的随机森林回归应用于训练数据,并首先探索它与X_train预测的关系,然后是X_val
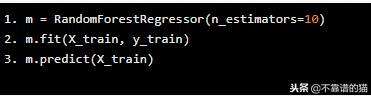

我们的随机森林似乎在训练数据方面做得非常好!
现在,让我们进入有趣的部分,预测X_val。记住,我们的随机森林以前从未见过这个数据。当我们预测和验证数据时,你预计会发生什么?

我们的随机森林无法预测它从未见过的价值!它预测所有验证数据的因变量值为0.65。
为什么预测值明显小于我们验证集的实际值,而它对训练数据却非常有效呢?要回答这个问题,可能需要深入研究随机森林的运行模式。我们将从艾姆斯住房数据中获得帮助来解释答案。
随机森林构成决策树(弱分类器),它本身是关于训练数据的二元分裂(决策)的组合。直觉上,你可以认为这是一种将你最近的邻居分组的奇怪方式。决策树将可能属于同一个价格类别的房子聚集在一起,即通过对房子进行分组,将昂贵的房子与便宜的房子分开。整体质量7.5、居住面积1970.5的房屋(67个样板间/间)集中在底部叶节点。对于落在叶子中验证集的任何房子,预测值是67个样本的平均值,即12.775。
随机森林由决策树(弱分类器)组成,它是二叉树(决策树)对训练数据的组合。直觉上,你可以认为这是一种将你最近的邻居分组的奇怪方式。决策树对可能属于同一价格类别的房屋进行分组,即通过对房屋进行分组来区分昂贵的房屋和便宜的房屋。居住面积OverallQua7.5 1970.5的房屋(67个样板间/房屋)在底部叶节点分组在一起。对于落在叶子中验证集的任何房子,预测值是67个样本的平均值,即12.775。
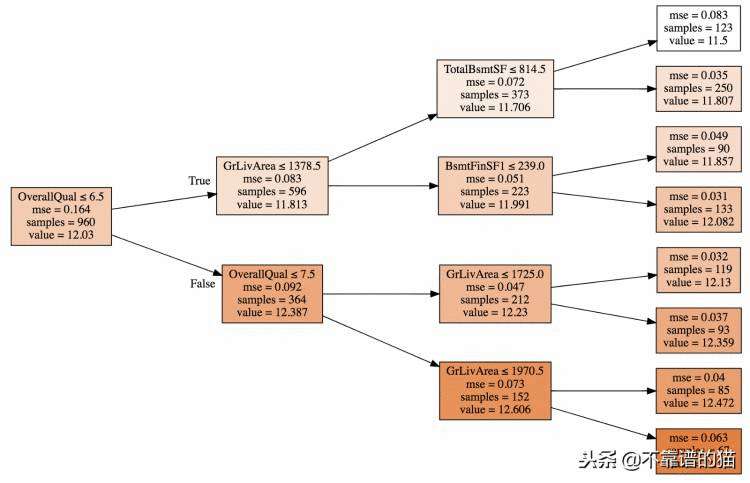
ass="pgc-img-caption">一个简单的决策树(Ames住房数据)
对于任何随机森林以前没有见过的数据,它最多只能预测它以前见过的训练值的平均值。如果验证集由大于或小于训练数据点的数据点组成,那么随机森林无法推断和理解数据中的增长/下降趋势,因此它将为我们提供平均结果。
因此,随机森林模型对于时间序列数据不能很好地扩展,可能需要在生产中不断更新,或者使用一些超出我们训练集范围的随机数据进行训练。
回答诸如“明年的销售额会是多少?”,“五年后人口会是多少?”,“50年后全球气温会是多少?”或者“我希望在未来三个月内卖出多少套手套?”“在使用随机森林时变得非常困难。
如何解决这个外推问题?
1.寻找其他选择
在这种情况下拟合线性模型或神经网络可能足以预测具有增加/减少趋势的数据。
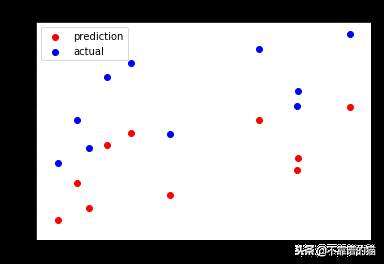
当我在相同的数据集上拟合线性回归模型时,结果是这样的。也可以拟合一个可用于需求预测或任何其他类型的时间序列图的神经网络。
2.在训练随机森林时忽略数据的时间序列成分
另一种可能的方法来改进泛化(我们说如果一个模型很好地预测它以前没有见过的数据,机器学习中的一个主要挑战是创建可泛化且通用的强大机器学习(ML)模型):我们的模型能够预测未来的数据是不使用可能与时间成分相关的数据中的特征。我们的输入矩阵可能具有各种用于预测因变量的特征。如果我们不将时间相关的特征用于我们的预测,我们的随机森林模型将能够很好地泛化!
举一个例子,Kaggle上的the Bluebook for Bulldozers竞赛,其目的是预测未来几个月重型设备的“价格”。在检查竞赛的特征重要性时,我们得到下表:
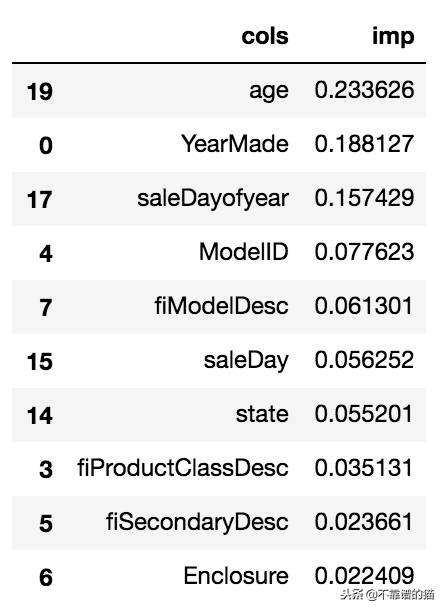
最重要的特征是Age,YearMade和SaleDayofyear都是时间依赖的!这可能也是一个很好的时机来表明验证LRMSE得分为0.249366,具有上述特征重要性。
如果我们放弃这些依赖于时间的特征,我们的验证分数会发生什么改变呢?它下降到0.210967!
我们的模型更好地泛化,因此,我们看到验证集的LRMSE有所减少。
进一步改进:使用随机森林进一步改进预测的另一个想法是使用时间序列预测来flatten季节性,然后使用随机森林进行预测。








 京公网安备 11010802041100号
京公网安备 11010802041100号