点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
图注意力网络的一作 Petar Veličković接过了接力棒,也在 Twitter 上晒出了自己的博士论文。这些大神是约好了吗?

在一项针对 2019 年到 2020 年各大顶会论文关键词的统计中,「图神经网络」的增长速度位列榜首,成为上升最快的话题。
在图神经网络出现之前,尽管深度学习已经在欧几里得数据中取得了很大的成功,但从非欧几里得域生成的数据得到了更广泛的应用,它们也需要有效的分析,由此催生了图神经网络。
图神经网络最初由 Franco Scarselli 和 Marco Gori 等人提出,在之后的十几年里被不断扩展,先后发展出了图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks)、图自编码器( Graph Autoencoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks)等多个子领域。
每个子领域都有一些拓荒者,比如前文提到的 Thomas Kipf,他和 Max Welling 一起开辟了图卷积网络。而今天这篇博士论文的作者 Petar Veličković是图注意力网络的一作,他和 Guillem Cucurull、Yoshua Bengio 等人一起完成了图注意力网络的开山之作——《Graph Attention Networks》,这篇论文被 ICLR 2018 接收。发布两年后,该论文被引量已超过 1300。
Petar Veličković现在是 DeepMind 的研究科学家。他于 2019 年从剑桥大学获得计算机科学博士学位,导师为 Pietro Liò。他的研究方向包括:设计在复杂结构数据上运行的神经网络架构(如图网络),及其在算法推理和计算生物学方面的应用。除了图注意力网络,他还是《Deep Graph Infomax》的一作。在这篇论文中,他和 William Fedus、Yoshua Bengio 等人提出了以无监督方式学习图结构数据中节点表示的通用方法,该论文被 ICLR 2019 接收。
Petar Veličković的博士论文去年就已经完成,只是最近才跟大家分享。这篇论文的题目是《The resurgence of structure in deep neural networks》,共计 147 页,涵盖了 Petar Veličković的上述经典工作和其他关于图神经网络的内容,非常值得一读。

论文链接:https://www.repository.cam.ac.uk/handle/1810/292230
机器之心对该论文的核心内容进行了简要介绍,感兴趣的读者可以阅读原论文。
摘要
深度学习赋予了模型直接从原始输入数据学习复杂特征的能力,完全去除了手工设计的 “硬编码” 特征提取步骤。这使得深度学习在计算机视觉、自然语言处理、强化学习、生成建模等之前互不相关的多个领域实现了 SOTA 性能。这些成功都离不开大量标注训练数据(「大数据」),这些数据具备简单的网格状结构(如文本、图像),可通过卷积或循环层加以利用。这是由于神经网络中存在大量的自由度,但同时也导致其泛化能力很容易受到过拟合等因素的影响。
然而,还有很多领域不适合大量收集数据(成本高昂或本身数据就很少)。而且,数据的组织结构通常更加复杂,多数现有的方法干脆舍弃这些结构。这类任务在生物医学领域比较常见。Petar 在论文中假设,如果想要在这种环境下完全发挥深度学习的潜力,我们就需要重新考虑「硬编码」方法——将关于输入数据固有结构的假设通过结构归纳偏置直接合并到架构和学习算法中。
在这篇论文中,作者通过开发三种 structure‐infused 神经网络架构(在稀疏多模态和图结构数据上运行)和一种 structure‐informed 图神经网络学习算法来直接验证该假设,并展示了传统基线模型和算法的卓越性能。
重新引入结构归纳偏置
这篇文章的主要贡献是,缓解了在有额外结构信息可供利用的任务中可能出现的上述问题。利用关于数据的额外知识的一种常见方法是对模型应用适当的归纳偏置。
通常来讲,给定特定的机器学习设置,我们可以为该学习问题找到一个可能解的空间,该空间中的解都具备「不错」的性能。但一般来说,归纳偏置鼓励学习算法优先考虑具有某些属性的解。虽然有很多方法可以编码这些偏置,但作者将目光聚焦于将结构性假设直接合并到学习架构或算法中。这可以看作一种「meet‐in‐the‐middle」方法,即将经典的符号人工智能与当前的深度架构相融合。
通过直接编码数据中出现的结构归纳偏置,作者使模型更加数据高效,实现了预测能力的飞跃——尤其是在较小的训练数据集上。作者表示,这些并不是孤立的成果,而是代表了机器学习社区近期取得的一大进展。
研究问题与贡献
作者在论文中介绍了自己重点研究的三个问题,以及针对这三个问题所作的具体贡献,如下图 1.3 所示。
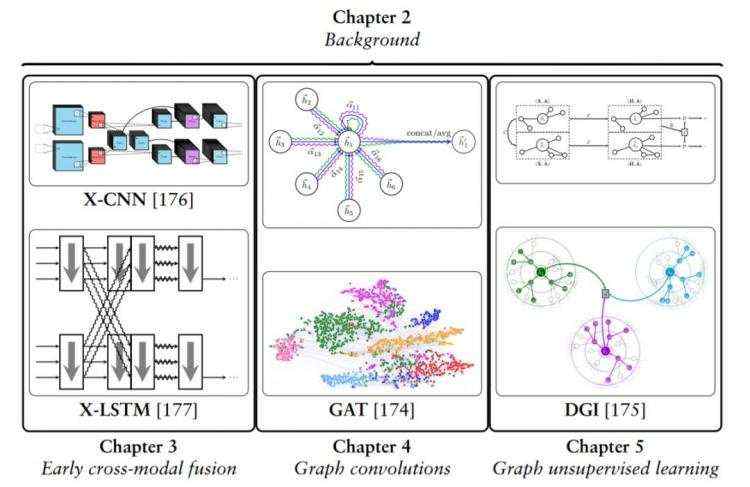
图 1.3:论文主要贡献概览。
首先,他提出了两种具备专门结构归纳偏置的模型,用于多模态学习的早期融合。一种是网格结构输入模态(X‐CNN),另一种是序列输入模态(X‐LSTM)。
接下来,他概述了图卷积层的期望结构归纳偏置,并首次表明这在图注意力网络中可以得到同时满足。
最后,作者提出通过 Deep Graph Infomax 算法,将局部互信息最大化作为图结构输入的无监督学习目标,从而引入非常强大的结构归纳偏置,结合图卷积编码器来学习节点表征。
问题一
Q1:研究用于多模态神经网络早期融合的可行候选层,并评估它们在困难学习环境下的实际可部署性和优势,特别是当输入数据稀疏或不完整时。
在该论文第三章和《X-CNN: Cross-modal convolutional neural networks for sparse datasets》、《Cross-modal Recurrent Models for Weight Objective Prediction from Multimodal Time-series Data》两篇论文中,Petar 提出了两种跨模态神经网络架构,可以在模态间执行早期融合,二者分别在网状(X-CNN)和序列(X‐LSTM)输入模态上运行。这些方法主要靠允许单独的模态流交换中间特征,从而更容易利用模态之间的相关性,还能保持全连接神经网络「数据流不受限」的特性,即使模型参数量要小得多。结果表明,这些方法比传统方法有更好的表现,特别是在训练集较小和输入不完整的情况下。
同时,Petar 还重点介绍了自己参与指导的两项相关工作。一项是将特征交换泛化至 1D‐2D 情况,在视听分类中获得了很好的结果。另一项工作则表明,尽管像 X-CNN 这类模型超参数数量有所增加,但这些超参数可以使用自动化步骤进行高效调节。
问题二
Q2:研究卷积算子从图像到显示图结构的输入的泛化(即图卷积层),清晰地描绘出这种算子的期望特性。是否有模型能够同时满足所有特性?这些理论上的特性在实践中能否表现良好?
在论文第四章和《Graph Attention Networks》中,Petar 回顾了 CNN 的优点,详细阐述了图卷积层的期望特性,并评估了为什么此前提出的这类模型需要牺牲掉其中的某些特性。然后,作者定义了图注意力网络 (GAT) ,它将自注意力算子泛化至图领域。他得出的结论是:在这种设定下,自注意力拥有所有期望特性。作者将该模型部署到多个标准节点分类基准上,发现与其他方法相比,该模型的性能非常有竞争力。
问题三
Q3:图卷积网络在何种程度上对于图结构数据的无监督学习是有意义的?在形式化图无监督目标时,是否可以有效利用图的全局结构属性?
论文第五章和《Deep Graph Infomax》研究了此前基于图进行无监督表征学习的方法(主要基于随机游走),发现这些方法不太适合与图卷积编码器结合使用。
基于图像领域局部互信息最大化的之前工作,作者提出了针对图结构输入的 Deep Graph Infomax (DGI) 学习算法。该无监督目标使图的每个局部组件都能完美地记住图的全局结构属性。结果表明,该模型在生成节点嵌入方面与使用监督目标训练的类似编码器性能相当,甚至更优。
除了介绍作者的主要研究贡献以外,这篇博士论文还对深度神经网络的背景信息进行了全面概括(第 2 章),尤其提供了具备结构归纳偏置的相关模型的基本数学细节(从 CNN 和 RNN 再到图卷积网络)。论文第六章对全文进行了总结,并描述了未来的工作方向。
以下是这篇博士论文的目录:



---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


如何画出漂亮的深度学习模型图?
如何画出漂亮的神经网络图?
一文读懂深度学习中的各种卷积
点个在看支持一下吧







 京公网安备 11010802041100号
京公网安备 11010802041100号