深度学习(17)—— 度量学习
文章目录
- 深度学习(17)—— 度量学习
- 一、What?
- 二、paired-based loss
- 1. Contrastive loss
- 2. Triplet loss
- 3. Triplet center loss
- 4.N-pair loss
- 5. Quadruplet loss
- 6. Lifted Structure Loss
昨天讨论的时候一个大佬提到了Metric Learning,听他讲了一下大致思路,觉得有点意思,所以下来了解了一下,简单记录
一、What?
度量学习是一种空间映射的方法,它可以学习到一种特征空间(Embedding),会将所有的数据转化为一个共同空间中的特征向量,在这些向量中,越相似样本的特征向量距离越近,不相似的样本的特征向量之间距离大,将数据进行区分。
二、paired-based loss
1. Contrastive loss
Contrastive loss能够让正样本(越相似的样本)对尽可能的近,负样本对尽可能的远,这样可以增大类间差异,减小类内差异。但是其需要指定一个固定的margin,因为margin是固定的,所以这里就隐含了一个很强的假设,即每个类目的样本分布都是相同的,不过一般情况下这个强假设未必成立。
例如,有一个数据集有三种动物,分别是狗、狼 、猫,直观上狗和狼比较像,狗和猫的差异比较大,所以狗狼之间的margin应该小于狗猫之间的margin,但是Contrastive loss使用的是固定的margin,如果margin设定的比较大,模型可能无法很好的区分狗和狼,而margin设定的比较小的话,可能又无法很好的区分狗和猫。
2. Triplet loss
Triplet Loss的思想是让负样本对之间的距离大于正样本对之间的距离,在训练过的过程中同时选取一对正样本对和负样本对,且正负样本对中有一个样本是相同的。仍旧以前面的狗、狼、猫数据为例,首先随机选取一个样本,此样本称之为anchor 样本,假设此样本类别为狗,然后选取一个与anchor样本同类别的样本(另一个狗狗),称之为positive,并让其与anchor样本组成一个正样本对(anchor-positive);再选取一个与anchor不同类别的样本(猫),称之为negative,让其与anchor样本组成一个负样本对(anchor-negative)。
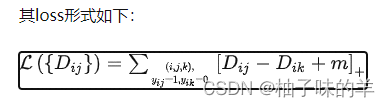
当负样本对之间的距离比正样本对之间的距离大m的时候,loss为0 ,认为当前模型已经学的不错了,所以不对模型进行更新。
3. Triplet center loss
Triplet Center loss的思想非常简单,原来的Triplet是计算anchor到正负样本之间的距离,现在Triplet Center是计算anchor到正负样本所在类别的中心的距离。类别中心就是该类别所有样本embedding向量的中心

4.N-pair loss
N-pair loss选取了多个负样本对,即一对正样本对,选取其他所有不同类别的样本作为负样本与其组合得到负样本对。如果数据集中有N个类别,则每个正样本对Yii 都对应了N-1个负样本对。
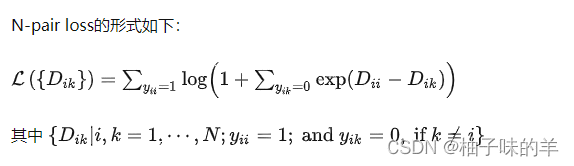
5. Quadruplet loss
Quadruplet loss由两部分组成:
- 一部分就是正常的triplet loss,这部分loss能够让模型区分出正样本对和负样本对之间的相对距离。
- 另一部分是正样本对和其他任意负样本对之前的相对距离。这一部分约束可以理解成最小的类间距离都要大于类内距离,不管这些样本对是否有同样的anchor
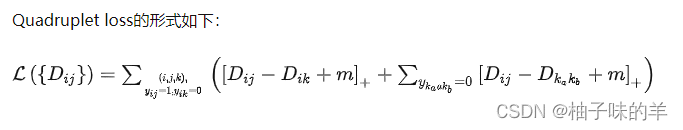
6. Lifted Structure Loss
Lifted Structure loss的思想是对于一对正样本对而言,不去区分这个样本对中谁是anchor,谁是positive,而是让这个正样本对中的每个样本与其他所有负样本的距离都大于给定的阈值。此方法能够充分的利用mini-batch中的所有样本,挖掘出所有的样本对。






 京公网安备 11010802041100号
京公网安备 11010802041100号