引言
本文将解释一个卷积神经网络(CNN)的一般结构,从而有助于了解如何分类不同类别的图像(在我们的案例中不同类型的动物) ,使用 PyTorch 从头开始编写一个 CNN 模型。
先决条件
-
Python 基础知识
-
对神经网络的基本理解
-
对卷积型神经网络(CNN)的基本理解
使用的数据集
Animals-10 数据集,小伙伴们可以从这个网址中下载:https://www.kaggle.com/alessiocorrado99/animals10
开始编程
步骤1:(下载数据集)

步骤2:(创建数据集和数据加载器来加载这些图像)dataset_path = 'BasicCNN_Pytorch/raw-img'
mean = torch.tensor([0.485, 0.456, 0.406], dtype=torch.float32)std = torch.tensor([0.229, 0.224, 0.225], dtype=torch.float32)# Transformation function to be applied on images# 1. Horizontally Flip the image with a probability of 30%# 2. Randomly Rotate the image at an angle between -40 to 40 degress.# 3. Resize each images to a smallest size of 300 pixels maintaining aspect ratio# 4. Crop a square of size 256x256 from the center of image# 5. Convert Image to a Pytorch Tensor# 6. Normalize the pytorch's tensor using mean & std of imagenettransform = transforms.Compose([ transforms.RandomHorizontalFlip(p=0.3), transforms.RandomRotation(degrees=40),
transforms.Resize(300), transforms.CenterCrop(256),
transforms.ToTensor(), transforms.Normalize(mean=mean, std=std)])
# Create a dataset by from the dataset folder by applying the above transformation.dataset = torchvision.datasets.ImageFolder(dataset_path, transform=transform)# Split the dataset into train & test containing 21000 and 5179 images respectively.train_dataset, test_dataset = torch.utils.data.random_split(dataset, (21000, 5179))
# Create a Train DataLoader using Train Datasettrain_dataloader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=16, shuffle=False, num_workers=4)# Create a Test DataLoader using Test Datasettest_dataloader = torch.utils.data.DataLoader( dataset=test_dataset, batch_size=16, shuffle=False, num_workers=4)
步骤3:创建 CNN 模型架构
让我们创建一个简单的 CNN 模型架构。
class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.model = nn.Sequential( nn.Conv2d(3, 16, kernel_size=3), nn.ReLU(), nn.Conv2d(16, 16, kernel_size=3), nn.ReLU(), nn.MaxPool2d(2,2),
nn.Conv2d(16, 32, kernel_size=3), nn.ReLU(), nn.Conv2d(32, 32, kernel_size=3), nn.ReLU(), nn.MaxPool2d(2,2),
nn.Conv2d(32, 64, kernel_size=3), nn.ReLU(), nn.Conv2d(64, 64, kernel_size=3), nn.ReLU(), nn.MaxPool2d(2,2),
nn.Conv2d(64, 128, kernel_size=3), nn.ReLU(), nn.Conv2d(128, 128, kernel_size=3), nn.ReLU(), nn.MaxPool2d(2,2),
nn.Conv2d(128, 256, kernel_size=3), nn.ReLU(), nn.Conv2d(256, 256, kernel_size=3), nn.ReLU(), nn.MaxPool2d(2,2),
).to(device) self.classifier = nn.Sequential( nn.Flatten(), nn.Dropout(0.25), nn.Linear(4096, 256), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(256, 10) ).to(device) def forward(self, x): x = self.model(x) x = self.classifier(x) return xmodel = MyModel().to(device)summary(model, (3,256,256))
像所有一般的 CNN 体系结构一样,我们的模型也有两个组件:
-
一组卷积后面跟着一个激活函数(在我们的例子中使用 ReLU)和一个最大池层
-
一个线性分类层,将图像分为3类(猫,狗和熊猫)
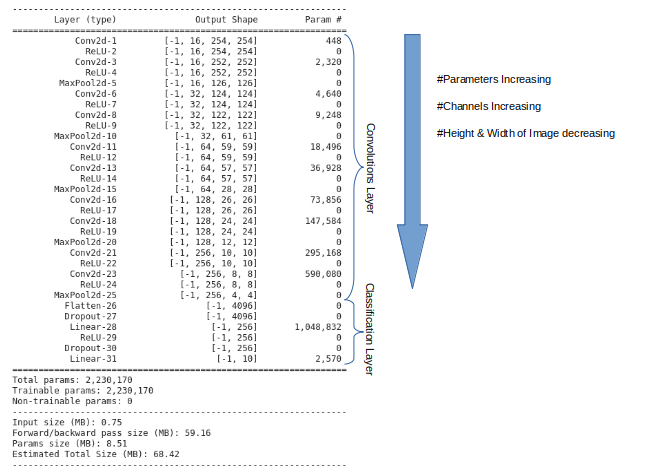
CNN 模型架构
-
该模型包含大约223万个参数
-
当我们沿着卷积层向下走时,我们观察到通道的数量从3个(RGB 图像)增加到16个、32个、64个、128个,然后增加到256个
-
ReLU 层在每次卷积运算后提供非线性操作
-
由于我们的最大池化层,因此随着通道数目的增加,图像的高度和宽度也随之减小
-
我们在我们的分类层添加了 dropout,防止模型过拟合
步骤4:定义模型、优化器和损失函数
我们使用了学习率为0.0001的 Adam 优化器和交叉熵损失函数。
lr = 0.0001model = MyModel().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)criterion = nn.CrossEntropyLoss()
步骤5:开始训练
终于到了我们都在等待的时刻,也就是训练模型的时刻。对于训练和测试,我创建了这两个辅助函数。
def Train(epoch, print_every=50): total_loss = 0 start_time = time() accuracy = [] for i, batch in enumerate(train_dataloader, 1): minput = batch[0].to(device) # Get batch of images from our train dataloader target = batch[1].to(device) # Get the corresponding target(0, 1 or 2) representing cats, dogs or pandas moutput = model(minput) # output by our model loss = criterion(moutput, target) # compute cross entropy loss total_loss += loss.item()
optimizer.zero_grad() # Clear the gradients if exists. (Gradients are used for back-propogation.) loss.backward() # Back propogate the losses optimizer.step() # Update Model parameters argmax = moutput.argmax(dim=1) # Get the class index with maximum probability predicted by the model accuracy.append((target==argmax).sum().item() / target.shape[0]) # calculate accuracy by comparing to target tensor
if i%print_every == 0: print('Epoch: [{}]/({}/{}), Train Loss: {:.4f}, Accuracy: {:.2f}, Time: {:.2f} sec'.format( epoch, i, len(train_dataloader), loss.item(), sum(accuracy)/len(accuracy), time()-start_time )) return total_loss / len(train_dataloader) # Returning Average Training Loss
def Test(epoch): total_loss = 0 start_time = time()
accuracy = [] with torch.no_grad(): # disable calculations of gradients for all pytorch operations inside the block for i, batch in enumerate(test_dataloader): minput = batch[0].to(device) # Get batch of images from our test dataloader target = batch[1].to(device) # Get the corresponding target(0, 1 or 2) representing cats, dogs or pandas moutput = model(minput) # output by our model
loss = criterion(moutput, target) # compute cross entropy loss total_loss += loss.item() # To get the probabilities for different classes we need to apply a softmax operation on moutput argmax = moutput.argmax(dim=1) # Find the index(0, 1 or 2) with maximum score (which denotes class with maximum probability) accuracy.append((target==argmax).sum().item() / target.shape[0]) # Find the accuracy of the batch by comparing it with actual targets print('Epoch: [{}], Test Loss: {:.4f}, Accuracy: {:.2f}, Time: {:.2f} sec'.format( epoch, total_loss/len(test_dataloader), sum(accuracy)/len(accuracy), time()-start_time )) return total_loss/len(test_dataloader) # Returning Average Testing LossHosted on Jovian
现在让我们开始训练:
感谢我们在上面创建的 helper 函数,我们可以使用下面的代码片段轻松地开始训练过程。
Test(0)
train_loss = []test_loss = []
for epoch in range(1, 51): train_loss.append(Train(epoch,200)) test_loss.append(Test(epoch))
print('\n') if epoch % 10 == 0: torch.save(model, 'model_'+str(epoch)+'.pth')
我们正在训练该模型50个 epoch,并在每10个 epoch 之后将其保存到磁盘。
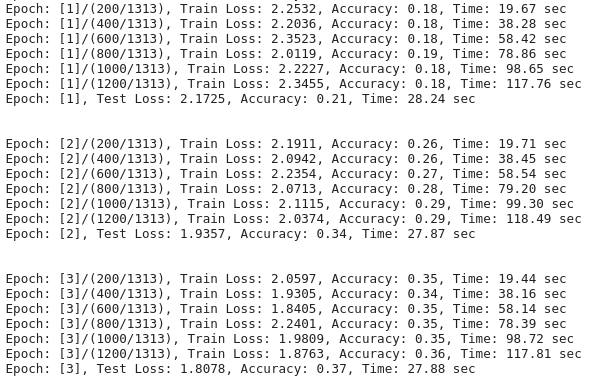
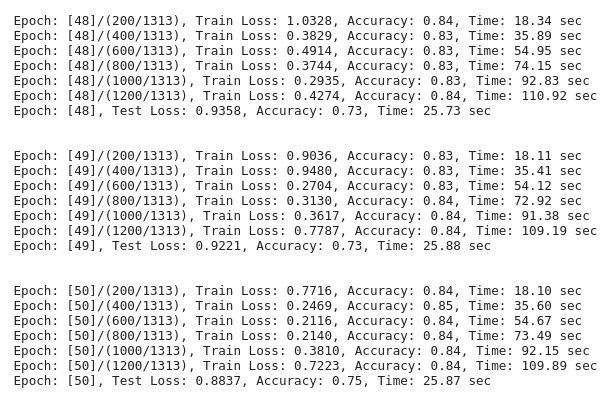
这是我们在训练中得到的输出(部分):
-
在谷歌 colab 使用 Tesla T4 GPU 训练这个步骤花了大约2个小时(50个 epoch);
-
正如我们可以看到的,准确率从第1个 epoch 后的21% 上升到第50个 epoch 后的75% 。(经过另外50个 epoch 的训练,准确率达到了78%)
-
我们非常基本的 CNN 模型只有2.23 M 的参数
评估模型
我们绘制一下训练和测试损失:
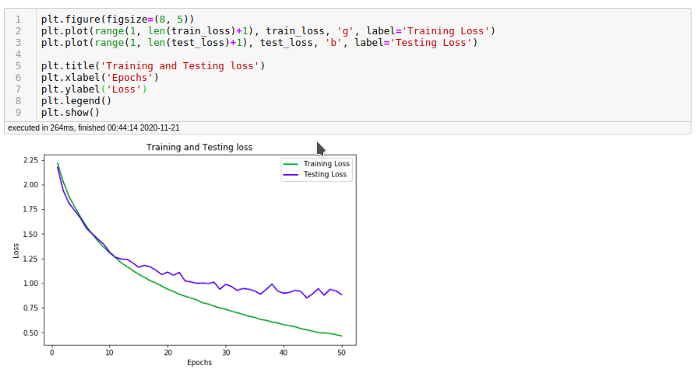
现在让我们用一些随机的图片来测试一下。

· END ·
原文 https://mp.weixin.qq.com/s/m8w_G4ea7oOb3J-J7rxQ3A










 京公网安备 11010802041100号
京公网安备 11010802041100号