点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达本文转自|AI公园
导读
Google出品的超市商品解决方案。
用户面临的最大挑战之一是如何在视觉信息不完整的情况下识别包装食品,无论是在杂货店还是在他们家里的厨房橱柜中。这是因为许多食品都使用相同的包装,比如盒子、罐头、瓶子和罐子,只是在标签上印刷的文字和图像有所不同。然而,智能移动设备的普遍存在为使用机器学习(ML)解决这些挑战提供了机会。
近年来,移动设备上的神经网络对于各种感知任务的准确性有了显著的提高。再加上现代智能手机不断增强的计算能力,现在许多视觉任务在完全运行于移动设备上的情况下产生高性能是可能的。部署在设备内的模型,如MnasNe和MobileNets(基于resource-aware架构搜索)结合设备内置索引,可以运行一个完整的计算机视觉系统,比如有标签的产品识别,而且是完整的实时的运行在设备上。
利用诸如此类的发展,我们最近发布了Lookout,这是一款使用计算机视觉的Android应用程序,使视觉受损的用户更容易访问物理世界。当用户将智能手机摄像头对准产品时,Lookout会识别出该产品,并大声说出品牌名称和产品尺寸。为了实现这一点,Lookout包括一个超市产品检测和识别模型,该模型带有设备上的产品索引,以及MediaPipe物体跟踪和一个OCR识别模型。由此产生的架构足够高效,可以完全在设备上实时运行。
为什么是On-Device?
完全运行在设备上的系统具有低延迟和不依赖网络连接的优点。然而,这意味着一个产品识别系统要真正对用户有用,它必须有一个具有良好产品覆盖范围的设备数据库。这些需求驱动了所使用的数据集的设计,其中包括根据用户地理位置动态选择的200万个流行产品。
传统的解决方案
使用计算机视觉的产品识别传统上是使用SIFT算法提取的局部图像特征来解决的。这些基于非机器学习的方法提供了相当可靠的匹配,但是每个索引图像都需要大量存储空间(通常为每个图像10KB到40KB),并且对于光线不好和图像模糊不太健壮。此外,这些描述符的本地特征意味着它通常不会捕捉产品外观的更多的全局特征。
另一种有许多优点的替代方法是使用机器学习并在查询图像和数据库图像上运行一个OCR系统来提取产品包装上的文本。可以使用N-Grams将查询图像上的文本匹配到数据库,以防止OCR错误,如拼写错误、错误识别、产品包装上的单词识别失败。N-Grams还允许使用诸如Jaccard相似系数等度量方法在查询文档和索引文档之间进行部分匹配,而不是要求精确匹配。但是,使用OCR时,索引文档的大小可能会增长得非常大,因为需要存储产品包装文本的n个符号以及其他信号,比如TF-IDF。此外,匹配的可靠性是OCR+N-Gram方法的一个问题,因为在两种不同产品的包装上有很多常见单词的情况下,它很容易过度触发。
与SIFT和OCR+N-Gram方法相比,我们基于神经网络的方法生成一个全局描述符(即嵌入),对于每个图像,只需64字节,大大减少了存储需求,而对于每个SIFT特征索引条目,每个图像需要10-40KB的存储空间,或者对于不太可靠的OCR+N-gram方法,每个图像需要几个KBs的存储空间。通过为每个索引使用更少的字节,可以将更多的产品包括在索引中,从而产生更完整的产品覆盖率和更好的总体用户体验。
设计
Lookout系统由帧缓存、帧选择器、检测器、目标跟踪器、嵌入器、索引检索器、OCR、评分器和结果显示器组成。
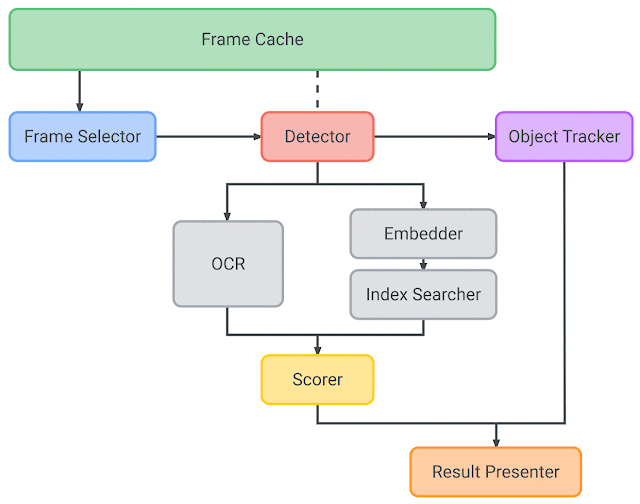
帧缓存
帧缓存管理管道中输入相机图像帧的生命周期。它根据其他模型组件的请求有效地交付数据,包括YUV/RGB/灰度图像,并管理数据的生命周期,以避免多个组件请求的相同相机帧的重复转换。
帧选择器
当用户将相机取景器指向一个产品时,一个基于轻量级的IMU的帧选择器作为预过滤阶段在运行。它根据角速度(deg/sec)测量出的抖动,从连续输入的图像流中选择最符合某一质量标准的帧(例如,平衡图像质量和延迟)。该方法通过有选择地只处理高质量的图像帧,跳过模糊的图像帧来最小化能量消耗。
检测器
然后,每个选定的帧被传递给产品检测器模型,该模型提出感兴趣的区域(检测出来的包围框)。检测器模型是一个使用MnasNet主干的single-shot检测器,它在高质量和低延迟之间取得平衡。
物体跟踪
MediaPipe Box tracking用来实时的跟踪检测框,对于填补不同帧目标检测之间的空白,降低检测频率,从而降低能耗起着重要作用。物体跟踪器还维护一个物体映射,其中每个物体在运行时被分配一个唯一的物体ID,之后被结果显示器用来区分物体和避免对重复的单个物体确认。对于每个检测结果,跟踪器要么在映射中注册一个新物体,要么用检测到的边界框更新一个现有物体,在检测结果的现有物体边界框之间使用IoU进行匹配。
嵌入器
来自检测器的感兴趣区域(ROIs)被发送到embedder模型,然后该模型计算64维的嵌入。embedder模型最初是从一个大的分类模型(即teacher模型,基于NASNet),它包含了数万个类别。模型中添加嵌入层,将输入图像投影到一个“嵌入空间”中,即嵌入层。在向量空间中,两点接近意味着它们所代表的图像在视觉上是相似的(例如,两幅图像表示相同的产品)。仅对嵌入进行分析可以确保模型是灵活的,并且不需要在每次扩展到新产品时进行再训练。但是,由于教师模型太大,无法直接在设备上使用,因此我们使用它生成的嵌入内容来训练一个更小的、便于移动的student模型,该模型学会将输入图像映射到与教师网络相同的嵌入空间点上。最后,我们应用主成分分析 (PCA)将嵌入向量的维数从256降至64,简化了存储在设备上的嵌入。
索引搜索器
索引检索器使用查询嵌入在预先构建的索引上执行KNN搜索。结果,它返回最顶端的索引文档,其中包含它们的元数据,比如产品名称、包装大小等。为了减少索引查找延迟,所有嵌入都是使用k-means进行了聚类。在查询时,相关的数据簇被加载到内存中进行实际的距离计算。为了在不牺牲质量的前提下减小了索引的大小,我们在索引时使用了乘积量化。
OCR
对每个相机帧的ROI执行OCR,以提取额外的信息,如包装的大小、产品口味的变化等。传统的解决方案使用OCR结果进行索引搜索,而在这里我们只使用它进行评分。由OCR文本辅助的合适的评分算法帮助评分器确定正确的结果并提高精度,特别是在多个产品具有类似包的情况下。
评分器
评分器从嵌入(带有索引结果)和OCR模块获取输入,并对之前检索到的索引文档(通过索引搜索器检索出来的嵌入和元数据)进行评分。评分后的最高结果作为系统的最终识别结果。
结果显示
结果显示器接收上面的所有结果,并通过文本转换成语音的服务说出产品名称,将结果呈现给用户。

总结/未来的工作
这里列出的on-device系统可以用来实现一系列新的店内体验,包括详细的产品信息(营养成分、过敏原等)的显示、客户评级、产品比较、智能购物清单、价格跟踪等等。我们很高兴能够探索这些未来的应用,同时继续研究提高基础设备模型的质量和健壮性。

—END—
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~










 京公网安备 11010802041100号
京公网安备 11010802041100号