作者:爷W很幸福_448 | 来源:互联网 | 2023-09-17 23:32
目录
一、串行互连
二、并行互连
三、串行与并行互连的比较
四、互连标准接口
(1)背景
(2)UCIe
Chiplet的可行性常常受到片间互连的性能、可用性以及功耗和成本问题的限制,各种异构芯片的互连接口和标准的设计在技术和市场竞争方面难以实现性能和灵活性间的平衡。
多年来,业内一直在寻找一种“真正的互连”,以便在单个MCM(Multi Chip Module多芯片模块)中实现从裸片到裸片的通信,更好的完成数据存储、信号处理、数据处理等丰富的功能。如何让裸片与裸片之间高速互连,是Chiplet技术落地的关键,也是全产业链目前的一大全新挑战。
互连是chiplet技术的核心问题之一。硅基板、有机基板或者其他材料的基板,为Chiplet之间提供了不同性能的物理连接通道,这也影响Chiplet之间互连接口电路的设计实现方式。Chiplet在物理层中使用的互连接口可分为两类:串行互连和并行互连。
一、串行互连
串行互连技术(SerDes)具有IO数量少,传输距离远和速度快等优点,目前广泛应用于系统或者芯片之间的高速互连。传统的SerDes收发系统由编码与发送电路、传输线、接收与解码电路组成。在发送端,多路低速并行信号经过编码转换成高速串行信号,在接收端高速串行信号解码转换成并行信号。为了解决高速传输过程中信号在传输线中的衰落和干扰问题,发送电路一般需要增前馈均衡(FFE)电路,接收电路则使用判决反馈均衡电路(DFE)或者连续时间线性均衡器(CTLE)。
SerDes串行互连技术采用差分信号传输方式实现了数据的高速传输,具有功耗低、抗干扰强、速度快的优点。根据发射端与接收端之间的距离,互连的SerDes技术可细分为长距 (LR) SerDes、 中 距 (MR) SerDes、 短 距 (VSR)SerDes、极短 (XSR) SerDes 和超短距 (USR) SerDes。其中,LR/MR/VSR SerDes 的相关技术已经较为成熟,应用比较广泛,封装成本也较低,但缺点是功耗和信号的延迟比较大。XSR 的光网络论坛-通用电气接口规范 (OIF-CEI 4.0)是专门针对Die之间互连的,并向着100 Gbit/s的方向发展。相较于LR Serdes,XSR Serdes具有功耗低、面积小、通信协议灵活的特点。USR SerDes 通过信号增强可进一步降低SerDes的功耗。封装产品可以根据不同项目产品的需求选择合适的SerDes类型,以实现成本与带宽的平衡。
- LR/MR/VSR SerDes通常用于芯片间连接和芯片与模块连接,被广泛用于PCI-E、以太网和RapidIO等通信接口。这些接口的主要特点是可靠,传输距离长,成本低以及易于集成。然而,由于这些接口在功耗,面积和延迟方面没有优势,因此难以支持对此有高要求的高性能芯片的构造。
- XSR SerDes为“Die-to-Die”(D2D)和“Die-to-Optical”(D2OE)的互连提供了相应的SerDes标准,现有标准速率正在从50Gbps向100Gbps速率过度。XSR SerDes不需要复杂的均衡算法,不添加FEC也可以较好的控制误码率,具有功耗低、面积小、通信协议灵活的特点,适合在具有端到端FEC的光学设备和裸芯片之间部署。
- USR SerDes主要致力于通过2.5D/3D封装技术在超短距离(10mm级别)上实现芯片对芯片的高速互连通信。由于通信距离短,USR通过高级编码,多位传输和其他技术提供了更好的性能、功耗比和更好的可伸缩性。USR SerDes互连技术的发展大大减少了半导体芯片之间通信所需的I/O总数。但USR对传输距离的要求又阻碍了Chiplet的大规模集成。
与传统的SerDes技术应用场景不同,面向Chiplet的互连在一个封装体内完成,其传输距离要小很多。在短距离的互连中,信号在传输线中的衰落减少,因此应用在Chiplet之间互连的SerDes电路中,可以简化均衡电路的设计,在一定传输速率下甚至不需要均衡电路,从而可以降低每比特的传输能耗。由于互连信号质量的改善,Chiplet间的低摆幅传输可以用单端方式代替差分传输,从而提高互连线的利用率。也可以使用 n + i 条互连线来传递 n 比特数据的编码方式,实现传输带宽和能耗的优化,如基于CNRZ编码的SerDes互连接口。
在传统SerDes中,时钟信号一般融合在数据传输中,在接收电路中通过时钟恢复电路(CDR)恢复出时钟,并根据恢复得到的时钟实现数据的同步,其中的时钟恢复电路会增加电路设计的复杂性和接收功耗。Chiplet集成的互连环境中,信号同步要求降低,时钟信号可以采用独立传输、恢复和共享,从而减少每条互连通路的时钟恢复电路开销,如图3所示。图3中,FFE、DFE/CTLE电路的设计可以简化,这可以降低传统SerDes收发电路的复杂度,从而实现高速低能耗的传输。
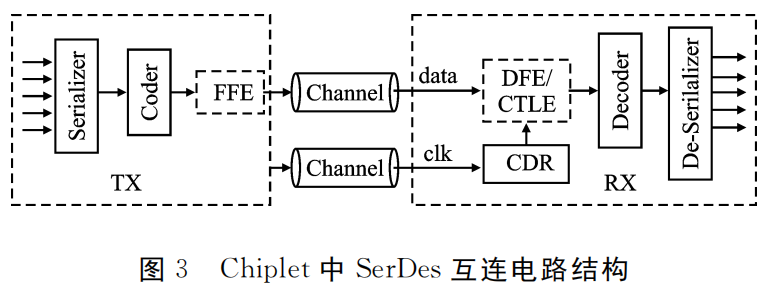
二、并行互连
在串行互连的基础上,各大公司技术联盟提出了基于并行数据传输的物理层互连技术。
HBM (High Bandwidth Memory) 是已经被广泛接受的高带宽存储器,其数据IO数达到1024比特,HBM接口也是Chiplet集成中最常见的一种并行接口。除了HBM接口以外,目前还有如Intel的AIB/MDIO、ODSA的BoW和TSMC的LIPINCON等不同的并行接口用于Chiplet之间的并行互连。
- AIB/MDIO:AIB是英特尔推出的一种在Chiplet之间传输数据的接口方案和互连标准,是市场上为数不多的开放接口之一。多年来,英特尔一直在生产带有AIB接口的产品,在其Stratix 10 FPGA上就使用了AIB接口来集成多种不同的小芯片。作为AIB的升级版本,MIDO提供了更高的传输效率,并且响应速度和带宽密度是AIB的两倍以上。AIB和MDIO技术主要适用于通信距离短,损耗低的2.5D和3D封装技术,例如EMIB、Foveros。
- LIPINCON:LIPINCON是台积电多年前就开始研发的裸片之间数据互联接口技术,通过使用先进的基于硅的互连封装技术(例如InFO、CoWoS)和时序补偿技术,为Chiplet提出的高性能互连接口。LIPINCON可以在没有PLL/DLL的情况下降低功耗和占用面积。LIPINCON接口包含两种类型的PHY:PHYC和PHYM,分别用于SoC芯片和存储器/收发器芯片。
- BoW:ODSA正在定义一个名为Bunch of Wires (BoW)的芯片到芯片接口。BoW接口专注于解决基于有机基板的并行互连问题,BoW有BoW Base,BoW-Fast和BoW-Turbo三种类型,支持不同的传输距离和传输效率。此外,BoW支持向后兼容,并且对芯片工艺和封装技术的限制较少,不依赖于先进的基于硅的互连封装技术,具有广泛的应用范围。
当然,供应商需要的不止一种芯片到芯片互连方案。除了上述提到的几种,其他互连技术也正在研发中,行业厂商在纷纷布局:
- Marvell在推出模块化芯片架构时采用了Kandou总线接口;
- AMD推出的Infinity Fabric总线互联技术,以及用于存储芯片堆叠互联的HBM接口;
- Xilinx正在开发OpenHBI,一种源自HBM标准的片间互连/接口技术;
- Momentum 正在推动铜混合键合,使用微小的铜对铜连接来连接封装中的芯片;
- NVIDIA推出的用于GPU的高速互联NVLink方案;
- 光互连论坛正在开发一种称为CEI-112G-XSR的技术,为小芯片实现高速传输的芯片到芯片连接;
- 国内方面,也有厂商在此展开动作。芯动科技推出了国产自主标准的INNOLINK Chiplet IP和HBM2E等高性能计算平台技术,支持高性能CPU/GPU/NPU芯片和服务器
这些都是产业链企业在致力Chiplet实现高速互联上的不同尝试。
Chiplet中并行接口的结构如图4所示。并行互连接口中,发送端发送一组数据和想对应的时钟信号,接收端收到时钟信号后,基于DLL等电路对于时钟信号进行恢复和相位调整后,发送到接收电路,用于并行数据的同步和采样。由于时钟信号对并行接口非常关键,一般采用差分传输以提高时钟信号的传输质量。
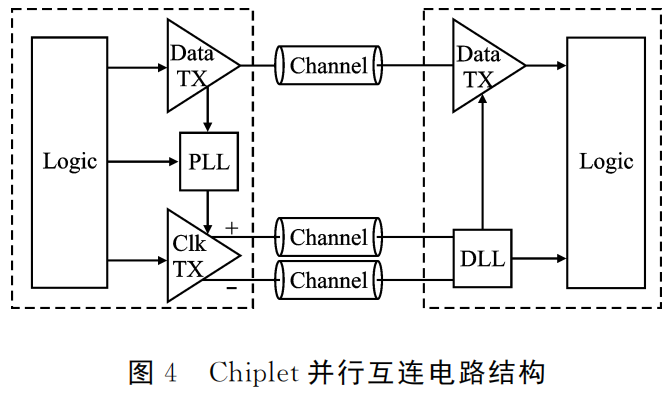
三、串行与并行互连的比较
Chiplet之间互连的性能指标通常包括传输距离、传输能耗、传输带宽及带宽密度等。根据以上性能指标,当前主要的Chiplet串行互连和并行互连总线接口性能总结如表1所示。
串行互连与并行接口相比,适应距离更远的传输,其每比特的传输能耗更大,传输延时也更大。串行互连电路的设计难度大,但更容易在成本较低的有机基板上实现高性能的传输,制造成本更低。
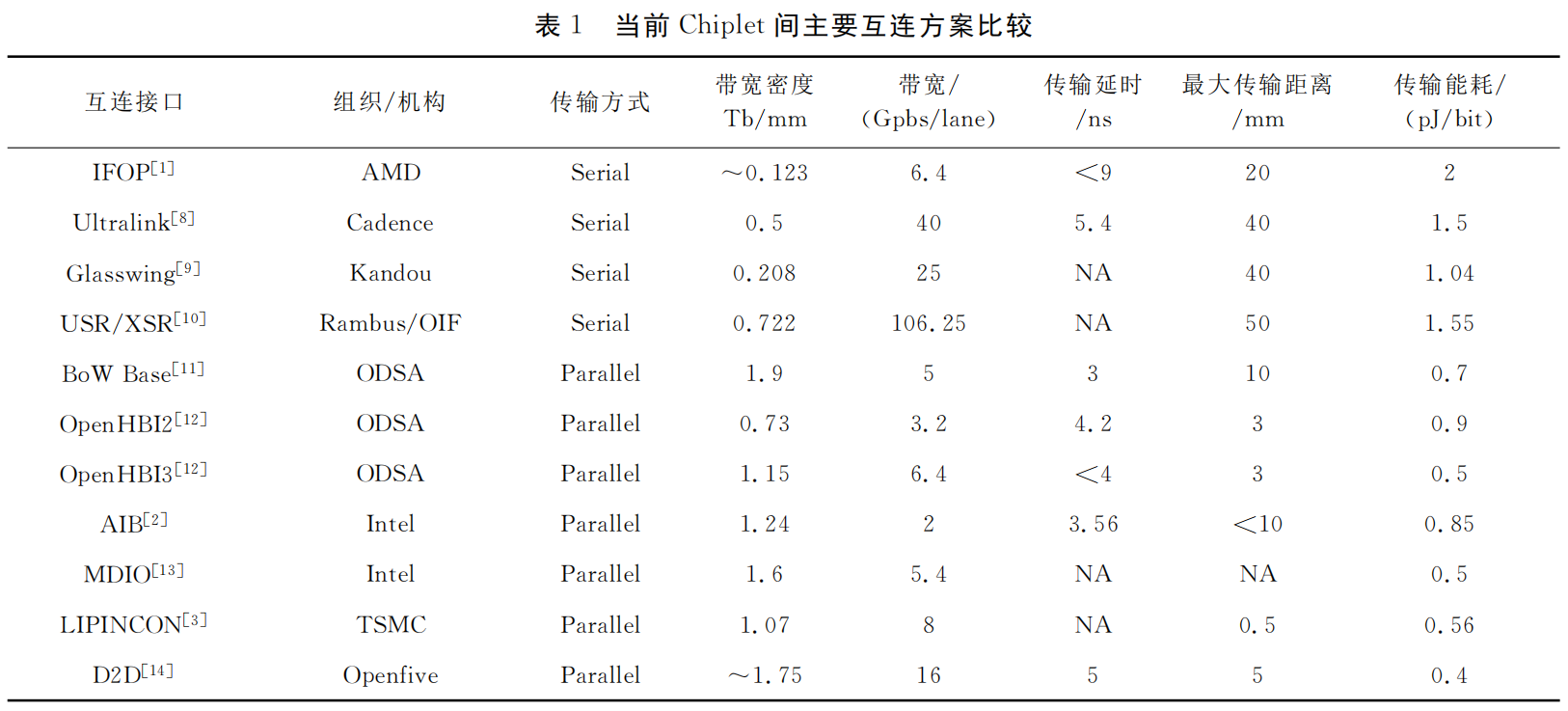
并行接口的互连密度高,一般需要在硅基板上实现,封装成本更高,并行信号之间存在较严重的干扰和信号完整性问题,每个IO的传输速率受到限制。其优点是设计复杂度低,每比特的传输能耗更低。传输延时小,尤其适合作为对于访问延时要求较高的存储类接口。
尽管表1中的互连电路提供了高速低功耗的解决方案,但与片上互连小于100fJ/bit/mm的传输能耗和大于10Tb/mm带宽密度相比,仍然存在一定的性能差距。Chiplet间的高速低功耗互连电路仍然有很大的性能提升空间。
四、互连标准接口
(1)背景
表1各种互连总线接口,不管是串行或者并行接口,相互之间并不兼容,Chiplet之间的互连尚缺乏一个广泛被接受的接口总线标准,这对于Chiplet技术的推广和使用形成一定的挑战。虽然Intel的AIB总线,ODSA的BoW总线,或者OIF的USR和XSR都可以作为Chiplet之间的互连标准,这些标准化工作在很大程度上局限于片间通信的物理层协议。在实际应用中,在物理层协议之上,往往还需要定义如数据链路、传输层和应用层等,使互连标准能够满足各种高速数据传输应用和数据一致性的需求。
即使在物理层,并行互连总线和串行互连总线属于不同的技术路线,电路实现方式差异较大,如果总线接口标准能够实现串行与并行互连的融合,更加有利于标准的推广。此外,HBM已经是现实上的一个标准接口,新的互连总线标准,能否兼容HBM当前与未来的版本,并在修改配置的情况下支持DDR,LVDS等广泛使用的接口,也将影响其通用性。在没有一个行之有效的标准之前,采用AIB或者常用的接口如串行的PCIe接口进行Chiplet设计,也是推动Chiplet技术往前走的一种可能的选择,尽管这些协议的互连性能受到一定的限制,并不能充分发挥Chiplet技术的潜在优势。
(2)UCIe
2022年三月份出现的UCIe, 即Universal Chiplet Interconnect Express,是Intel、AMD、ARM、高通、三星、台积电、日月光、Google Cloud、Meta和微软等公司联合推出的Die-to-Die互连标准,其主要目的是统一Chiplet(芯粒)之间的互连接口标准,打造一个开放性的Chiplet生态系统。UCIe在解决Chiplet标准化方面具有划时代意义。UCIe可同时支持2.5D、3D封装技术,例如MCM、晶圆级封装(CoWoS)、EMIB等。
UCIe 1.0 使用成熟的高速串行计算机扩展总线标准(PCIe) 和计算机互连标准 (CXL) 作为低功耗的裸片到裸片 (D2D) 互连物理层 (PHY),可兼容多个协议,包括PCIe、CXL和Raw Mode。同时UCIe支持UCIe Retimer。这样UCIe就能够把互连的结构延伸到封装外。UCIe Retimer一端采用UCIe协议,另外一端采用CXL协议,这样可实现从封装内互连到封装外互连的巧妙转换。
到目前为止,已经成功商用的Die-to-Die互连接口协议多达十几种,主要分为串行接口协议和并行接口协议。串行接口及协议有LR、MR、VSR、XSR、USR、PCIe、NVLink(NVIDIA),用于Cache一致性的CXL、CCIX、TileLink、OpenCAPI等;并行接口及协议有AIB/MDIO(Intel)、LIPINCON(TSMC)、Infinity Fabric(AMD)、OpenHBI(Xilinx)、BoW(OCP ODSA)、INNOLINK(Innosilicon)等。比较而言,串行接口一般延迟比较大,而并行接口可以做到更低延迟,但也会消耗更多的Die-to-Die互连管脚;而且因为要尽量保证多组管脚之间延迟的一致,所以每个管脚不易做到高速率。
具体的关于UCIe互连标准的解读,参照:
深度解读Chiplet互连标准UCIe - 知乎 (zhihu.com)
综合来看,这套标准可以使不同制造商的小芯片实现互通,即允许不同厂商的芯片进行混搭。不同于之前的业界并口标准,UCIe是一套完整的全栈协议,具有互操作性,并与现有的行业标准兼容,同时未来还将支持3D封装。此外,由于协议制定单位均为业界龙头公司 (涵盖制造、设计、应用等领域),UCIe在未来极有可能成为行业统一的标准。Intel推出该标准的目的在于建立以CPU为中心的计算生态环境。此外,NVIDIA于2022年8月宣布加入UCIe组织。Intel曾表示,未来至关重要的是一个开放的小芯片生态系统。对此,主要行业合作伙伴应共同努力,改变行业交付新产品的方式,以实现摩尔定律设定的共同目标。
参考资料:
Chiplet封装结构与通信结构综述_陈桂林
Chiplet关键技术与挑战_李乐琪
深度解读Chiplet互连标准UCIe - 知乎 (zhihu.com)
这将是Chiplet的最大挑战?|amd|芯片|serdes|并行接口|存储器_网易订阅 (163.com)





 京公网安备 11010802041100号
京公网安备 11010802041100号