作者:章小胭 | 来源:互联网 | 2024-10-28 19:52
在进行SQL字符串操作时,经常会用到`instr`、`substr`和`like`函数。本文详细解析了这些函数的应用场景和区别。特别是`like`函数在处理文件路径匹配时可能会遇到的问题,如通配符`_`和`%`的使用。其中,`%`可以匹配零个或多个任意字符,而`_`则匹配任意单个字符。通过实例和文档解析,帮助读者更好地理解和应用这些函数。
前言
最近做测试时发现 SQLite like 匹配文件路径有时会有问题,查文档才知道是没有处理 like 字符串中的通配符 _ 下划线和 % 百分号。% 匹配零个及多个任意字符; _ 与任意单字符匹配,如:
select filepath from table where filepath like 'D:/#/123%/%';
本来是想查找文件夹 123% 下的文件,但百分号被识别为了通配符,结果可能是:
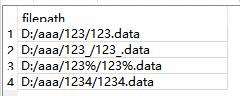
这时候有几种替代选择,使用 instr 来匹配,或者 like 语句加 escape 转义,substr 截取判断等。但是还要注意不同的数据库支持的 SQL 语句有区别,需要查对应的数据库参考,我主要是以 SQLite 进行测试。
--instr = 1 表示以搜索的字符串打头
select filepath from table where instr(filepath,'D:/#/123%/')=1;
--escape '\' 表示转义字符 '\' 后面的 % 或 _ 就不作为通配符了
select filepath from table where filepath like 'D:/#/123\%/%' escape '\';
--SQLite substr用于截取字符串,这里从第一个字符截取相同长度进行比较
select filepath from table where substr(filepath,1,length('D:/#/123%/'))='D:/#/123%/';instr函数
instr 函数是一个字符串处理函数,返回子字符串在源字符串中的位置,如果在源串中没有找到子串,则返回0。
SQLite 中的定义(MYSQL类似):
instr( X , Y )
instr(X,Y) 函数查找字符串 X 中第一次出现的字符串 Y 并返回先前字符数加 1,如果在 X 中找不到 Y,则返回 0。或者,如果 X 和 Y 都是 BLOB,则 instr (X,Y) 返回比第一次出现 Y 之前的字节数多一个字节,如果 Y 不在 X 内的任何位置出现,则返回 0。如果 instr(X,Y) 的参数 X 和 Y 都不是 NULL 并且是不是 BLOB,则两者都被解释为字符串。如果 instr(X,Y) 中的 X 或 Y 为 NULL,则结果为 NULL。
Oracle/PLSQL 中的定义:
instr( str, substr[, position [, appearance ] ] )
返回子字符串在源字符串中的位置(字符串位置从1开始,而不是从0开始)
str 源字符串
substr 子字符串
position 检索位置,可省略(默认为1),参数为正时,从左向右检索,参数为负时,从右向左检索
occurrence 检索子串出现次数(即子串在源串第几次出现),可省略(默认为1),值只能为正整数,否则会报错
示例
--下列语句结果:3
SELECT INSTR('hello world', 'l') FROM DUAL;
--下列语句结果:10 (从左向右第5位开始检索'l'在'hello world'中出现的位置)
SELECT INSTR('hello world', 'l', 5) FROM DUAL;
--下列语句结果:10 (从右向左第1位开始检索'l'在'hello world'中出现的位置)
SELECT INSTR('hello world', 'l', -1) FROM DUAL;
--下列语句结果:4 (从左向右第2位开始检索'l'在'hello world'中第2次出现的位置)
SELECT INSTR('hello world', 'l', 2, 2) FROM DUAL;
--下列语句结果:0 (从右向左第3位开始检索'l'在'hello world'中第3次出现的位置)
SELECT INSTR('hello world', 'l', -3, 3) FROM DUAL; substr函数
substr 的功能为截取字符串子串
SQLite 中的定义:
substr( X , Y , Z )
substr( X , Y )
substring( X , Y , Z )
substring( X , Y )
substr(X,Y,Z) 函数返回输入字符串 X 的子字符串,该子字符串以第 Y 个字符开头,长度为 Z 个字符。如果省略 Z,则 substr(X,Y) 返回从第 Y 个开始到字符串 X 末尾的所有字符。X 最左边的字符是数字 1。如果 Y 是负数,则通过从右侧而不是左侧开始计数来找到子字符串的第一个字符。如果 Z 为负,则返回第 Y 个字符之前的 abs(Z) 字符。如果 X 是字符串,则字符索引指的是实际的 UTF-8 字符。如果 X 是 BLOB,则索引指的是字节。
从 SQLite 3.34 版开始,“substring()”是“substr()”的别名。
--以filepath字段第一个字符截取相同长度进行比较
select filepath from table where substr(filepath,1,length('D:/#/123%/'))='D:/#/123%/';like操作符
like 操作符可在 where 子句中搜索指定内容,一般搭配通配符 _ 和 % 进行模糊查询。其中 % 百分号代表零个或多个字符,_ 下划线代表单个字符。
如果要查的字符串包含 % 或者 _ 怎么办呢?使用 escape 转义,转义字符后面的 % 或 _ 就不作为通配符了,但也要考虑被转义的字符是否会出现在字符串中。
--在STUDENTTAB表中查询STUNAME中含有字符“张”的学员
SELECT * FROM STUDENTTAB WHERE STUNAME LIKE '%张%';
--在STUDENTTAB表中查询STUNAME中以“张”开头,名字长度为2的学员(即“张三”、“张四”,而不会检测出“张三三”)
SELECT * FROM STUDENTTAB WHERE STUNAME LIKE '张_';
--可以正确识别字符串中百分号
select filepath from table where filepath like 'D:/#/123\%/%' escape '\';
instr(title,'手册')>0 相当于 title like '%手册%'
instr(title,'手册')=1 相当于 title like '手册%'
instr(title,'手册')=0 相当于 title not like '%手册%'
instr 与 like 比较
- instr>0 和 like、instr=0 和 not like 一般来说查询的结果相同(不考虑特殊字符)。
- instr 是一个函数,可以建立函数索引,如果过滤的条件有索引,那么 instr 就可以提高性能。
- like 查询时,以 ‘%’ 开头,列所加的索引是不起作用的。
- 在没有索引的前提下,当数据量比较大时,instr 要比 like 效率高。
参考
SQLite 文档:https://www.sqlite.org/lang_corefunc.html
博客 instr 与 like 区别:https://blog.csdn.net/lanmuhhh2015/article/details/79216804









 京公网安备 11010802041100号
京公网安备 11010802041100号