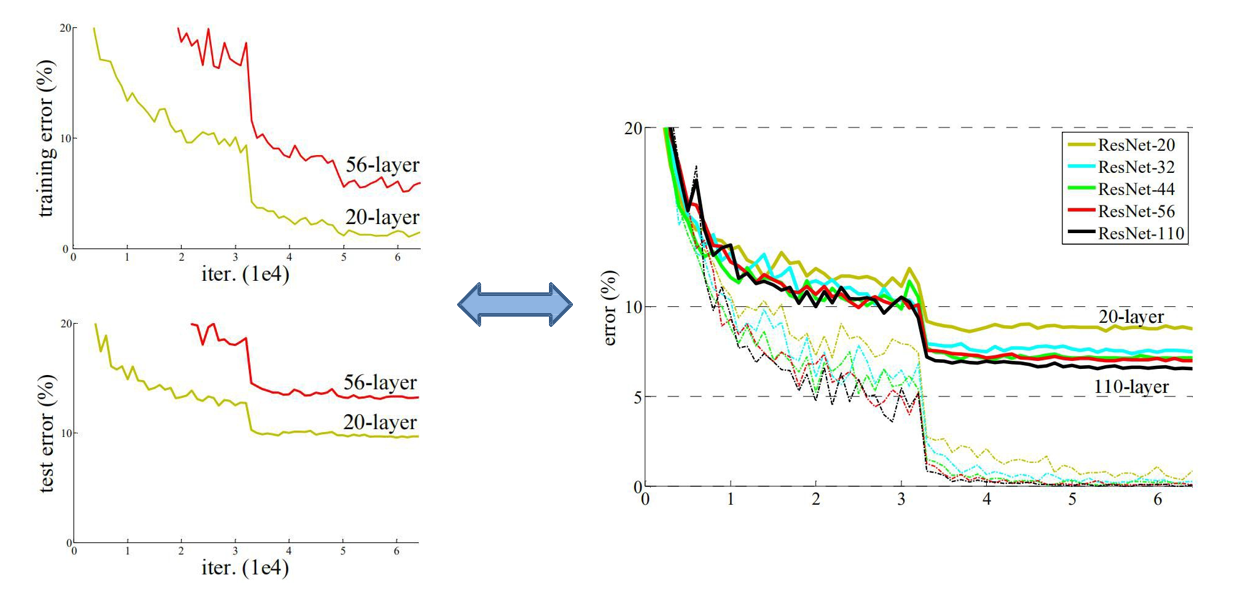
网络简单堆叠存在的问题
网络简单堆叠和resNet网络错误率的比较。 右图实线为验证集错误率,虚线为训练集错误率
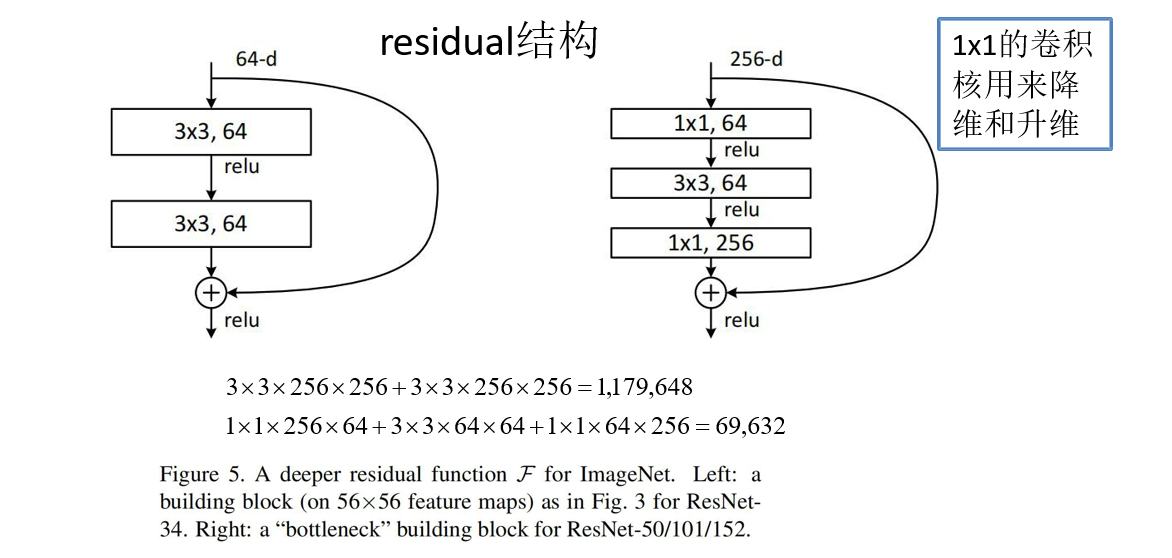
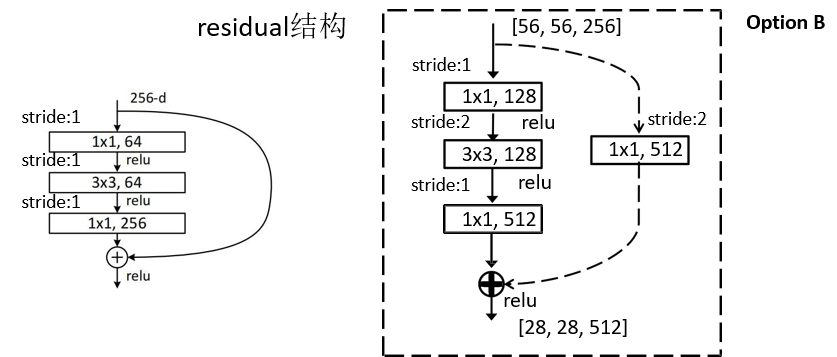
有两种残差结构 注意: 主分支与侧分支的输出特征矩阵需要相加,故两者shape必须相同
对左边残差结构的理解
对右边残差结构的理解
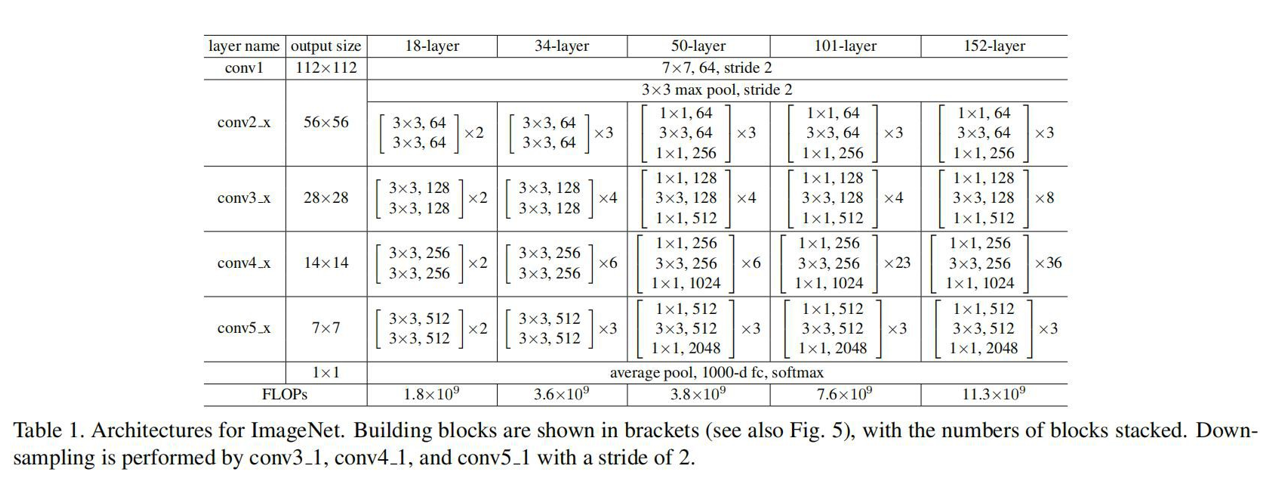
ResNet参数列表: 不同的残差结构(实线残差结构、虚线残差结构)
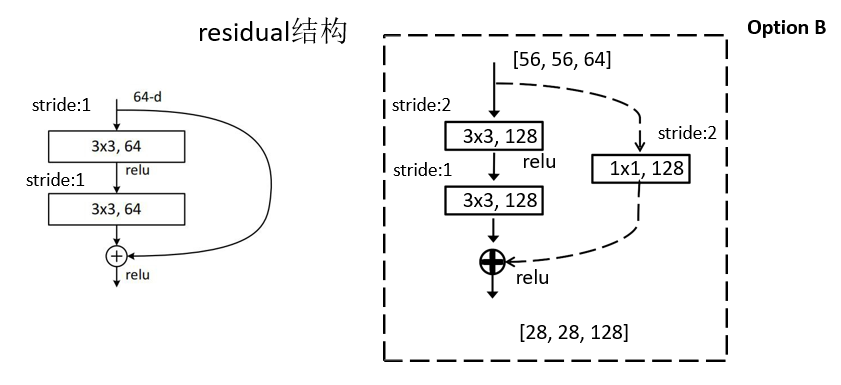
实线残差结构是由于:输入特征矩阵和输出特征矩阵能够直接相加
虚线残差结构:输入特征矩阵和输出特征矩阵不能直接相加,输入特征矩阵需要经过侧分支的128个1∗11*11∗1卷积核才能与主分支的输出特征矩阵相加
对于残差结构图中的侧分支有些是实线有些是虚线的解释
BN更详细的看这篇:Batch Normalization详解以及pytorch实验
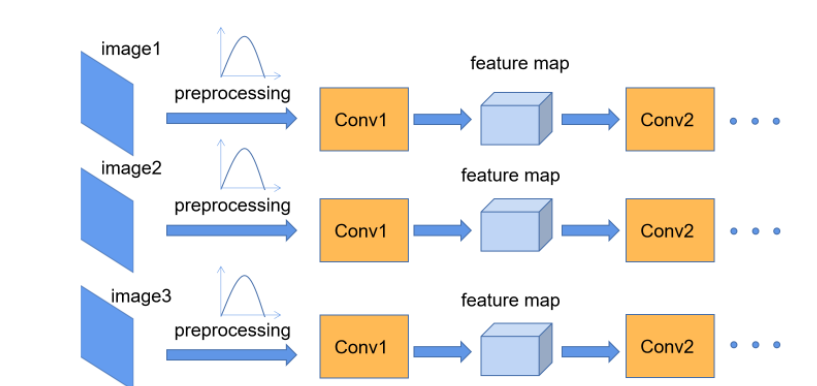
CNN中的feature map介绍 Batch Normalization的目的:使一批(batch)特征矩阵feature map每个channel对应的维度满足均值为0,方差为1的分布规律,通过该方法能够加速网络的收敛并提升准确率 在图像预处理过程中通常会对图像进行标准化处理,以加速网络的收敛。对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了
(注意这里所说满足某一分布规律并不是指某一个feature map的数据要满足分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律)。
而我们Batch Normalization的目的就是使我们的特征层feature map满足均值为0,方差为1的分布规律。
使用BN应注意的问题
1. 能够快速训练出来一个理想的结果 2. 当训练集较小时也能训练出理想的效果
注意 :使用别人预训练模型参数时,要注意与别人的预处理方式保持一致
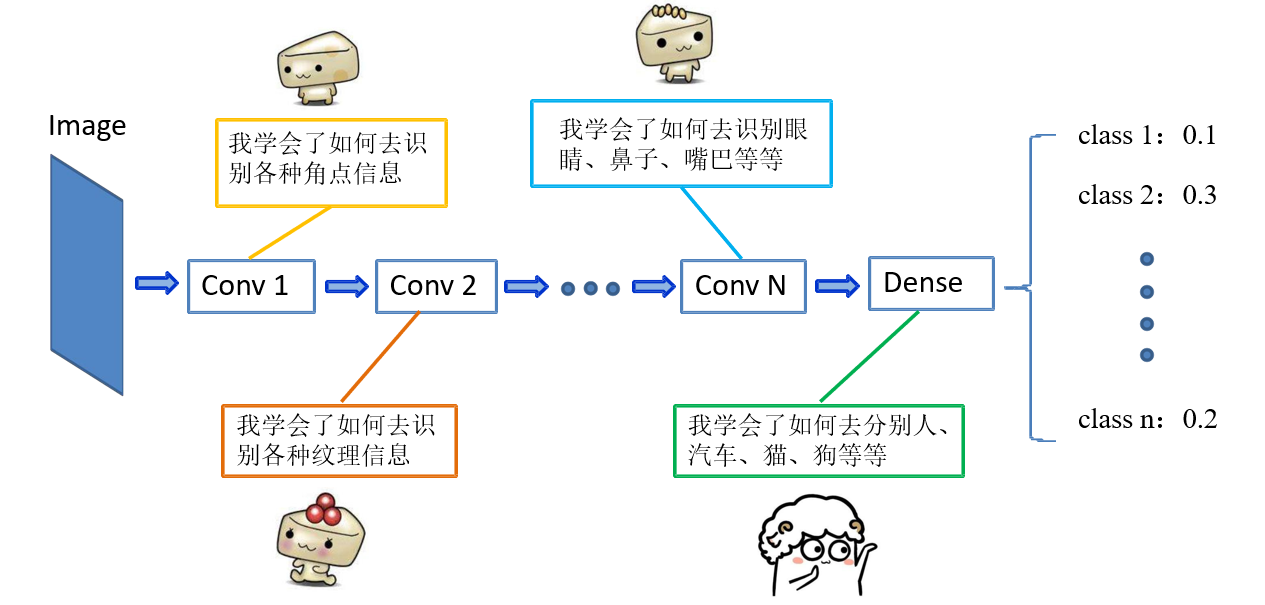
浅层卷积层学习到的角点、纹理信息是较为通用的信息,这些信息不仅在本网络中使用,同时可以迁移应用到其他网络,即迁移。 浅层网络的参数迁移到新网络,则新网络也拥有了识别角点、纹理等通用特征的能力,新网络就能够更加快速的学习新的数据集的高维特征
硬件有限或对时间有要求选择第2、3种迁移学习方式
由于训练集的最后一层的分类个数可能和原预训练模型的参数不一致,采用第一种方式时,最后一层无法载入模型参数;但若采用第三种迁移学习方式,由于又添加了一层全连接层,最后一层模型参数可以载入,新添加的全连接层的结点个数即训练集的分类个数,仅训练最后一个全连接层即可。
花分类实例参考这篇:使用pytorch搭建ResNet并基于迁移学习训练

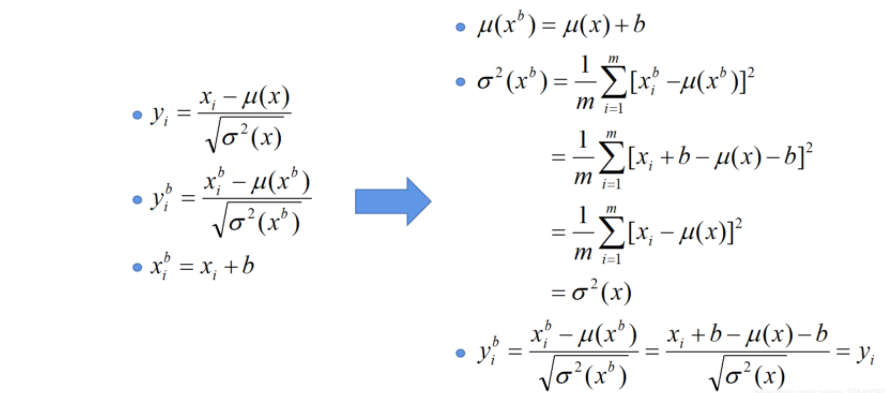










 京公网安备 11010802041100号
京公网安备 11010802041100号